
 Von der Bereitstellung von Kennzahlen aus dem Data Warehouse bis hin zu dem Einsatz von komplexeren Ansätzen wie Predictive Analytics oder Natural Language Processing spielt Data Analytics eine zentrale Rolle. In diesem Zusammenhang ist auch das Thema Cloud in letzter Zeit eines der häufigsten Buzzwords. Doch was steckt wirklich dahinter und warum ist Cloud Computing für eine:n Data Scientist:in nicht nur relevant, sondern erfolgsentscheidend? Welche Möglichkeiten bietet Snowflakes Snowpark?
Von der Bereitstellung von Kennzahlen aus dem Data Warehouse bis hin zu dem Einsatz von komplexeren Ansätzen wie Predictive Analytics oder Natural Language Processing spielt Data Analytics eine zentrale Rolle. In diesem Zusammenhang ist auch das Thema Cloud in letzter Zeit eines der häufigsten Buzzwords. Doch was steckt wirklich dahinter und warum ist Cloud Computing für eine:n Data Scientist:in nicht nur relevant, sondern erfolgsentscheidend? Welche Möglichkeiten bietet Snowflakes Snowpark?
Dieser Artikel ist der Start einer Blogreihe zum Thema Data Science mit Snowflake. Demnächst folgt ein Artikel mit einem Tutorial zu Snowpark.
Data Scientist:innen analysieren Daten, um verschiedene Erkenntnisse aus ihnen zu gewinnen. Mit dem zunehmenden Interesse von Big Data ist die betrachtete Datenmenge meist sehr groß und liegt in unterschiedlicher Form (strukturiert, semi-strukturiert und unstrukturiert) in verschiedenen Datensilos vor. Hier besteht die Gefahr verschiedener isolierter Datenquellen, die aufgrund der benötigten Infrastruktur und Speicherkapazität häufig komplex zu verwalten sind. Preiswertere Speicherkapazitäten sowie das weite Angebot an Open-Source-Plattformen und Tools für Cloud Computing ebnen den Weg zum Verwalten dieser Daten in der Cloud. Die verfügbaren Tools bieten verschiedene Programmiersprachen, Tools und Frameworks für das Speichern, Abrufen und Analysieren von Datenmengen. Aufgrund der Möglichkeit durch eine hohe Skalierbarkeit auch zunehmend wachsende Datenmengen zu analysieren und flexibel auf die Infrastrukturanforderungen zu reagieren, wird Cloud Computing zum Schlüssel für Data Scientist:innen.
Was ist Snowpark?
Snowflake ist es eine zentrale Cloud Plattform, in der alle Datenverarbeitungen stattfinden: vom Data Warehousing über Data Science bis hin zum Austausch von Daten. Durch die skalierbare und high-Performance Cloudlösung können auch große und wachsende Datenmengen unkompliziert integriert werden, ohne dass sich Gedanken über Rechenressourcen und Infrastruktur gemacht werden müssen. Über die Sicherheit der Daten in Snowflake haben wir bereits eine Blogpostreihe geschrieben — zum Einstieg empfiehlt sich der erste Beitrag Snowflake: Sind meine Daten im Cloud-DWH sicher?
Snowpark ist eine Komponente von Snowflake, die seit Juni 2021 als Preview Feature der Cloud Plattform auf dem Markt ist. Die Komponente bietet eine API zum Abfragen und Verarbeiten von Daten in einer Datenpipeline. Demnach kann eine Anwendung erstellt werden, welche Daten in Snowflake verarbeitet, ohne diese vorher auf das System zu verschieben, auf dem der Anwendungscode ausgeführt wird.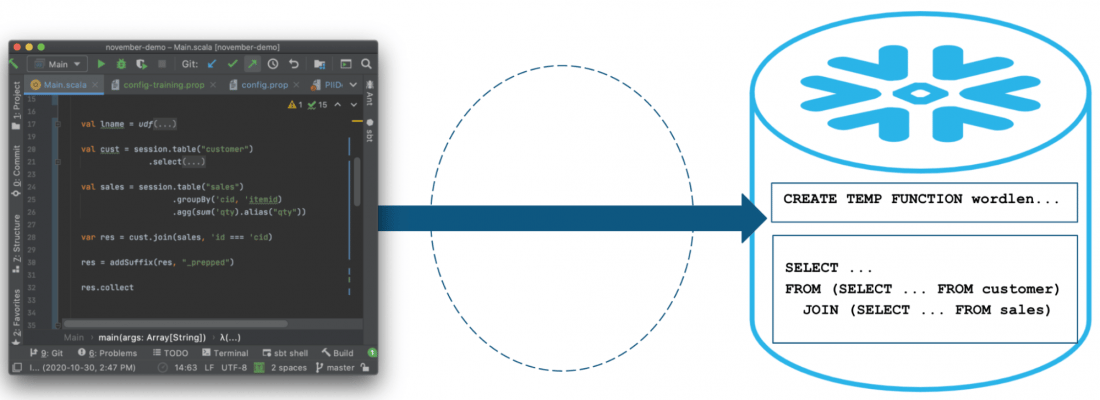
Welche Vorteile bietet Snowpark?
- Zentrale Lösung
Während in traditionellen Set-ups die Daten zunächst in ein weiteres System extrahiert, aufbereitet und dort von Data Scientist:innen bearbeitet werden, bietet Snowpark die Möglichkeit, Daten integriert innerhalb von Snowflake zu verarbeiten. Dies eliminiert den Zusatzaufwand, der durch ein weiteres System in Form von Integration, Verwaltung und einer erhöhten Komplexität entsteht. Der Code wird direkt innerhalb von Snowflake ausgeführt. Auf diese Weise müssen die Daten nicht zunächst lokal geladen werden, was zusätzlich häufig durch rechtliche Vorschriften eingeschränkt würde.
- Ressourcenoptimierung
Im Kontext von großen Datenmengen kann von verteilter Berechnung auf Clustern von Rechenknoten profitiert werden. Häufig genutzte Systeme wie Hadoop oder Spark bauen ebenfalls auf diesem Prinzip auf, um große Datenmengen zu verarbeiten. Durch die Nutzung der bereits existierenden Infrastruktur von Snowflake, ist dies bei Snowpark besonders unkompliziert und flexibel, sodass wenig Overhead erzeugt wird.
- Integration etablierter Data Science Libraries
Snowpark bietet die Möglichkeit auf existierende Data Science- und Machine Learning-Lösungen aufzubauen. Hierfür können verschiedene Libraries in die Entwicklungsumgebung geladen und genutzt werden. Die Daten aus Snowflake werden in Form von verarbeitbaren Data Frames bereitgestellt.
- Unkomplizierter Datenaustausch
Ferner kann die eigene Datenbasis über den Snowflake Marketplace erweitert werden. Dieser bietet Zugriff auf Live-Daten und anderen regulierten Datasets (z. B. Wetterdaten, GDP-Daten und Finanztrends), welche automatische Updates in Echtzeit erhalten. Somit werden der Aufwand und die Kosten, welche mit einer herkömmlichen Datenerfassung und -transformation verbunden sind, beseitigt. Zudem können auch eigene Datenbestände an mehrere Datenkonsumenten in Snowflake vermarktet werden.
Wie funktioniert Snowpark?
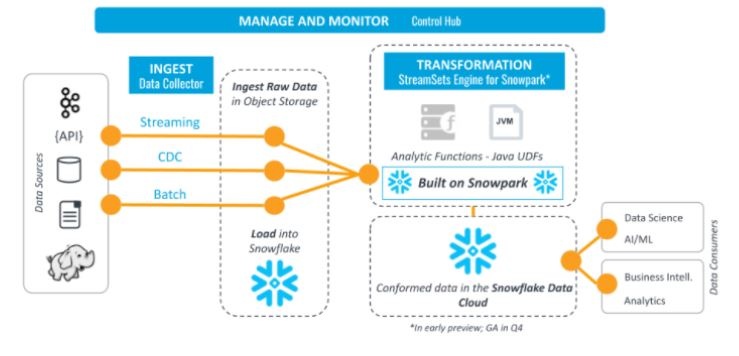
In Snowpark werden Operationen direkt in Snowflake ausgeführt. Hierdurch wird die Datenmenge reduziert, welche zwischen Client und der Snowflake-Datenbank übertragen wird. Die Kernabstraktion in Snowpark ist ein Data Frame. Dieses kann so eingerichtet werden, wie es für einen bestimmten Verwendungszweck benötigt wird. Die Daten werden dabei nicht während der Erstellung des Dataframes abgerufen. Stattdessen kann zu einem beliebigen Zeitpunkt eine Aktion ausgeführt werden, um die entsprechende SQL-Anweisung zur Auswertung der Daten an die Snowflake-Datenbank zu senden. In der aktuellen Preview ist Snowpark in Scala und Java nutzbar. Eine Integration in Python ist aktuell in Planung und als private Vorschau verfügbar.
Zudem gibt es die Möglichkeit, benutzerdefinierte Funktionen (UDFs / user-defined functions) zu erstellen. Snowpark überträgt diesen Programmcode auf den Server und die Daten werden in der Cloud verarbeitet. Die Funktionen können dabei in derselben Sprache geschrieben werden, wie für den Clientcode verwendet wird. Um diese Funktionen in der Snowflake-Datenbank zu verwenden, müssen UDFs in dem benutzerdefinierten Code definiert und aufgerufen werden. Snowpark überträgt den benutzerdefinierten Code für UDFs automatisch in die Snowflake-Datenbank. Wenn die UDFs im Clientcode aufgerufen werden, wird der benutzerdefinierte Code auf dem Server ausgeführt, wo sich die Daten befinden. Die Daten müssen daher nicht an einen externen Dienst übertragen werden. Die oben dargestellte Abbildung zeigt das Zusammenspiel der Komponenten von Snowpark und der umliegenden Infrastruktur für die Verarbeitung von StreamSets.
Diese UDFs bieten den Vorteil, dass sie auch extern angesprochen werden können. So ist eine Integration in bestehendes MLOps-Tooling denkbar. Ein Beispiel hierfür ist das Anstoßen durch externe Azure Functions. Darüber hinaus bietet Snowpark Programmiersprachenkonstrukte zum Erstellen von SQL-Anweisungen, wie beispielsweise eine Select-Methode für die Rückgabe von Spaltennamen. Weiterhin profitieren Anwender von Funktionen wie intelligenter Codevervollständigung und Typprüfung bei nativen Sprachkonstrukten.
Welche Anwendungsfälle gibt es für Snowpark?
Snowpark kann in verschiedenen Schritten des Data Science-Workflows verwendet werden. Anwendungsfälle sind vielseitig, sie umfassen beispielsweise ein beschleunigtes Feature Engineering, Natural Language Processing (NLP), Sentiment Analysis und Clustering.
Die UDFs von Snowpark ermöglichen Nutzern, die unbegrenzte Leistung, Elastizität und Skalierbarkeit von Snowflakes Elastic Performance Engine zu verwenden. Der Aufbau von komplexen Datenpipelines wird vereinfacht und eigener Code kann als Teil einer Notebook-basierten Programmierung (z.B. in H20.ai) verwendet werden. Dabei können bevorzugte Programmiersprachen genutzt werden, um Feature Engineering Bemühungen zu beschleunigen, indem vertraute Programmierkonzepte wie Data Frames verwendet und diese Workloads dann direkt in Snowflake ausgeführt werden. Auch zur Vorbereitung eines Data Frames zu späteren Aufrufen von Machine Learning Modellen kann Snowpark verwendet werden.
Ein anderer Anwendungsfall ist der Einsatz von NLP. Snowpark bietet die Möglichkeit, auf bereits bekannte Libraries aufzubauen. Hierzu werden diese in eine Stage geladen und können anschließend in den UDFs verwendet werden. Das getting Started Tutorial von Snowpark bietet hierzu einen guten Einstiegspunkt, um Twitterdaten per NLP zu verarbeiten und anschließend das Sentiment einzelner Tweets zu bewerten.
Weiterhin kann eine Snowpark-UDF verwendet werden, um komplexe Aufgaben wie die Zuweisung von Datensätzen in die vom K-Means ML-Algorithmus gelernten Cluster durchzuführen.
Wie grenzt sich Snowpark von ähnlichen Lösungen ab?
Neben Snowflake sind Amazon Redshift und Google Big Query weitverbreitete Cloud DWH-Lösungen. Mit BigQuery ML bietet Google eine ähnliche Lösung wie Snowpark. Auch in BigQuery ML werden die Daten innerhalb des Cloud DWHs verarbeitet und eine Schnittstelle für Data Science- und Machine Learning-Projekten geboten. Die Zielgruppe sind hierbei Datenanalyst:innen als Kernusergruppe des DWH. Während Snowpark auf Java und Scala (und geplant Python) setzt, verwendet BigQuery ML SQL-Abfragen, um Machine Learning-Modelle zu erstellen. Ähnlich wird Redshift ML zum Training, Testing und Deployment von ML-Modellen unter Verwendung von SQL auf Amazon Redshift verwendet. Durch die Nutzung von SQL-Abfragen wird die Zielgruppe der Kernnutzer:innen des DWH angesprochen.
Für Data Scientist:innen eignet sich hingegen aus unserer Sicht Snowpark, denn es bedient sich der Standard-Programmiersprachen von Data Scientist:innen, die eine hohe Bandweite an Strukturierungsmöglichkeiten und ein großes Ökosystem an ML/Data Science spezifischen Bibliotheken mitbringen. Auf diese Weise wird das Lösen von Data Science-Projekten unterstützt. Allerdings sind dadurch auch die Komplexitätskosten im Vergleich zu SQL-Abfragen deutlich höher, denn die Skripte sind von den Versionen der Bibliotheken sowie deren Kompatibilität abhängig.
Fazit
Snowpark bietet eine Möglichkeit, die Data Cloud von Snowflake für maschinelles Lernen zu verwenden. Hierdurch können Unternehmen den Wert ihrer Daten, einschließlich unstrukturierter Daten und Daten von Drittanbietern, maximieren und gleichzeitig Ressourcen einsparen. Daten können direkt in der Cloud integriert und verarbeitet werden, welches den Aufwand und die Komplexität für die Verwaltung eines externen Systems erheblich minimiert. Dies bietet auch einen erheblichen Sicherheitsvorteil.
Da Snowpark erst seit Juni 2021 auf dem Markt ist, befindet es sich jedoch noch stark in der Entwicklung. Die Community ist zurzeit sehr klein und die Anzahl an veröffentlichten Artikeln und Beiträgen gering. Auf dem Snowday am 16.11.2021 hat Snowflake weitere Möglichkeiten für Snowpark angekündigt, wie beispielsweise eine Unterstützung von Python. Demnach soll Anaconda direkt in Snowpark integriert werden, sodass der Zugriff auf viele Packages einfach möglich ist. Im Zeitraum vom 13.06. bis 16.06. findet der Snowflake Summit statt. Wir sind schon sehr gespannt, welche Erweiterungen für Snowpark hier vorgestellt werden und berichten in unserem Blog!
Dieser Artikel ist der Start einer Blogserie zum Thema Data Science mit Snowflake. Geschrieben werden die Artikel vom Team Data Science der viadee IT-Unternehmensberatung. Demnächst folgt ein Artikel mit einem Tutorial zu Snowpark.
Der nächste Schritt: Unser Seminar Cloud Native KI
Wenn Sie sich oder Ihr Team im Bereich MLOps weiterbilden möchten, dann empfehlen wir unser  . Das Seminar führen wir online, in unseren Geschäftsstellen in Münster, Köln und Dortmund sowie auf Wunsch bei Ihnen im Haus durch.
. Das Seminar führen wir online, in unseren Geschäftsstellen in Münster, Köln und Dortmund sowie auf Wunsch bei Ihnen im Haus durch.
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



