

Snowflake veröffentlicht wöchentlich neue Features, da ist es schwer, den Überblick über alle Neuerungen zu behalten. In diesem Beitrag blicken wir auf das Jahr 2022 zurück und blicken auf die besonders relevanten und interessanten Erweiterungen.
Rückblick auf die Snowflake Neuerungen 2022
Der Jahreswechsel ist eine Zeit, zur Ruhe zu kommen und auf die Ereignisse des Jahres zurückzublicken. So haben wir bereits gezeigt, wie man weihnachtliche Retrospektiven veranstalten kann und auf die Power BI Neuerungen 2022 zurückgeblickt.
Auch bei Snowflake hat sich im Jahr 2022 einiges getan. Besonders der Snowflake Summit im Juni war gespickt mit Ankündigungen, die auf der Snowflake Build im November vertieft wurden. Welche dieser neuen Features und Entwicklungen halten wir für besonders spannend? Einige der Neuerungen befinden sich aktuell noch in der privaten Vorschau und sind damit einerseits noch größeren Änderungen unterworfen und andererseits noch nicht allgemein testbar. Daher werden wir diese in künftigen Artikeln noch vertiefen:
- Externe Tabellen
- Snowpark für Python und optimierte Warehäuser
- Snowpipe Streaming
- Unistore und Hybride Tabellen
- Weitere Verbesserungen
Externe Tabellen (Delta, Iceberg und on Premise)
Im Gegensatz zu internen Tabellen, deren Daten innerhalb von Snowflake gespeichert werden, verbleiben die Daten bei externen Tabellen in einer externen Stage und Snowflake verwaltet lediglich die Metadaten. Dies ist nützlich, wenn
- es Gründe gibt, die Daten nicht in Snowflake zu speichern
- andere Werkezuge auf die gleichen Dateien zugreifen sollen und man sie nicht duplizieren will
Bisher war es nur möglich, externe Tabellen auf Basis von Dateien (z.B. im CSV oder Parquet Format) zu definieren. Das bringt einige Einschränkungen mit sich:
- Das Schema existiert nur in Snowflake. Andere Werkezuge, welche auf die gleichen Dateien zugreifen, definieren möglicherweise abweichende Datentypen für die gleichen Spalten
- Die Daten können nur gelesen, nicht geschrieben werden
- Die Performance ist schlechter als bei internen Snowflake Tabellen
Snowflake hat seine Möglichkeiten für externe Tabellen im Jahr 2022 deutlich erweitert. Nun können auch Tabellen Formate für externe Tabellen genutzt werden. Delta Lake ist bereits verfügbar, Iceberg noch in der private Preview. Die Table Formate bieten einige Vorteile:
- Bessere Performance
- Bessere Interoperabilität. Dies passt besonders gut zum Data Mesh Konzept, wenn mit verschiedenen Abfrage-Engines gearbeitet werden soll.
- Der Lockin zu Snowflake wird verringert
- Mit Iceberg Tabellen fällt die read-only Einschränkung, sodass diese fast wie Standard Tabellen genutzt werden können
Zudem ist die Unterstützung S3 kompatibler Tabellen on-Premise angekündigt. Damit werden hybride Szenarien zwischen Private- und Public-Cloud möglich.
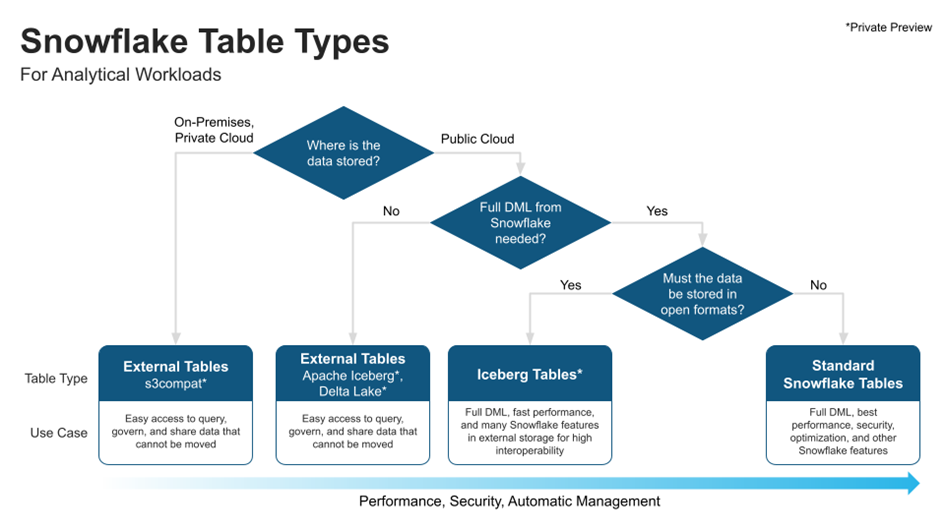
Abbildung 1 - Snowflake Table Types
Snowpark für Python und optimierte WareHouses
Mit der Snowpark API ist es möglich, Operationen, die über SQL hinausgehen, wie z.B. Machine Learning (ML) innerhalb von Snowflake auszuführen, statt die Daten zu Exportieren und in eine andere Plattform zu laden. So ist eine End-to-End ML Lösung auf einer Plattform möglich. Wir haben uns bereits mit Machine Learning Pipelines in Snowpark beschäftigt. Seitdem hat sich Snowpark weiterentwickelt und die lange erwartete Unterstützung von Python, die Hauptsprache moderner ML-Anwendungen, ist für alle verfügbar. Über Python User Defined Functions (UDFs) kann die eigene Python Funktionalität in Snowflake gebracht werden.
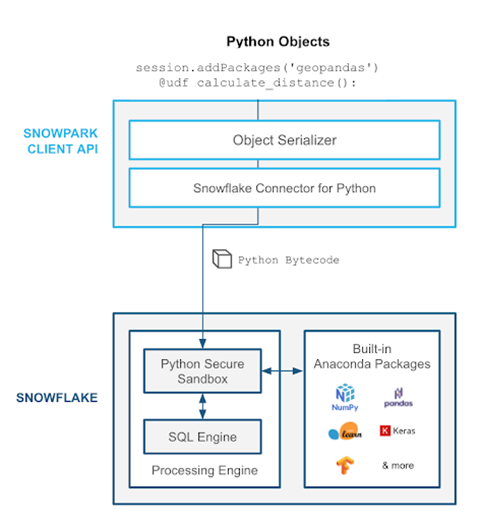
Abbildung 2 - Snowpark Python Integration
Der Vorteil von Snowpark eine Vielzahl von Anwendungsfällen auf einer Plattform auszuführen, bezieht sich auch auf die gemeinsame Verwendung der virtuellen Warehäuser. Jedoch unterscheiden sich die Anforderungen an die Rechenleistung zwischen klassischen Extract Load Transform (ELT) Verarbeitungen und Machine Learning Modellen. Diesen Anforderungen begegnet Snowflake mit Snowpark-optimierten Warehouses, welche die 16-fache Menge Arbeitsspeicher im Vergleich zu Standard-Warehouses bieten. Programme müssen dafür nicht umgeschrieben werden, sondern funktionieren auf den optimierten Warehouses ebenso wie auf ihren Standardpendants. Die Kosten sind 1,5 Mal so hoch wie bei Standard Warehouses. So kostet ein optimiertes Medium Warehouse 6 statt 4 Credits pro Stunde. Man sollte also abwägen und testen, ob die eigenen Anwendungen tatsächlich vom höheren Arbeitsspeicher profitieren.
Snowpipe Streaming
Mit Snowpipe hat Snowflake eine Möglichkeit für das kontinuierliche Laden von Daten eingeführt. Das bisherige Snowpipe basiert dabei auf Dateien aus einer externen Stage und entspricht eher kleinen Batches als einem kontinuierlichen Stream. Snowpipe Streaming erweitert die Funktionalität, um Daten mit geringerer Latenz zu laden. Dazu kann Kafka direkt angebunden werden. Möchte man Datensätze mit geringer Latenz laden, ist Snowpipe Streaming künftig die richtige Wahl. Werden die Daten jedoch nicht in Echtzeit geliefert, sondern in größeren Dateien, dann bietet Streaming keine Vorteile.
Passend zu Snowpipe Streaming gibt es mit dynamischen Tabellen eine weitere Neuerung. Diese ermöglichen es, eine Tabelle zu definieren, die sich automatisch aktualisiert, anhand einer vorgegebenen Refreshzeit (z.B. eine Minute). Damit lassen sich Pipelines aus Taks und Streams ersetzen, solange die Definition in SQL erfolgt. Die Aktualisierung erfolgt dabei inkrementell und nur wenn tatsächlich neue Daten vorliegen, sodass die Rechenzeit und damit Kosten reduziert werden. Wenn weitere Konstrukte wie User Defined Functions benötigt werden oder komplexe Abhängigkeiten definiert werden müssen, sind weiter Tasks und Streams nötig.
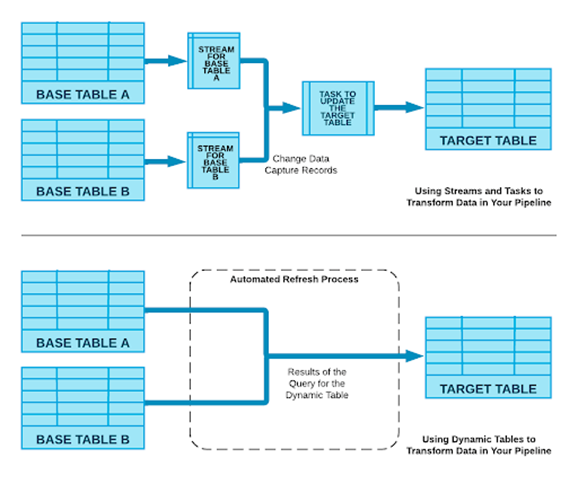
Abbildung 3 - Dynamische Tabellen
Unistore und Hybride Tabellen
Unistore bezeichnet Snowflakes Initiative OLAP (Online Analytical Processing) und OLTP (Online Transactional Processing) in einer Plattform zu vereinen. Umgesetzt wird dies durch hybride Tabellen, in denen die Daten logisch nur einmal vorliegen, aber physisch sowohl zeilenorientiert als auch wie bisher spaltenorientiert gespeichert werden. Die logische Abstraktion ermöglicht es, die Tabellen analog zu anderen Snowflake Tabellentypen zu behandeln, sodass keine speziellen Prozesse etabliert werden müssen. Auf den hybriden Tabellen gibt es nun auch Indizes und referentielle Integrität, die bei den bisherigen Tabellentypen keine Rolle spielten.
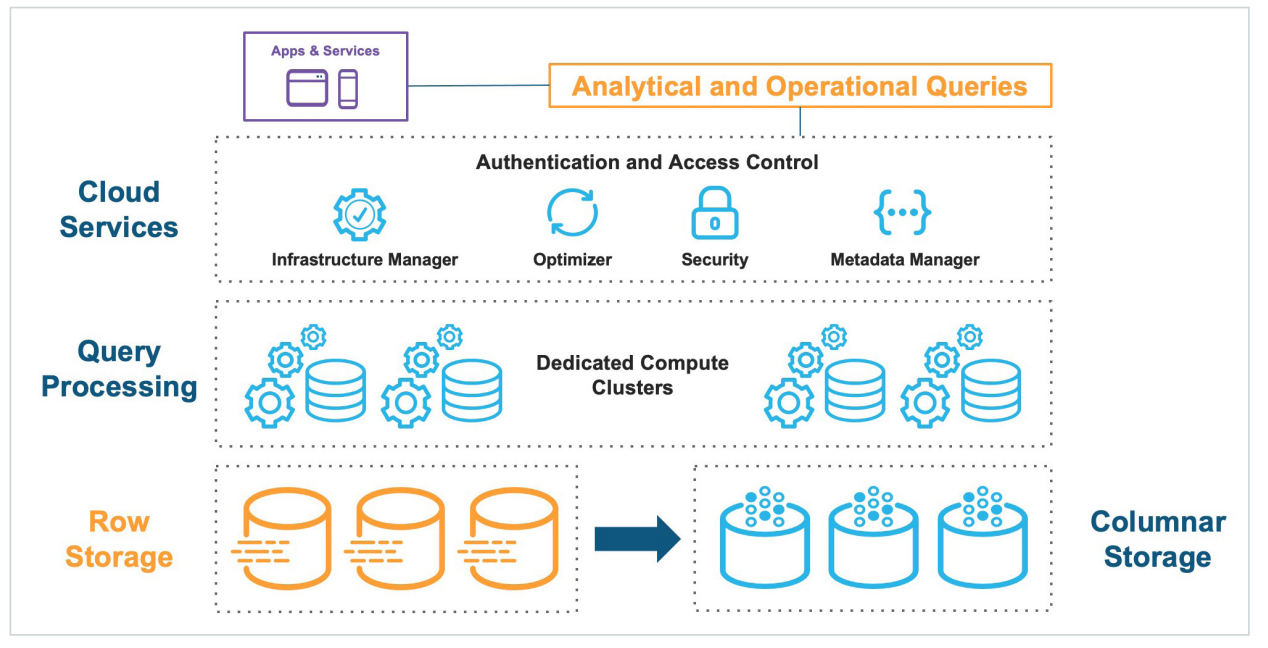
Abbildung 4 - Snowflake Unistroe
Es wird spannend, die hybriden Tabellen zu evaluieren, sobald sie öffentlich verfügbar sind. OLTP und OLAP Anwendungen auf einer Plattform wurden schon von vielen Herstellern angepriesen und können als heiliger Gral der Datenhaltung angesehen werden. In der Regel kam diese Initiative von transaktionalen Systemen, die auch analytische Abfragen ermöglichen wollten. Snowflake als analytisches System geht nun den umgekehrten Weg.
Durch die Trennung von Speicher- und Rechenressourcen und die Trennung virtueller Warehouses ist das übliche Problem, dass transaktionale Abfragen durch große analytische Abfragen ausgebremst werden für Snowflake gelöst. So viele Vorteile die Vereinheitlichung in einer Plattform auch bietet, so schwierig ist es auch, ein System für die sehr unterschiedlichen Lasten zu optimieren. Es ist daher schwer vorstellbar, dass Snowflake für eine Breite Masse von transaktionalen Systemen zur Datenbank der Wahl wird. Snowflake bietet schnelle Abfragen, aber nicht unbedingt im Bereich von Millisekunden. Hier wird es spannend, wie schnell die hybriden Tabellen tatsächlich sind.
Aber selbst wenn Snowflake mit Unistore nicht für alle transaktionalen Workloads die ideale Plattform wird, so trägt diese Funktion dem Trend zu immer operationeller werdenden Analysemöglichkeiten Rechnung. Wenn die OLAP-Anfragen im Vordergrund stehen, aber auch eine Gewisse OLTP-Last besteht, ist Unistore eine ideale Ergänzung, um die Daten in einer Plattform belassen zu können.
Weitere Verbesserungen
Replikation und Failover
Neben Daten können mehr und mehr Objekte repliziert werden, sodass weniger manueller Aufwand nötig ist, um Accounts für den Failover Fall synchron zu halten. Außerdem wird es mit dem Connection Objekt, das nicht an einen Account gebunden ist, einfach in Sekundenschnelle vom Primäraccount auf einen Sekundäraccount umzuschalten.
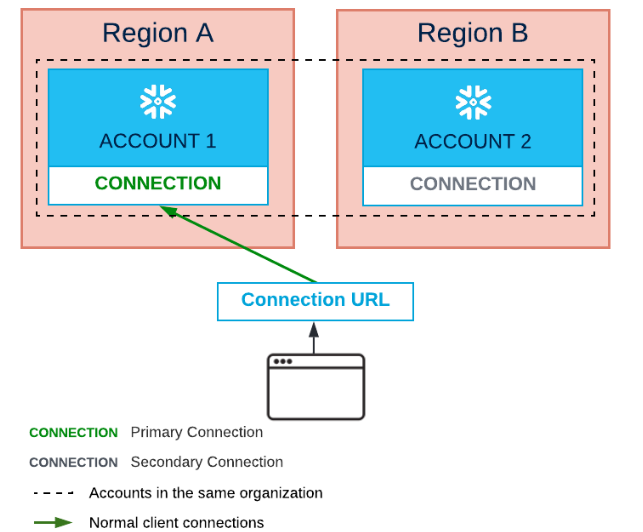
Abbildung 5 - Replication und Failover
Snowflake sCripting
Der SQL Dialekt von Snowflake wird stetig erweitert. So werden nun Schleifen in SQL möglich, für die in Snowflake bisher Javascript verwendet werden musste. Die Syntax ist dabei sehr ähnlich zu Oracle PL / SQL. Dies verbessert einerseits die Übersichtlichkeit und andererseits werden auch Migrationen bestehender Systeme vereinfacht, wenn diese neben Batch SQL auch stark auf Schliefen und Cursor setzen.
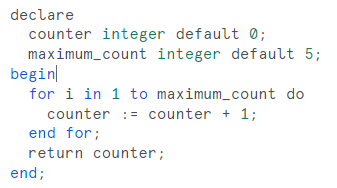
Abbildung 6 - Snowflake Scripting
Marketplace
Auch der Marketplace entwickelt sich stetig weiter. War es früher noch nötig, außerhalb von Snowflake eine vertragliche Einigung mit dem Daten Provider zu schließen, so ist dies nun direkt in Snowflake möglich, mit flexiblen Preismodellen. Die Abrechnung kann sowohl Zeit basiert (z.B. monatlich) als auch per Query erfolgen.
Fazit
Snowflake hat im Jahr 2022 einerseits viele kleinere Verbesserungen, z.B. im Bereich Replikation, Scripting oder Marketplace durchgeführt, als auch größere Änderungen, z.B. mit Unistore angekündigt. Wir sind gespannt, was das Jahr 2023 bringt!
Abonnieren Sie unseren Blog, um über weitere Artikel informiert zu werden!
Mehr Informationen zum Thema Cloud DWH finden Sie auf unserer Seite zu Cloud Data Warehouse.
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



