

Wie können Fachanwender:innen herausfinden, wie ein KI-Modell „tickt“? Am liebsten durch das Stellen von Fragen in natürlicher Sprache. Dazu haben wir einen Prototypen gebaut.
EXPLAINABLE AI (XAI)
Explainable AI umfasst eine Vielzahl von Methoden, die das Verhalten eines Machine-Learning-Modells transparenter und nachvollziehbarer machen. Durch die ständige Neu- und Weiterentwicklung wird die Auswahl einer passenden Methode schnell unübersichtlich. Außerdem geben viele Methoden nicht aufbereitete, schwer verständliche Daten zurück und lassen sich oft nur in entsprechenden Programmierumgebungen nutzen. Das erschwert für Lai:innen der Programmierung und des und Machine Learning ungemein den Zugang zu diesen Funktionen, obwohl oft gerade die von den Entscheidungen des Computers profitieren und darin vertrauen können sollen.
Vertrauen ist ein wichtiges Stichwort im Zusammenspiel zwischen Mensch und Computer. Um dieses Vertrauen zu schaffen, haben wir im April bereits den Chatbot ERIC vorgestellt, der eine Vielzahl solcher XAI-Methoden in einem Chat umsetzt. Die Kommunikation zwischen Mensch und Maschine funktioniert bereits sehr gut über die Buttons im Chatfenster, die die einzelnen Erklär-Funktionen auslösen. Um den Kommunikationsfluss zwischen Mensch und Maschine weiter zu unterstützen, haben wir die Verarbeitung von ganzen Sätzen über Natural Language Processing (NLP) eingebaut. So können Nutzer:innen ihre Fragen frei formulieren und die in ERIC bekannten Funktionen wie „Was wäre wenn, …“ oder „Wie bekomme ich Ergebnis X?“ über das Chatfenster abfragen.
NATURAL LANGUAGE PROCESSING
Natural Language Processing verwendet algorithmische und mathematische Verfahren, um geschriebene und gesprochene Sprache für Computer zugänglich zu machen und sie zu verarbeiten. Das kann von einfachem String-Matching über analytische Verfahren bis hin zu komplexen Machine-Learning-Algorithmen reichen. Die analytischen Verfahren achten dabei besonders auf Wortformen (Morphologie), Satzbau (Syntax) und Wortbedeutungen (Semantik). Für ERIC sind besonders die letzten beiden ausschlaggebend.
Für die programmatische Analyse der Semantik werden sogenannte Word Embeddings genutzt, die Wörter als vieldimensionale Vektoren darstellen und so mathematische Operationen auf den einzelnen Wörtern erlauben. Dazu werden Wörter in einem großen Trainingskorpus anhand des Kontextes, in dem sie vorkommen, bewertet. Die daraus entstehenden Vektoren ähneln sich analog zu den Wörtern, die sie repräsentieren. So lassen sich semantische Operationen mathematisch darstellen und der resultierende Vektor entspricht dem Wort, das auch ein Mensch nach der Operation erwarten würde. Dies lässt sich am besten an einem Beispiel zeigen. Möchte man den Vektor für „Prinzessin“ haben, kann man diesen durch Addition und Subtraktion der Vektoren für „Prinz“, „Mann“ und „Frau“ berechnen:
Vec(Prinz) – Vec(Mann) + Vec(Frau) = Vec(Prinzessin)
Durch diese Wort-Vektoren lassen sich auch Vektoren für Sätze und sogar ganze Dokumente berechnen und vergleichen.
Bei Betrachtung der Syntax lassen sich besonders zwei grobe Unterteilungen treffen. Die sogenannte Konstituentensyntax, die Wörter zu größeren Komponenten zusammenfasst, und die Dependenzsyntax, die Abhängigkeiten zwischen Wörtern darstellt. Zur Veranschaulichung lassen sich hier zwei Syntaxbäume zu einem Satz vergleichen. Der Satz „Die Titanic verlässt den Hafen von Liverpool“ sieht als Baum einer Konstituentensyntax so aus:
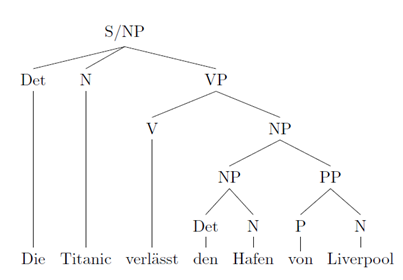
Hier sind mehrere Wörter zu Phrasen zusammengefasst, die die Konstituenten des Baumes bilden. Die Wörter „die“ und „Titanic“ bilden als weiblicher Artikel (Determinierer) und Nomen zusammen eine Nominalphrase (NP). Alle Konstituenten werden weiter zusammengefasst bis der Satz als einzelne Konstituente, der Verbalphrase, zusammengefasst wurde.
In einer Dependenzsyntax sieht diese Struktur anders aus:

Hier wird jedem Wort immer genau ein anderes zugeordnet und steht zu seinem übergeordneten Knoten in einer bestimmten Relation. Hier ist es möglich, direkt zu erkennen, dass „Titanic“ das Subjekt und „Hafen“ das Objekt des Satzes ist. Diese Relationen waren in der Konstituentensyntax noch nicht zu sehen.
ERIC: XAI MIT NATÜRLICHER SPRACHE
Durch die Verwendung von semantischer und syntaktischer Analyse ist es ERIC möglich, verschieden formulierte Anfragen der gewünschten XAI-Funktion zuzuordnen. In einem früheren Artikel zu ERIC haben wir bereits eine Beispielkonversation über den Titanic-Datensatz gezeigt. Der Datensatz beinhaltet Informationen zu den Passagier:innen des Schiffs von 1912. Die Features im Beispiel sind: (Kabinen-)Klasse, Geschlecht, Alter, Preis, Abfahrt (Hafen) und Anzahl der auf dem Schiff befindlichen Verwandten.
Das Machine-Learning-Modell kann für eine Person und dessen Merkmale vorhersagen, ob dieser in der Katastrophe wahrscheinlich gestorben wäre oder dieser überlebt hätte. Über NLP ist es möglich, eine Anfrage an den Modell-Erklärer ERIC frei zu formulieren. Im folgenden Beispiel haben wir bereits eine Anfrage getätigt und erfragen jetzt, was passiert, wenn wir einen Wert ändern.
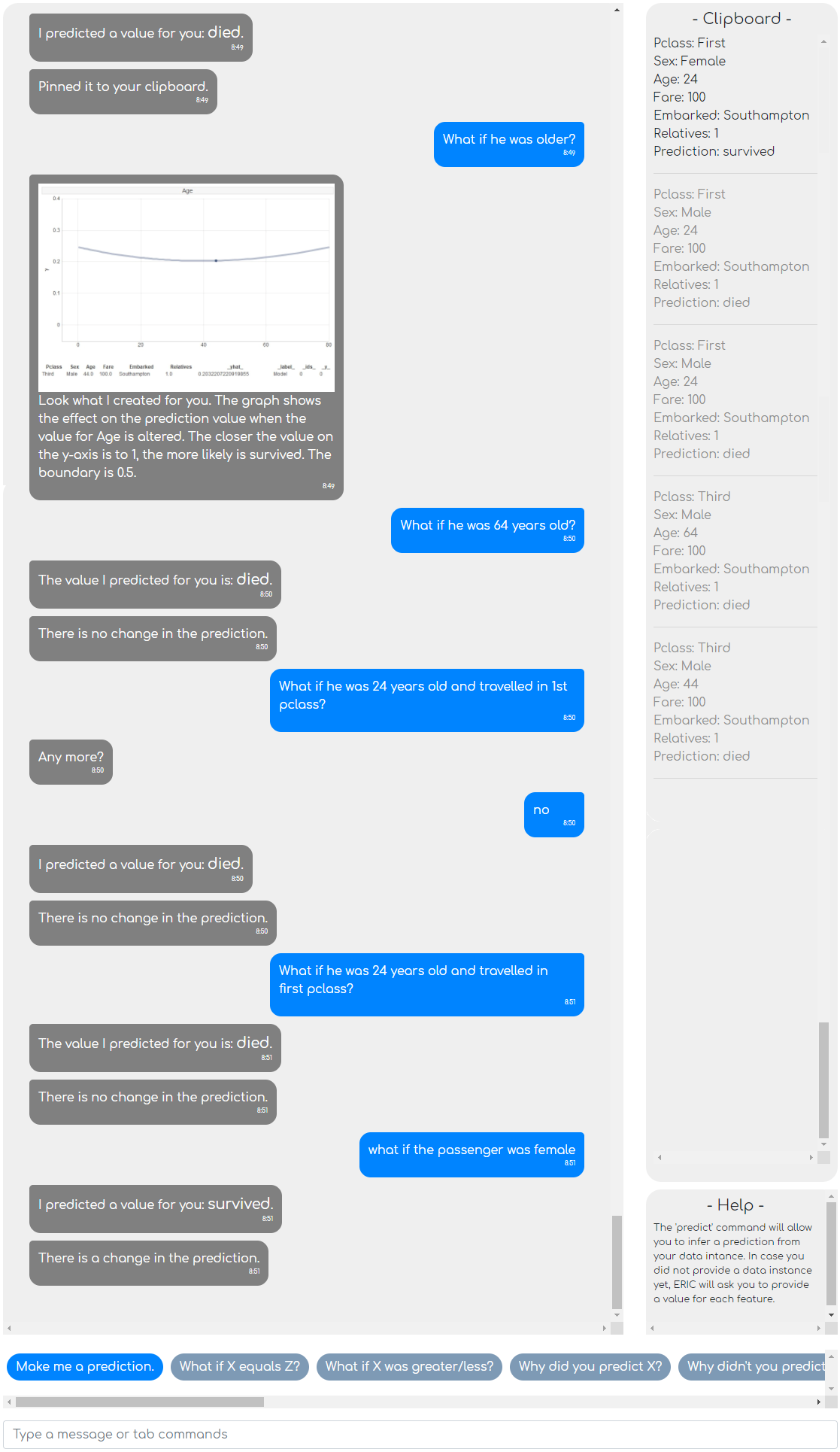
Unsere erste Instanz war ein Mann, Mitte vierzig, der in der dritten Klasse reiste und vermutlich gestorben wäre. Auch wenn er jünger und in der ersten Klassen untergebracht gewesen wäre, hätte sich daran nichts geändert. Erst die Änderung des Geschlechts führt zu einer Änderung zu „überlebt“, ganz nach dem Motto „Frauen und Kinder zuerst!“
Durch die Verarbeitung natürlicher Sprache können die Anfragen außerdem frei formuliert und mehrere Werte gleichzeitig angepasst werden. Bei Änderung des Alters ist es nicht einmal notwendig, den Wert „Alter“ zu erwähnen, da ERIC das Adjektiv „alt“ dem richtigen Attribut zuordnen kann.
ERIC kann noch mehr – wir suchen nach Sparringspartner:innen und Pilotprojekten für diese und weitere Ideen aus dem XAI-Umfeld. Sprechen wir darüber?

ERIC ist quelloffen, hier zu finden und freut sich über Unterstützung aller Art:
https://github.com/viadee/eric
Auch interessant im NLP Themengebiet sind die nachfolgenden Artikel:
RECHNUNGEN MIT NLP-VERFAHREN ANALYSIEREN UND PRÜFEN
Hinweis: Die gezeigten Komponenten und der Artikel sind Ergebnisse der Bachelor-Thesis von Simon Damrau aus dem Bereich Computerlinguistik an der Ruhr-Universität Bochum.
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



