
![NLP-Verfahren_AdobeStock_250563855-[Konvertiert]-730](https://blog.viadee.de/hs-fs/hubfs/KI/NLP-Verfahren_AdobeStock_250563855-%5BKonvertiert%5D-730.png?width=730&name=NLP-Verfahren_AdobeStock_250563855-%5BKonvertiert%5D-730.png)
Täglich gibt es mehr kleine Transaktionen, die mit Rechnungen belegt werden. Aufgrund der hohen Anzahl können der Überblick und die Kontrolle über diese schnell verloren gehen. Dadurch entstehen Betrugsmöglichkeiten und Beschaffung wird unübersichtlicher: Wie kann die Kontrolle mit KI zurückerlangt werden?
Viele Rechnungen entstehen in Geschäftsprozessen ohne Berücksichtigung der Einkaufsabteilung (Maverick Buying). Dagegen kann nur begrenzt etwas unternommen werden, weil ein dezentraler Einkaufsprozess für einige Geschäftsbereiche sinnvoll ist oder auch weil es nicht wirtschaftlich leistbar ist, als zentrale Beschaffung steuernd einzugreifen. Das Resultat sind viele Rechnungen, zu denen nur in einem begrenzten Rahmen strukturierte Daten vorliegen.
Die automatische Erkennung eines Rechnungsdatums oder einer IBAN auf einer Rechnung sind State of the Art, RPA erleichtert die Weiterverarbeitung. Viele Systeme arbeiten aber auf Basis von Vorlagen: Sachbearbeiterinnen und Sachbearbeiter markieren pro Lieferant, was wo steht. Gerade für den fachlichen Inhalt von Rechnungen, gelingt das nicht: „Was wurde beschafft?“ KI-Verfahren, die versuchen, generisch Tabellenstrukturen in Dokumenten zu finden, sind zwar verfügbar, kommen bei Rechnungen und der Vielzahl von Layout-Varianten sehr schnell an Grenzen („far from achieveable“).
Es folgt daher ein alternativer Ansatz, bei dem wir versuchen mithilfe von NLP-Verfahren (Natural Language Processing) Rechnungen als Texte inhaltlich zu erschließen. Wozu ist das nützlich?
- Um eine automatische Anomalieerkennung zu erhalten. Übrig bleiben anschließend nur einige wenige Rechnungen, die in einer manuellen Prüfung betrachtet werden sollten: „So etwas haben wir noch nie beschafft!“.
- Um automatisch Optimierungspotenzial und Skaleneffekte zu finden: „Hier beschaffen wir dezentral ähnliche Dinge bei mehreren Lieferanten!“
- Um als prüfende Person die interessanten Fälle aufgezeigt zu bekommen, ohne auf kleine Stichprobenmengen angewiesen zu sein (die „100-Prozent-Stichprobe“).
Wie funktioniert das?
NLP-Modelle sind leicht verfügbar geworden – auch für die deutsche Sprache. Hier wird nichts Neues entstehen müssen.
Es wird für eine Anomalieerkennung angenommen, dass die meisten Rechnungen in einem Unternehmen zu legitimen Geschäftstätigkeiten gehören: Wir können aus dem Gesamtbestand lernen, was „normal“ ist und darauf hoffen, dass ungewöhnliche Rechnungen als Anomalien auffallen müssten.
Um eine automatische Anomalieerkennung zu realisieren, muss die Semantik der Rechnungen in einer Form repräsentiert werden, die für Computer verarbeitbar ist. Dafür werden die Rechnungen zunächst vorverarbeitet. In diesem auch Preprocessing genannten Schritt werden die Bestandteile ohne Semantik, wie Satzzeichen oder Stoppwörter („und“, „oder“ …), entfernt. Weitere häufig verwendete Verfahren, wie das Stemming, finden im vorliegenden Fall keine Anwendung, weil durch spezifische Eigenschaften von Rechnungen kein oder nur ein vernachlässigbarer Mehrwert erbracht werden kann: Solche Verfahren eignen sich eher für Fließtexte mit ganzen Sätzen. Der nachfolgende Satz wurde beispielhaft transformiert:
[Ich kaufe mir ein Auto, um zur Arbeit zu fahren.]
[kaufe, Auto, Arbeit, fahr]
Bei Rechnungen stehen insbesondere in der Mitte einer Seite für die Semantik ausschlaggebende Begriffe. Das sind die Rechnungspositionen mit der Beschreibung der Produkt- oder Dienstleistung und ihren Eigenschaften. Sie erhalten vor der Bewertung eine Gewichtung, um in der späteren Analyse eine größere Relevanz zu haben. Anschließend folgen Verfahren, die sich mit der Repräsentation der Wörter in den Rechnungen beschäftigen.
Für eine Repräsentation dieser Semantik in für Computer verarbeitbarer Form eignen sich sogenannte Word Embeddings. Mithilfe dieser werden Wörter anhand des Kontextes, in dem sie genutzt werden, bewertet. Es werden also die regelmäßig umstehenden Wörter durch einen vorher festgelegten Text ermittelt und diese Beziehungen in Vektoren abgespeichert. Diese Vektoren repräsentieren anschließend genau ein Wort und zwei Vektoren sind sich besonders ähnlich, wenn sie im gleichen Kontext eingesetzt werden.
Mit diesen Vektoren können Rechenoperationen durchgeführt werden und der Ergebnisvektor ist in der Regel dem Vektor am nächsten, dessen zugehöriges Wort man als Mensch erwarten würde.
Beispiel: Vec(König) - Vec(Mann) + Vec(Frau) = Vec(Königin)
Häufig kommt es vor, dass man mithilfe der Vektoren nicht einzelne Wörter, sondern ganze Texte miteinander vergleichen möchte. Hierfür kann z. B. der Durchschnittsvektor von allen Vektoren einer Rechnung verwendet werden. Abschließend liegt zu jeder Rechnung ein die Semantik repräsentierender (hier) 300-dimensionaler Vektor vor.
Wie sieht das Ergebnis aus?
Versuchen wir es mit einem kleinen Set von ~ 250 Rechnungen, die an die viadee oder befreundete Unternehmen gestellt wurden.
Die 300-dimensionalen Vektoren können dimensionsreduziert werden, um das Ergebnis, wie in Abbildung 1, zu visualisieren. Bei den vorliegenden Daten wird deutlich, dass es eine große und wenige kleine Ansammlungen gibt. Die Rechnungen zu der großen Gruppe können als normal und die Rechnungen in den kleinen Gruppen als anomal betrachtet werden.
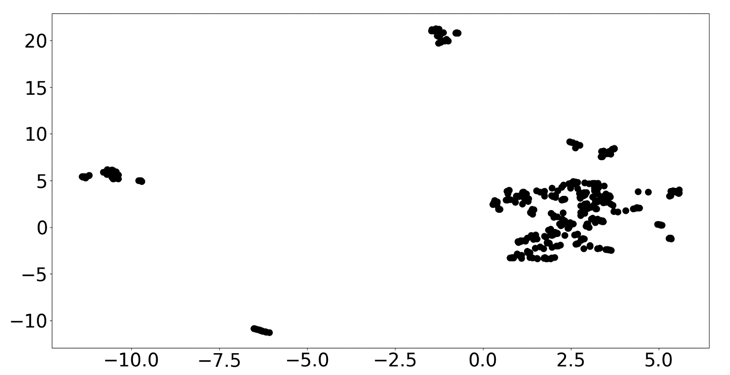
Es ergibt sich eine Landkarte der erhaltenen Rechnungen, die sich auch zur weiteren Automatisierung nutzen lässt, bspw. um zuständige Prozesse und Personen zu finden oder auch Warengruppen und Kostenstellen.
Als besonders fallen die Ausreißer auch durch Art und Aufbau und nicht nur durch die Rechnungspositionen auf. Es werden insbesondere Rechnungen isoliert, die eine andere Sprache als deutsch, einen Anhang oder Artikelpositionen zur Miete und nicht zum Kauf haben.
Für eine weitere Einschätzung der Verfahren werden Rechnungen zweier Firmen mit abweichenden Geschäftsfeldern gemischt – wir simulieren so überraschende Beschaffungsvorgänge. Danach wurde auf den Datensatz ein Autoencoder trainiert und angewendet: Mit dem Verfahren wird ein reconstruction error errechnet, den man als Seltenheitswert eines Dokuments verstehen kann.
Das Ergebnis ist in Abbildung 2 dargestellt und die beiden Firmen sind farblich voneinander abgetrennt.
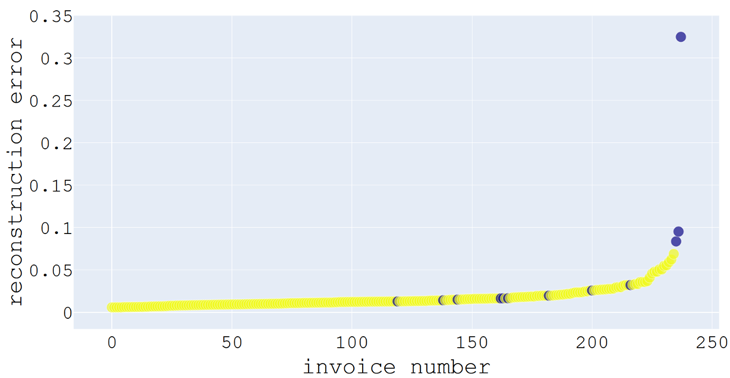
Die gelben Punkte stehen für die Rechnungen, die zum primär betrachteten Unternehmen gehören, und die Punkte in blau repräsentieren die Rechnungen des zweiten Unternehmens. Es ist deutlich, dass die zusätzlichen Rechnungen zwar nicht alle scharf als anomal erkannt werden können, jedoch eine starke Tendenz besteht. Keine der zusätzlichen Rechnungen gehört zur einfach reproduzierbaren Hälfte. Somit können die Verfahren beim vorliegenden Datensatz durchaus eine grobe Einschätzung bieten.
Ein Einzelfall macht es anschaulich: Der klare Ausreißer rechts oben ist die Rechnung eines Internet-Providers. Es gibt auch nur einen Internet-Provider im Datensatz und die dort verwendeten Begriffe passen nicht in die Geschäftsfelder der beiden Unternehmen. Diese Rechnung hat Seltenheitswert.
Was machen wir daraus?
Die Verfahren ermitteln schon mit wenigen Daten und geringem Entwicklungsaufwand gute Hinweise, welche Rechnungen potenziell anomal oder ähnlich zueinander sind. Sie stellen einen sinnvollen Classifier dar, der bei einer Vorauswahl helfen kann und für eine Unterstützung von Alltagsprozessen geeignet ist. Er ist flexibel einsetzbar und kann durch die Einsparung vieler manueller Prüfungen oder das Aufzeigen von Synergien Kosten senken.
Neben den Ergebnissen des Classifiers sollte bei einer Bewertung eine Verhältnismäßigkeit zwischen dem potenziellen Schaden einer Rechnung und dem Aufwand einer Betrachtung existieren, deswegen sollten Rechnungen mit hohem Rechnungsbetrag auch schon bei vergleichsweise niedriger Anomalie-Wahrscheinlichkeit manuell betrachtet werden. Rechnungen mit niedrigem Rechnungsbetrag hingegen eher selten – eine intelligente Prozesssteuerung.
Regelungen dieser Art mit künstlichem Augenmaß machen auch verschwörerischen Beschaffungsprozessen das Leben schwer, bei denen viele Rechnungsbeträge knapp unter den irgendwann bekannten Freigabe- oder Prüfungsgrenzen liegen.
In der Zukunft ist eine gezielte Extraktion der Rechnungspositionen geplant. Dann kann nicht nur auf den Rechnungen insgesamt, sondern einzeln auf den individuellen Themen der Rechnungspositionen und den vom Lieferanten abhängigen Informationen eine Invoice Intelligence realisiert werden.

Dieser Artikel stellt im Wesentlichen eine Zusammenfassung der Bachelor-Abschlussarbeit von Lennart Seeger (2020) im Fach Wirtschaftsinformatik an der WWU dar.
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



