

Neue Anforderungen an die Flexibilität und Skalierbarkeit des eigenen Data Warehouse (DWH) erfordern, zu hinterfragen, ob die bisher genutzten Modellierungsstrukturen und Ressourcen noch geeignet sind. Eine Möglichkeit, mehr Flexibilität zu erhalten, ist ein Data Vault DWH in der Cloud aufzubauen. Neben der Vorstellung von Data Vault als Modellierungsart und Snowflake als Anbieter für cloudbasierte DWH-Lösungen, wollen wir in diesem Blog-Beitrag außerdem zeigen, wie das Tool „dbtvault“ die Umsetzung erleichtert und effizient gestaltet.
Wie dbtvault Snowflake und Data Vault vereint
Dass Unternehmen Daten sammeln, um ihre Geschäftsprozesse zu verbessern und fundierte Entscheidungen zu treffen, ist nichts Neues. Neben rechtlich vorgeschriebener Dokumentation und Sicherstellung vom reibungslosen Ablauf aller Prozesse kann die geschickte Auswertung von gesammelten Daten schließlich auch zu Wettbewerbsvorteilen führen. Weniger eindeutig ist jedoch, wie die Datenspeicherung am besten umgesetzt werden kann. Leider ist die Antwort auf die Frage: „Welches Datenmodell ist für mein Data Warehouse am besten geeignet?“ stets: „Es kommt drauf an“. Immer häufiger überwiegen bei der Abwägung zwischen verschiedenen Modellen jedoch die Vorteile, die Data Vault bietet. Vor allem die Möglichkeiten, Datenstrukturen flexibel anzupassen, Daten einfach zurückzuverfolgen und zu überwachen sowie viele Informationen schnell und einfach zu laden, überzeugen Unternehmen, die sich ständig an die Marktbedürfnisse oder regulatorische Anforderungen anpassen müssen.
Ein weiterer Trend, der sich innerhalb von Data Warehouse-Lösungen abzeichnet, ist, auf cloudbasierte Services umzusteigen. Hierfür sprechen vor allem Vorteile wie verbrauchsabhängige Abrechnung und unbegrenzte Skalierbarkeit. Ein Vorreiter in diesem Markt ist Snowflake.
Spannend wird es, wenn man Data Vault und Snowflake zusammenbringt, um Flexibilität im Datenmodell und Skalierbarkeit in den Ressourcen miteinander zu vereinen. Wir wollen uns deshalb hier auf die Frage konzentrieren: „Wie lässt sich Data Vault am besten in Snowflake umsetzen?“. Dafür werden wir kurz darauf eingehen, was Data Vault als Modellierungsstruktur ausmacht, um besser verstehen zu können, wieso Snowflake für die Umsetzung eine geeignete Lösung ist. Außerdem werden wir sehen, dass die Eigenschaft von Data Vault zu einer verschachtelten Datenstruktur mit vielen Entitäten zu führen die Nutzung eines Tools für die Unterstützung von wiederkehrenden Transformationsaufgaben sinnvoll macht. Als ein speziell entwickeltes Tool werden wir deswegen dbtvault vorstellen. Einblicke in die Nutzung und Vorteile werden damit die Basis für die erfolgreiche Umsetzung von SnowVault im eigenen Unternehmen schaffen!
Was macht Data vault aus?
Die Grundidee von Data Vault ist es, Agilität in das traditionelle Data Warehouse-Design zu bringen und damit Flexibilität in der Datenstruktur sowie Near-Real-Time Verarbeitung zu ermöglichen. Um diese Ziele zu erreichen, werden bei der Data Vault-Modellierung die zu speichernden Informationen in drei Grundbausteine aufgeteilt. Die Hubs stellen die Kernobjekte der Geschäftslogik dar, wie zum Beispiel Kunden oder Bestellungen in einem Vertriebsunternehmen. Sie beinhalten lediglich die Informationen, die notwendig sind, um ein Geschäftsobjekt eindeutig zu identifizieren. Durch Links ist es möglich, verschiedene Hubs miteinander zu verbinden. So kann zum Beispiel abgebildet werden, welcher Kunde welche Bestellung getätigt hat. Alle Informationen, die über die eindeutige Identifizierung eines Geschäftsobjekt hinausgehen, sind ausgelagert in sogenannte Satelliten. Sowohl Hubs wie auch Links können dabei mit Satelliten verbunden werden. Dieser Aufbau ermöglicht es, sich ändernde Datenstrukturen flexibel anzupassen, indem neue Satelliten nachträglich einfach hinzugefügt werden können. Außerdem kann durch die Aufteilung der zu speichernden Daten in verschiedene Hubs, Links und Satelliten parallele Verarbeitung und Beladung erreicht werden, was sich positiv auf die Skalierbarkeit auswirkt. Dieser Vorteil wird auch weiter von dem Hashing von Schlüsseln unterstützt, das zum Standard der aktuellsten Data Vault Version gehört.
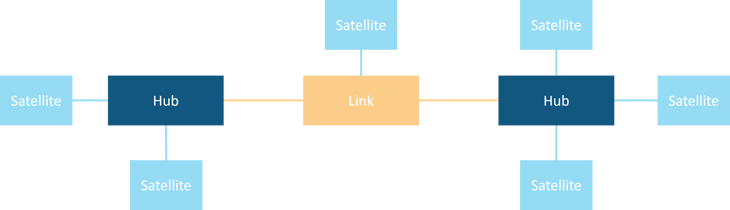
Abbildung 1 - Ein einfaches Data Vault Modell mit den drei Grundbausteinen Hub, Link und Satellit
Die Data Vault Architektur ist außerdem in die zwei Ebenen Raw Vault und Business Vault aufgeteilt. Bei dem Raw Vault handelt es sich ausschließlich um eine strukturierte Speicherung der Rohdaten, die den Modellierungskonventionen von Data Vault folgt. Da die Speicherung ein eindeutig festgelegtes Schema hat, kann das Raw Vault automatisch beladen werden. Weil außerdem das „INSERT-only“-Prinzip verwendet wird, formt das Raw Vault die Historisierung aller Geschäftsdaten. Bei dem darauf aufbauenden Business Vault sind die Informationen hingegen bereinigt und unter Umständen verdichtet. Außerdem können zusätzliche Informationen abgebildet werden, die durch angewendete Geschäftslogik erzeugt werden. Das macht das Business Vault zu einer Erweiterung vom Raw Vault, das als Grundlage für die nachgelagerte Berichterstattung genutzt werden soll. Klassische Data Marts für Analysezwecke können dafür einfach der Data Vault-Struktur folgen. Für die Visualisierung ist es aber sinnvoll, die Daten zusätzlich im Star-Schema darzustellen, da die Data Vault-Architektur auf die effiziente Speicherung von Daten optimiert ist und nicht auf deren Abfrage. Das bedeutet, dass für die Data Marts entweder zusätzliche Ansichten auf dem Business Vault erstellt werden oder wenn dies wegen schlechter Performance nicht möglich ist, weitere Tabellen hinzugefügt werden, die die benötigten Daten in der gewünschten Struktur abbilden. Für tiefere Einblicke in das Thema Data Vault gibt es bereits einen spannenden Blog-Beitrag von uns.
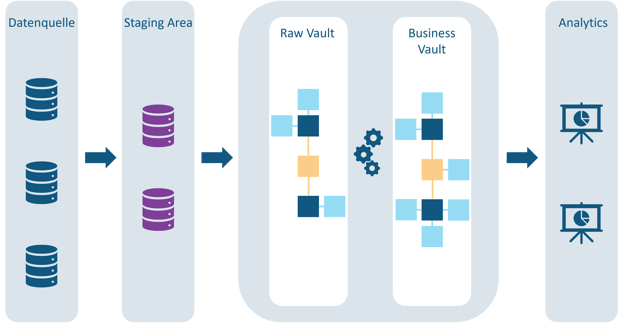
Abbildung 2 - Schichten einer Data Vault Architektur
Wieso Snowflake?
Da Data Vault eine Modellierungsmethode ist, ist die Umsetzung nicht an eine bestimmte DWH-Lösung gebunden. Data Vault lässt sich daher sowohl mit on-premise Ressourcen wie auch in der Cloud nutzen und ist ebenfalls unabhängig davon, ob eine Datenbank oder ein Data Lake genutzt wird. Einige Vorteile lassen sich jedoch am besten mit cloud-nativen Lösungen realisieren. Eines der bedeutsamsten Argumente für Snowflake ist, dass die verbrauchsabhängigen Kosten und Skalierungsmöglichkeiten der Ressourcen mit den Anforderungen der Data Vault Modellierung einhergehen. Solange die gespeicherte Datenmenge überschaubar ist, sind die Speicherungskosten marginal und bei wachsender Datenlage kann die Speicherkapazität skaliert werden, ohne sich Gedanken um die Anschaffung von neuen Servern machen zu müssen. Auch die Tatsache, dass Data Vault durch parallelisiertes Beladen Performance-Vorteile bietet, kann durch die Snowflake-Architektur unterstützt werden, indem Rechenressourcen verbrauchsabhängig zur Verfügung gestellt werden. Ebenfalls bereits herausgestellt haben wir, dass Data Vault keine Updates von Daten vorsieht, sondern nur das Laden von neuen Informationen, die mit einem Zeitraum, in dem sie gültig sind, verbunden werden können. Dies passt perfekt zur Snowflake-Architektur, da auch hier das INSERT-only Prinzip verwendet wird.
Auch der Snowflake-eigene Datentyp „VARIANT“ bietet wertvolle Flexibilität, die in der Data Vault-Struktur genutzt werden kann. Der Datentyp ermöglicht es semi-strukturierte Daten (z.B in JSON-Dateien) abzuspeichern. Durch das Laden von Informationen des Typs „VARIANT“ in Satelliten des Raw Vault ist es möglich, Attribute zu speichern, die nicht näher spezifiziert sind und unter Umständen bisher nicht im Unternehmen verwendet werden. Innerhalb des Business Vaults können dann Ansichten auf solche Satelliten erstellt werden, die je nach Bedarf auf Teile der semi-strukturierten Daten zugreifen. Bei sich ändernden Geschäftsanforderungen können die Ansichten agil angepasst werden, ohne ein erneutes Laden von Daten in das Raw Vault vorauszusetzen.
Ebenfalls nützlich sind Snowflakes Datenpipelines, die das Transformieren und Laden von kontinuierlichen Daten unterstützen, vor allem wenn Near-Real-Time Verarbeitung erreicht werden soll. Die Pipelines können dabei bei Bedarf drei Funktionen erfüllen:
- Laden von kontinuierlich neuen Daten aus verschiedenen Speicherorten in zentrale Staging-Tabellen. Hierfür kann zum Beispiel Snowpipe, der Datenerfassungsservice von Snowflake, genutzt werden.
- Nachverfolgung von Änderungen durch Stream-Objekte auf den Staging-Tabellen, um neue Informationen schnell zu identifizieren.
- Ausführung von Transformationsaufgaben auf den Daten in den Stream-Objekten. Diese können nach einem Zeitplan ausgeführt werden und miteinander verbunden sein, um zum Beispiel neue Daten aus den Staging-Tabellen in des Raw Vault zu laden.
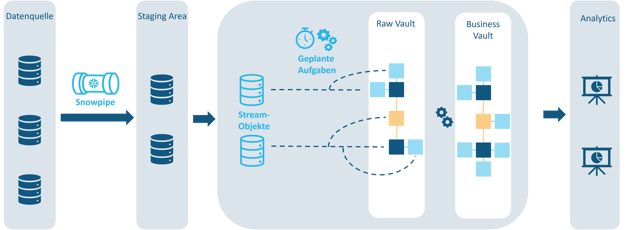
Abbildung 3 - Wie Snowflakes Datenpipeline zum Aufbau eines Data Vault Modells genutzt werden kann
Was ist dbtvault?
Jetzt wissen wir, dass Data Vault vor allem das Ziel der flexiblen Erweiterbarkeit und des schnellen Beladens hat. Außerdem ist deutlich geworden, dass Snowflake eine geeignete Umgebung ist, um dieses Ziel zu erreichen, was nur noch die Frage offenlässt, wie man die DWH-Struktur am effizientesten umsetzen kann. Da bei schnell wachsender Datenmenge und komplexer werdender Datenstruktur immer mehr Tabellen, Ansichten und Abhängigkeiten hinzukommen, verliert man schnell den Überblick. Damit keine wertvolle Arbeitszeit darauf verwendet werden muss, SQL-Statements zu schreiben, anzupassen und nach Fehlern zu durchsuchen, ist es sinnvoll repetitive ELT-Prozesse mit einem passenden Tool umzusetzen.
Wer sich mit dem Laden und Transformieren von Daten im Data Warehouse beschäftigt hat, kennt vielleicht bereits das „data build tool“ (dbt). Als Transformations-Workflow ist es eine einfache und standardisierte Möglichkeit, produktionsreife Datenpipelines aufzubauen. Damit ist dbt grundsätzlich ein geeignetes Werkzeug, um Datenmodelle wie Data Vault aufzubauen, jedoch nicht konkret auf die Modellierungsanforderungen zugeschnitten. Anders sieht es bei dbtvault aus, ein open-source package das auf dbt läuft und speziell dafür entwickelt wurde, den nötigen ELT-Code für ein Data Vault-Warehouse zu generieren.

Abbildung 4 - Prozessschritte, die durch dbtvault unterstützt werden
Eine Vielzahl von Vorteilen spricht dafür, ein speziell zugeschnittenes Tool wie dbtvault zu verwenden. Dadurch, dass der Aufbau der Data Vault Struktur durch dbtvault ausschließlich Metadaten-getrieben ist, können Fehler, die beim manuellen Schreiben von SQL-Statements entstehen, minimiert werden. Wenn es zu Änderungen in der Datenstruktur kommt, können diese zentral angepasst werden, ohne riesige Mengen an SQL-Statements auf Abhängigkeiten zu untersuchen. Das bedeutet, dass die Nutzung von Metadaten die Wartbarkeit erhöht, sowie Flexibilität für sich ändernde Anforderungen bietet. Insgesamt ist es mit dbtvault möglich eine automatisierte Pipeline aufzubauen, die zu weniger Integrationsfehlern führt, leichtere Verständlichkeit des ELT-Prozesses erlaubt und die Wartbarkeit vereinfacht. Dadurch kann sowohl Zeit- wie auch Geld gespart werden und das Team kann sich auf die wichtigen Fragen zur Modellierung konzentrieren, anstatt repetitiven Aufgaben nachzugehen. Außerdem lädt dbtvault Daten parallelisiert und inkrementell, um eine gute Performance zu erreichen, die bei der Near-Real-Time Verarbeitung von Daten in einem Data Vault DWH benötigt wird. Nicht zuletzt ist es auch wertvoll, dass dbtvault von einer großen Community genutzt wird und man somit von den Erfahrungen und Weiterentwicklungen anderer profitieren kann.
Wie wird dbtvault genutzt?
In der folgenden Abbildung ist zu sehen an welcher Stelle das dbtvault-Paket den ELT-Prozess unterstützt.
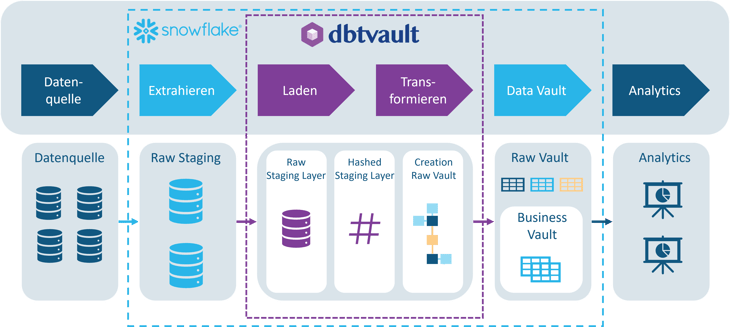
Abbildung 5 - Aufgaben, die durch dbtvault umgesetzt werden können
Das dbtvault Paket setzt voraus, dass die Rohdaten aus den Datenquellen bereits in Snowflake geladen wurden. Die Erstellung eines „Raw Staging Layer“ wird also nicht von dem Paket unterstützt. Dafür können zum Beispiel andere Funktionen von dbt verwendet werden. Alternativ kann auch Snowpipe genutzt werden, um den Ladeprozess der Daten einfach zu automatisieren. Von dbtvault unterstützt sind die darauffolgenden Transformationen, die nötig sind, um den Raw Vault zu beladen.
Dabei kann durch Metadaten festgelegt werden, aus welchen Staging-Tabellen und Spalten die Informationen für die Hubs, Links und Satelliten kommen. Neben den drei Kernbausteinen existieren auch weitere Makros für spezialisierte Links oder Satelliten. Ein Beispiel hierfür sind sogenannte „Effectivity Satellites“, die speichern, in welchem Zeitraum ein Eintrag aus einer Link-Tabelle gültig ist. Auch der Hashing-Prozess, der für die Key Erstellung aller Tabellen genutzt wird, wird von dbtvault übernommen. Das Hinzufügen der Geschäftslogik und die damit einhergehende Erstellung des Business Vaults muss hingegen wieder durch manuell geschriebene SQL-Statements oder durch andere Tools umgesetzt werden. Erwähnenswert hier ist aber, dass dbtvault ebenfalls Strukturen wie bridge tables oder point-in-time tables unterstützt, die zwischen dem Data Vault und dem Analytics Layer platziert werden können, um die Abfrageleistung zu erhöhen. Die genauen Funktionalitäten können in der Dokumentation von dbtvault nachgelesen werden.
Um nun zu zeigen, wie man sich den Aufbau von den Kernobjekten mit dbtvault vorstellen kann, haben wir ein einfaches Beispiel entworfen (siehe Abbildung 6). Neben den Kernobjekten Kund:innen und Bestellungen gibt es jeweils ein Satellit mit weiteren Informationen zu den beiden und einen Link zur Verbindung der Geschäftsobjekte.

Abbildung 6 - Beispiel für Data Vault Modellierung für die Daten eines Vertriebsunternehmens
Die Spezifizierungen, die notwendig sind um den Kund:innen Hub zu erstellen, sind in der folgenden Abbildung zu sehen. Dafür wird vorausgesetzt, dass Kunden:innen-daten bereits in einer Staging-Tabelle mit dem Namen "stg-customer" gespeichert sind. Das Template für die Erstellung eines Hubs kann einfach in ein Modell kopiert und sprechend umbenannt werden. Über dem Template ist außerdem zu sehen, wie man dem Macro Metadaten zur Verfügung stellt. Dadurch können die Angaben in ausführbare SQL-Statements übersetzt werden, die ermöglichen, dass dbt das Data Vault erstellen und inkrementell beladen kann.
Abbildung 7 -Spezifizierung des Kunden:innen Hub mit dbtvault
Wenn man denselben Hub manuell mit SQL-Statements aufbauen möchte, ist das schon komplizierter. Ausgehend von derselben Staging-Tabelle, muss zuerst eine Tabelle mit den korrekten Spalten erstellt werden. Außerdem ist es wie oben beschrieben sinnvoll ein Stream-Objekt zu erstellen, um Veränderungen in den Daten zu überwachen. Darauf kann dann eine Ansicht erstellt werden, um unter anderem das Hashing der Business Keys durchzuführen. Danach folgt die Spezifizierung, wie die Informationen aus dem Stream-Objekt in den Hub geladen werden können. An diesem einfachen Beispiel ist schon zu sehen, dass durch die Nutzung von dbtvault deutlich weniger SQL geschrieben werden muss. Würde man hier die Datenstruktur ändern wollen, müsste man das an mehreren Stellen berücksichtigen, was den Aufbau fehleranfällig macht. Dieser Fakt wird nur weiter verstärkt, wenn man eine stark verschachtelte Datenstruktur in einem produktiven DWH betrachtet.
Abbildung 8 -Erstellung einer Tabelle für den Kunden:innen Hub
Abbildung 9 -Beladen des Kunden:innen Hub mit Daten aus der Staging-Tabelle
Fazit
Wie wir gesehen haben, passen die Flexibilität und Skalierbarkeit von Data Vault sehr gut zusammen mit den Vorteilen, die Snowflake seinen Nutzer:innen bietet. Ob es für das eigene Unternehmen die beste Strategie ist, eine Data Vault Modellierung für die Speicherung der Geschäftsdaten zu verwenden, gilt es individuell zu beurteilen. Sollte man sich jedoch dazu entscheiden, ein Data Vault Data Warehouse aufzubauen, bietet dbtvault (als Ergänzung zu dbt) viele Vorteile zur Unterstützung der ELT-Prozesse. Durch die Funktionen, die das Paket bietet, kann der Aufbau des Data Vaults standardisiert und automatisiert werden. So kann der Fokus des Teams auf der Data Vault-Modellierung liegen, anstatt viel Zeit in die Umsetzung durch SQL-Statements zu investieren. Außerdem gibt es für die Nutzung kaum Einstiegsbarrieren, weil es sich bei dbtvault um ein Open Source-Tool handelt. Es ist somit eine leichtgewichtige und günstige Alternative zu kommerziellen Data Warehouse Automatisierungslösungen.
Abonnieren Sie unseren Blog, um über weitere Artikel informiert zu werden!
Mehr Informationen zum Thema Cloud DWH finden Sie auf unserer Seite zu Cloud Data Warehouse.
Zu diesem Blogartikel hat Melena Thieß (WWU Münster) mit ihrer Tätigkeit als Werkstudententin maßgeblich beigetragen.
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



