
Welche:r Produktverantwortliche kennt es nicht? Das Product Backlog des eigenen Jira-Projekts gleicht einem unordentlicher Keller, in dem noch Kartons liegen, von denen niemand mehr den Inhalt kennt und nur noch ausgewählte Stellen mit Ordnung gesegnet sind.
Da ein aufgeräumtes Backlog Übersicht schafft, die Priorisierung erleichtert und den Fokus auf konkrete Fragestellungen erleichtert, macht es Sinn, das Backlog von Zeit zu Zeit aufzuräumen.
Hier leisten interaktive Dashboards erhebliche Unterstützung, indem sie Möglichkeiten aufzuzeigen, wie das Backlog aussortiert und systematisch abgearbeitet werden kann.
Was ist ein Product Backlog?
In Jira-Projekten werden zukünftige Arbeitsaufträge im Product Backlog gesammelt. Dabei dient das Backlog häufig nicht nur als Sammlung unbedingt umzusetzender Anforderungen, die von dem:der Projektverantwortlichen gefordert werden, sondern auch als Ideensammlung des Teams, in dem auch spontane Verbesserungsvorschläge gesammelt werden.
Dies führt häufig dazu, dass das Backlog sehr umfangreich und somit über die Zeit unübersichtlich wird. Dies kann zum einen zur Folge haben, dass der Status der Issues nicht mehr gepflegt wird, und Issues, die im Rahmen von anderen Issues mit umgesetzt wurden, nicht mehr auf 'Done' gestellt werden oder zum anderen, dass im Backlog noch Issues mit Ideen liegen, deren Umsetzung bereits nicht mehr wünschenswert ist, da sich zum Beispiel die Ausrichtung des Projekts geändert hat.
Um wieder Ordnung zu schaffen, stellen sich Projektverantwortliche häufig folgende Fragen:
- Was ist die grobe Struktur der Issues in meinem Projekt und dessen Backlog - also zu welchen Themenbereichen gibt es Issues?
- Welche Issues sind doppelt oder ähnlich und sollten fusioniert werden oder mit Abhängigkeiten zu anderen Issues versehen werden, um Synergieeffekte bei der Bearbeitung zu nutzen?
- Welche Issues sind veraltet oder bereits im Rahmen eines anderen Issues erledigt worden?
- Wie viele Issues haben eine:n Bearbeiter:in? Ist diese:r Bearbeiter:in sinnvoll oder passt das Issue eigentlich besser zu einem anderen Bearbeitenden?
Um diese Fragen zu beantworten, finden sich viele nützliche Informationen versteckt in den Jira Issues. Diese Informationen können im Rahmen von gezielten Analysen automatisch ausgelesen werden und in interaktiven Dashboards aufbereitet dargestellt werden, die mit einer Vielzahl von Tools - unter anderem PowerBI oder Python - erstellt werden können. Dann können gezielt Filter, auf bestimmte Themen, Sprints oder Typen von Issues gesetzt werden, um so einen schnellen Überblick zu geben und potentiell interessante Issues sind leicht explorativ zu identifizieren.
Grobe Struktur der Issues im Projekt und im Backlog
Beim Aufräumen des Backlogs hilft es, sich zuerst eine grobe Übersicht über das gesamte Projekt verschaffen (Gesamtanzahl der Issues, die Anzahl der offenen Issues und die Anzahl der offenen Epics).
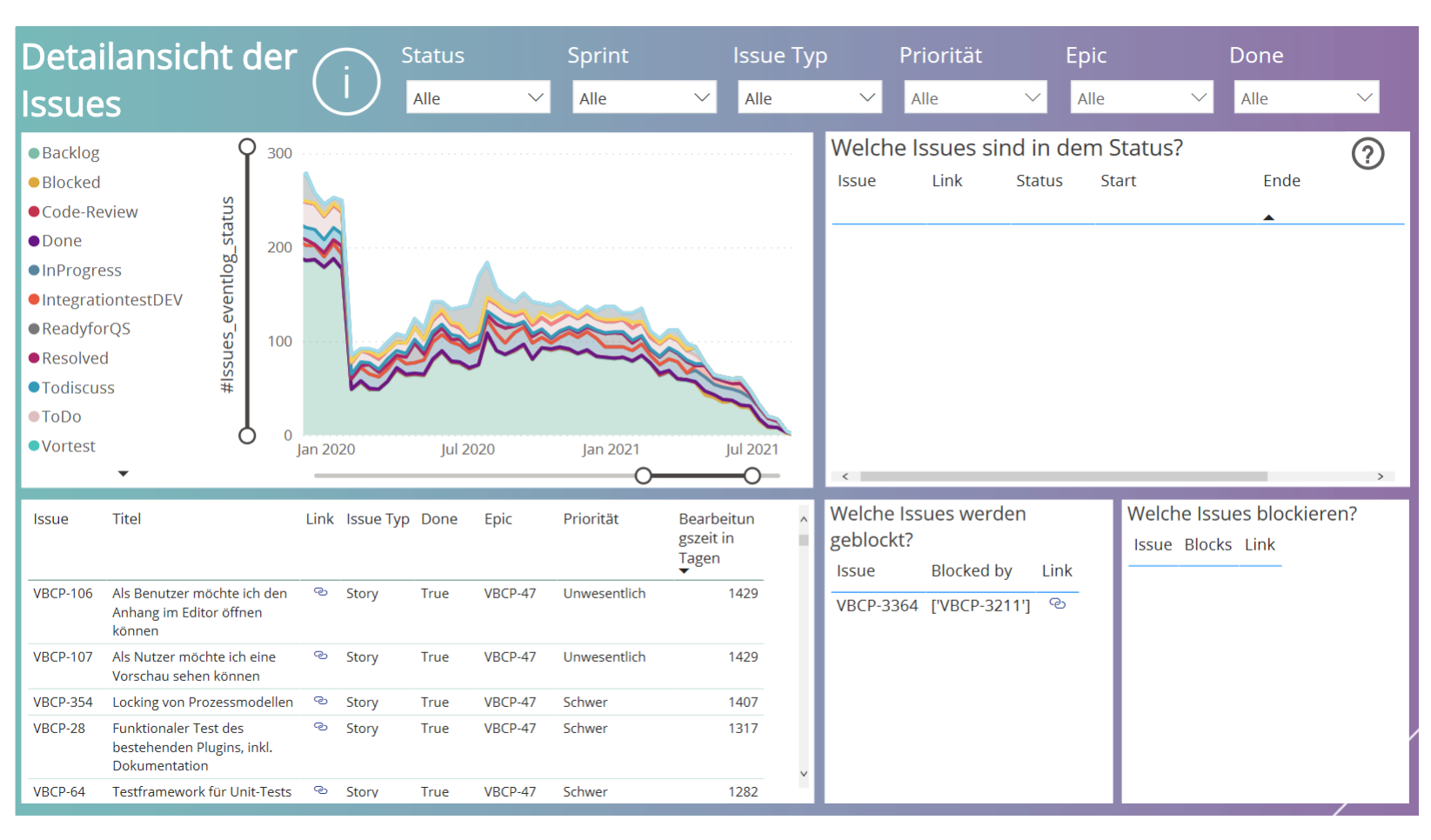
 Bild 1: Grobübersicht 'Projekt'
Bild 1: Grobübersicht 'Projekt'
Danach lohnt sich ein gezielter Blick auf das Backlog:
- Wie viele Issues liegen im Backlog?
- Wie viele davon sind Bugs?
- Was sind die ältesten Issues und was ist das Durchschnittsalter der Issues im Backlog?
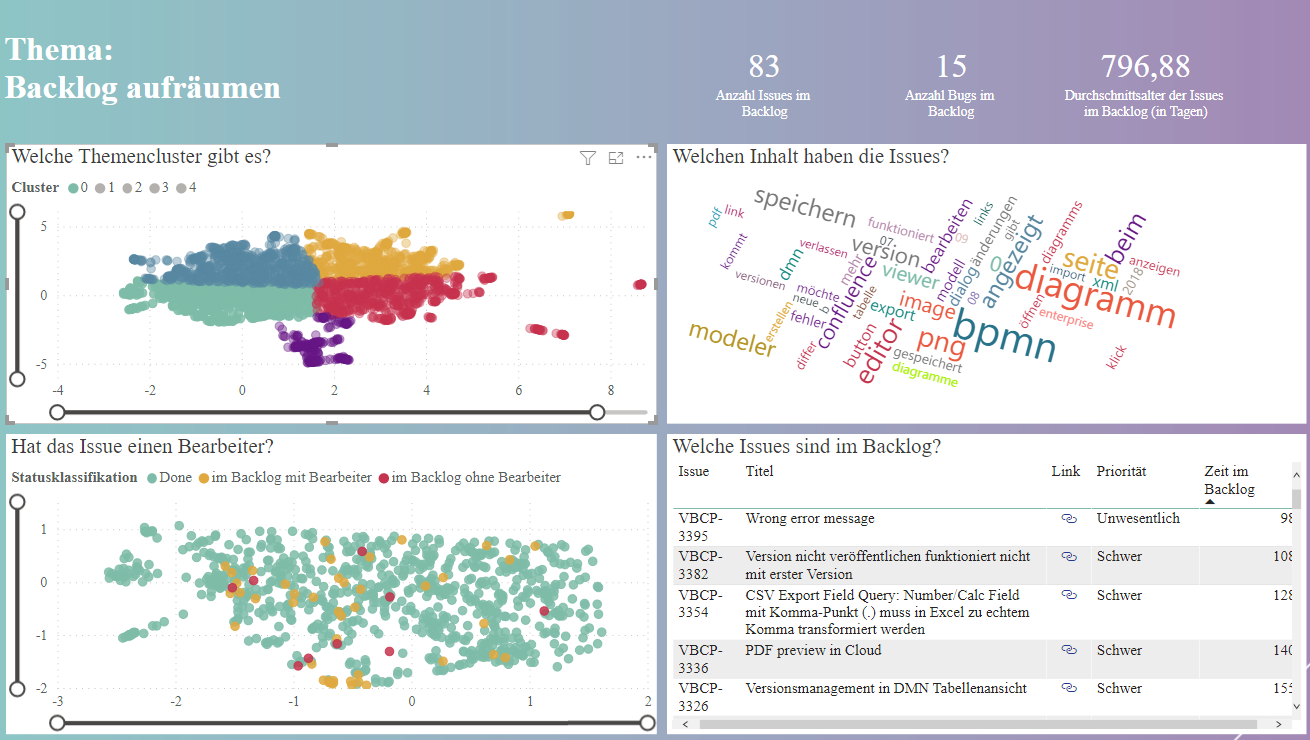
Bild 2: Grobübersicht 'Backlog'
Ähnliche und doppelte Issues mit Clustering auffinden
Beim Aufräumen des Product Backlogs ist es unserer Erfahrung nach sinnvoll, sich die Frage zu stellen, welche offenen Issues doppelt vorhanden oder zueinander ähnlich sind. Diese Issues sollten herausgefiltert und bei Bedarf fusioniert werden oder mit Abhängigkeiten zueinander versehen werden, um Synergieeffekte bei der Bearbeitung auszunutzen.
Dafür können die Issues anhand ihres Inhaltes (Titel, Beschreibung, Kommentare, Typ) in einer 2D-Issue-Landschaft angezeigt werden. Dabei werden die einzelnen Issues durch einen Punkt dargestellt und ähnliche Issues liegen dann nah beieinander (dies kann z. B. mit der Methode 'UMAP' erreicht werden). Danach kann der Algorithmus die Issues in Cluster von Issues mit ähnlichen Themen aufteilen und diese als interaktive Webanwendung darstellen, in der Issues in demselben Cluster mit derselben Farbe visualisiert werden. In einem solchen interaktiven Dashboard kann der Nutzer dann durch Hovern über die Punkte/Issues einzelne Issues identifizieren und genauer betrachten und vergleichen.
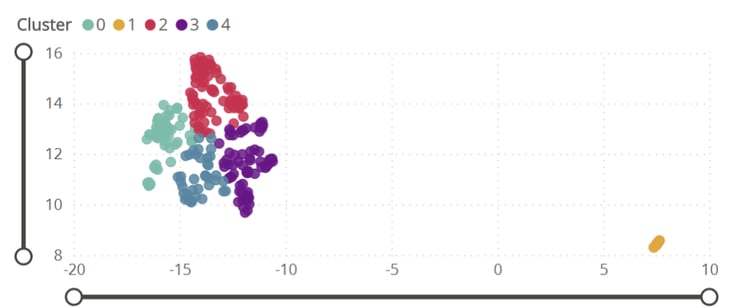 Bild 3: Themencluster innerhalb der 2D-Issue-Landschaft
Bild 3: Themencluster innerhalb der 2D-Issue-Landschaft
Doch wie zeichnen sich diese ähnlichen Issues, die demselben Cluster zugeordnet wurden, aus? Zu dieser Frage können automatisch erzeugte Wortwolken Aufschluss geben. In diesen Wortwolken finden sich Wörter und somit auch konkrete Themen, die in diesen Issues vorkommen. Je häufiger das Wort im Issue vorkommt, desto größer wird es dargestellt. So werden schnell die gemeinsamen Themen der Cluster klar.

Bild 4: Wortwolke mit Themen innerhalb eines Clusters
Dann können in der 2D-Issue-Landschaft nah beieinander liegende Issues mit Abhängigkeiten versehen werden oder doppelte Issues geschlossen werden.
Auffinden von veralteten und bereits erledigten Issues
In einem letzten Schritt lohnt es sich, veraltete und im Rahmen von anderen Issues bereits erledigte Issues ausfindig zu machen.
Der größte Indikator für das Auffinden von bereits veralteten Issues ist dabei natürlich die Dauer des Issues im Product Backlog. Vielleicht liegen in Ihrem Backlog ja noch Issues, die vor langer Zeit erstellt wurden und mittlerweile nicht mehr relevant sind, da sich das Projekt in eine andere Richtung entwickelt hat?
Um bereits erledigte Issues schneller aufzuspüren, lohnt sich ebenfalls ein Blick auf die 2D-Issue-Landschaft. Hier könnte ein Dashboard Issues mit Status 'Im Backlog' in einer anderen Farbe darstellen als die Issues im Status 'Done'. Wenn dann zwei Issues A und B nebeneinander liegen, wobei Issue A den Status 'Done' und B den Status 'im Backlog' hat, ist B vielleicht auch schon indirekt durch dieses andere Issue mitabgearbeitet worden.
Finden von passenden Bearbeiter:innen
Auch hier lohnt sich ein Blick auf eine 2D-Issue-Landschaft. Vielleicht liegen dort zwei Issues A und B nebeneinander, wobei Issue A den Status 'Done' hat und Issue B den Status 'im Backlog' hat und noch kein:e Bearbeiter:in zugewiesen ist.
Dann kann ein:e sinnvolle:r Bearbeiter:in für Issue B gefunden werden, indem man Issue B derselben Person wie Issue A zuweist, da diese schon entsprechende Vorerfahrungen hat – oder falls das Issue schon eine:n Bearbeiter:in hat, einer anderen passenderen Person zugewiesen werden.
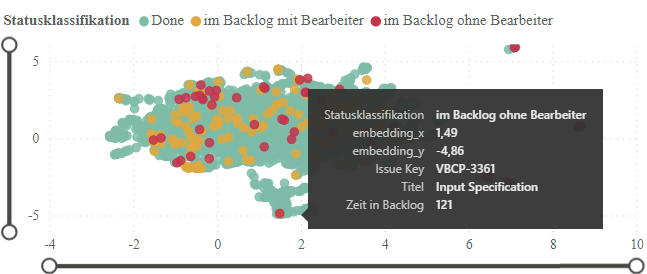
Bild 5: Haben Issues einen Bearbeiter? Durch Hovern über das Issue werden mehr Informationen zu dem Ticket angezeigt, die mit den Informationen der naheliegenden Tickets verglichen werden können.
Wie erfolgreich war das Aufräumen?
Nach Abschluss der Aufräumarbeiten lässt sich die Effizienz des Aufräumens u. A. durch folgende Qualitätsmerkmale mit Hilfe des Dashboards automatisch bewerten:
- Sind nach dem Aufräumen mehr Issues als vorher vom Status 'im Backlog' direkt in den Status 'Done' gewandert (Stichwort Process Mining)? In diesem Fall gab es viele Issues, die obsolet oder doppelt waren und das Aufräumen war an dieser Stelle effektiv.
- Gibt es weniger Issues ohne Bearbeiter:in als vorher, weil bei vielen Issues naheliegende Bearbeiter:innen gefunden wurden?
- Wurden im Rahmen des Aufräumens Issues einem anderen Person zugewiesen, um Missmatching zwischen Bearbeiter:innen und Issues zu minimieren?
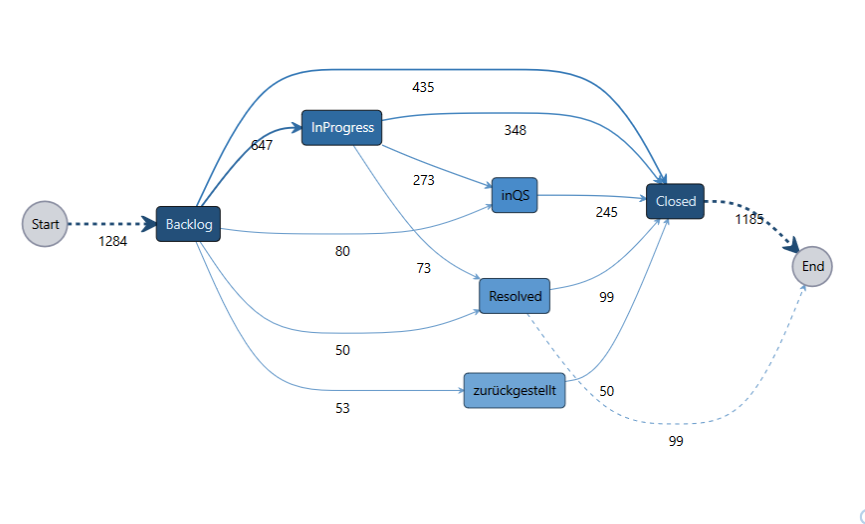 Bild 6: Prozessmodel 'Process Mining' zur Analyse der Statusabfolge der Issues
Bild 6: Prozessmodel 'Process Mining' zur Analyse der Statusabfolge der Issues
Fazit
Beim Erproben der Ideen mit unseren internen Teams stellte sich heraus, dass der Austausch und das gemeinsame Interpretieren der Grafiken einen großen Wert hat und hilft, die eigene Priorisierung und die Abläufe dazu besser zu verstehen oder in Frage zu stellen.
Laden Sie uns gern einmal zu einer datenbasierten Retrospektive Ihres Projekts ein und lassen Sie sich mit Dashboards beim Aufräumen des Backlogs helfen. Einen automatischen Staubsaugroboter zum Aufräumen wird es zwar nicht geben, aber die Arbeit wird mit Dashboards erheblich erleichtert. Gerne unterstützen wir Sie dabei: mit Power BI, Tableau, Python oder einem anderen Tool Ihrer Wahl.

zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



