
Camunda 8 can be operated both as Software-as-a-Service and self-managed. But how well does self-managed operation work and what pitfalls are there? In this article we will discuss this.
Notices:
- A German version of this article can be found here.
- This article was written before Camunda's release 8.2. Some aspects have changed afterwards.

The Basic Architecture
In Camunda 7, there are various options for deployment: Embedded Engine, Shared Engine, and Remote Engine. This has now been reduced to one option in version 8, which is closest to the Remote Engine of Camunda 7. While in Camunda 7 the code for executing tasks could still be deployed very closely with the Process Engine (Embedded Engine), this is no longer possible in Camunda 8. The Process Engine is now "only" responsible for executing the tasks in the correct order, but the code for executing the tasks is taken over by so-called job workers. These are operated separately from the Process Engine and communicate with it via a GRPC interface. So it doesn't matter whether the Process Engine is running in the cloud or on-premise.
By the way, the Process Engine in Camunda 8 is now based on the Zeebe engine developed by Camunda itself, and not on Camunda's further development of the original Activity Engine. Further information on the differences between Camunda 7 and 8 can be found in our blog post "Camunda 8 vs. Camunda 7: What are the differences?"
What options are available for using the Camunda 8 platform?
Camunda offers two basic options for using the Camunda 8 Platform: Software-as-a-Service (SaaS) or Self-Managed.
With the SaaS offering, Camunda operates the Process Engine and takes care of maintenance and scaling. As a customer, I only need to make sure I have a license suitable for my purpose; for so-called "low-volume automation", Camunda offers a usage-based Professional license, while for larger purposes, an Enterprise license must still be concluded as before. However, there is a 30-day trial version to get familiar with Camunda in the cloud. The customer is then only responsible for hosting the job workers responsible for executing the tasks in the processes. Since the communication of the job workers with the process engine is always initiated by the workers, no activation of incoming traffic in the company network in the firewall is necessary.
With the Self-Managed option, the customer is responsible for operation and maintenance and must also deal with all the topics associated with it, such as updates, scaling, security, etc. On the other hand, you have the greatest possible control over the system and the data stored in it. For non-productive use, you also have access to all functions at first and can therefore get to know the Camunda 8 platform in detail and without time pressure. Self-Managed means that you can operate Camunda 8 either in the private cloud, e.g. in your own Kubernetes cluster, or in the public cloud with a cloud provider of your choice.
What is to be done to deploy Camunda 8 self-managed?
Generally, there are three ways to deploy Camunda 8 self-managed: manually, with Docker or in Kubernetes. In this blog post, I will only briefly discuss the Docker option and then focus on deployment in Kubernetes.
DOCKER: QUICKLY SET UP SOMETHING LOCALLY!
The Docker route is only intended for local deployments for development purposes. For production use, Camunda recommends deployment in Kubernetes. Camunda's camunda-platform Github repository provides two docker-compose files. The file docker-compose-core.yaml contains a standard set of components to run Camunda 8:
- Zeebe (the process engine)
- Operate (the counterpart to Cockpit in Camunda 7)
- Tasklist (the tasklist, of course)
- Connectors (required for the use of special types of service tasks that can be configured via the UI)
- Elasticsearch (Camunda 8's database)
- Kibana (for data visualization)
The file docker-comopse.yaml also contains the following additional components for process analysis, as well as components for authentication and authorization including single sign-on for the local setup.
- Optimize (for process analysis)
- Identity (Camunda component for single sign-on)
- Keycloak (freely available identity provider used by Camunda)
- PostgreSQL (database for Keycloak)
KUBERNETES: WEAR A HELMet IN PRODUCTION FOR BETTER RESULTS!
For production use, Camunda recommends deploying to a Kubernetes cluster using Helm Charts. Helm is a kind of package manager for Kubernetes.
Camunda officially provides Helm Charts in their Github repository camunda-platform-helm and currently officially supports the Kubernetes offerings from AWS, Google and Azure as well as the Red Hat OpenShift distribution. We have also successfully installed deployments on a RKE2 distribution from Rancher.
helm repo add https://helm.camunda.io
helm repo updateNow you can install Camunda 8 with the following command, customizing the deployment via a values.yaml file:
helm install -f <values.yaml> <name of deployment in kubernetes> camunda/camunda-platform
Example:
helm install -f values.yaml camunda-platform-8 camunda/camunda-platform
After updating the Helm Charts from Camunda, the update can be retrieved again via helm repo update.
The following graphic shows the components that must be operated in a self-managed deployment.
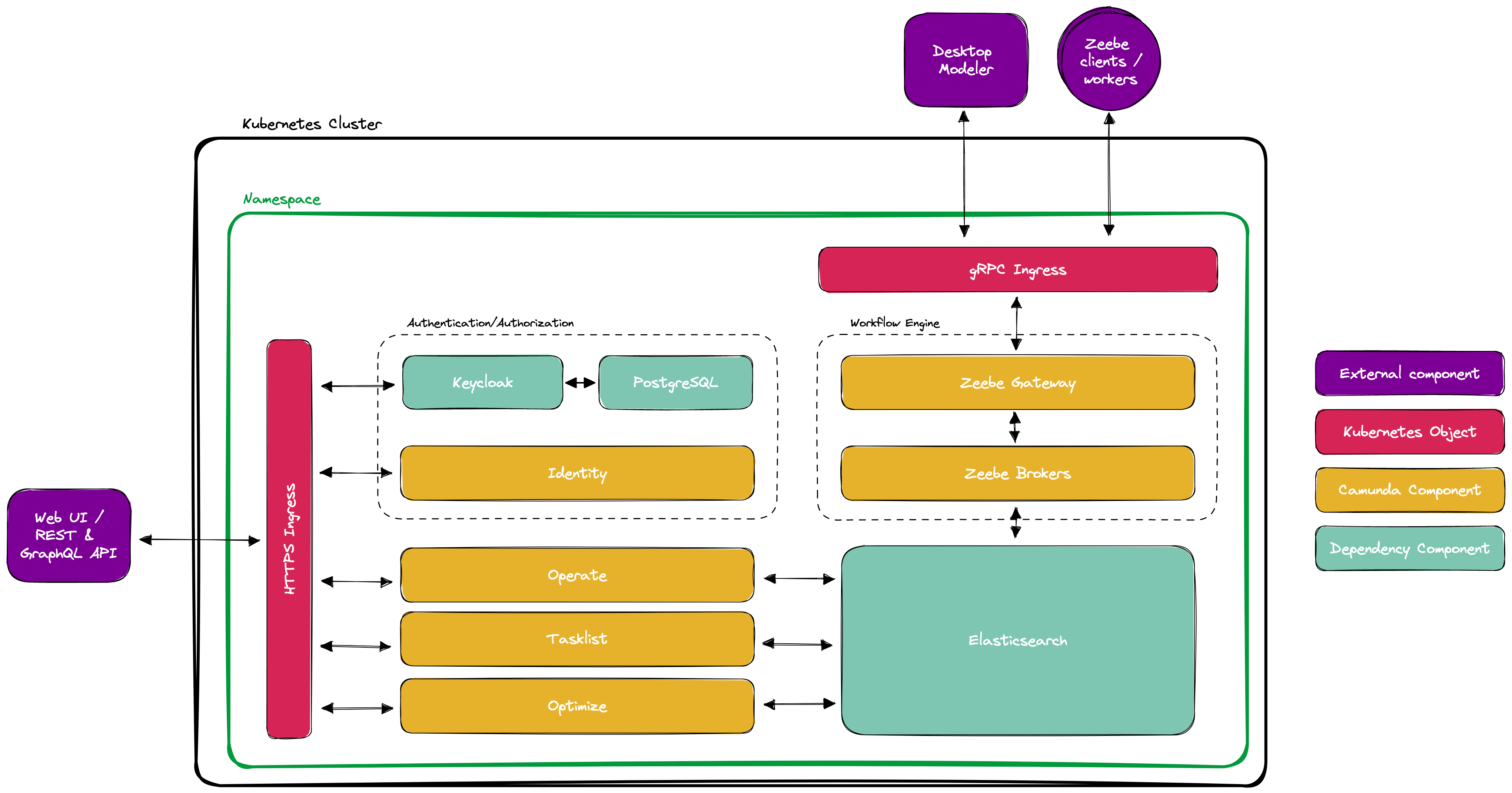
(Source: https://docs.camunda.io/docs/self-managed/platform-deployment/helm-kubernetes/deploy/)
As mentioned in the section about Docker, besides the Camunda components, other dependencies are also installed. On the one hand, Elasticsearch for data storage in Camunda 8, as well as the freely available Identity Provider Keycloak, which Camunda Identity requires, and a database required by this, here PostgreSQL. In addition, here are explicitly mentioned the two required Ingress configurations, since for Camunda 8 not only HTTP Ingresses for the web UIs, as well as REST and GraphQL APIs are necessary, but also a gRPC Ingress for the communication of the Job Worker and Modeler with Zeebe. In order to use the gRPC Ingress, the Ingress Controller used in the Kubernetes Cluster must support gRPC, such as the NGINX Ingress Controller.
TRAPS IN SELF-MANAGED DEPLOYMENT
Configuration is done via a values.yaml file, which can be used to configure a Kubernetes deployment via Helm. Both configurations for deployment, such as resource allocation and limits for pods, number of replicas, security settings for running pods, ingress URLs for individual services, as well as configurations for the application itself, such as configuring the partitioning of data in the Zeebe cluster, can be stored.
When deploying, there are some traps that should be mentioned here along with possible solutions to make getting started with self-managed hosting easier.
(STILL) NO OUT-OF-THE-BOX AUTHENTICATION AT THE ZEEBE GATEWAY
Currently, the Helm chart does not provide authentication for traffic at the Zeebe gateway. While the Zeebe gateway is protected by an OAuth-based authentication in the SaaS version, the Zeebe gateway comes without any out-of-the-box authentication when deployed via the Helm chart. There is the possibility of developing a so-called interceptor and deploying it with the Zeebe gateway, e.g. via an init container. However, this requires manual implementation effort. However, one could expect that at least one interceptor for OAuth is delivered and can be installed out-of-the-box, since OAuth credentials can already be created for other applications in Camunda Identity. Looking at the current Github issues of Camunda, it looks like this will be done in version 8.2.
KEYCLOAK IS MANDATORY
In Camunda 8, the Identity component is responsible for authentication and authorization. Currently, Identity only supports Keycloak as an identity provider, and an existing Keycloak instance can be used. However, if you already have a different identity provider in use, it must be set up in Keycloak as an identity provider so that you are forced to run Keycloak in addition to your existing identity provider for Camunda 8. An, in my opinion, unpleasant circumstance, as the necessary authentication and authorization scenarios should be able to be implemented directly with all OAuth-compatible identity providers.
GRPC COMMUNICATION WITH TRICKS
The job workers and the Camunda Modeler communicate with the Zeebe gateway through the gRPC Ingress. There are also some small obstacles that I would like to mention here to save someone the search for the solution.
Often, a self-signed certificate is used in internal Kubernetes clusters. In this case, the certificate must be explicitly specified for all communication from job workers or the modeler in order to establish a connection. For zbctl, the tool for communication with Zeebe via the command line, the parameter --certPath <path-to-certificate> or alternatively the environment variable ZEEBE_CA_CERTIFICATE_PATH=<path-to-certificate> helps. The respective gRPC clients used for the implementation of the job workers also have corresponding parameters that can be taken from the respective documentation.
The modeler refuses to work by default with self-signed certificates. However, if it is started with the parameter --zeebe-ssl-certificate=<path-to-certificate>, it also works there. Sometimes the modeler still refuses to cooperate over a gRPC Ingress if, for example, it runs over the standard HTTS port, so the URL is, for example, https://zeebe.my-kubernetes.com and then claims that the URL does not point to a running Zeebe cluster. However, if the port is specified explicitly, i.e. in the example here https://zeebe.my-kubernetes.com:443, it also works with the modeler.
WEB MODELER STILL IN BETA
The web modeler, which is integrated in the SaaS solution, is currently only available in a beta version and only for customers with an enterprise license for the self-managed deployment and is not yet released for production use. Therefore, only the desktop modeler must be used here. This will change with version 8.2, however, the web modeler will still only be available with an enterprise license.
Virtual Memory CONSUMPTION of Elasticsearch
Elasticsearch uses memory mapping to access indices and requires a correspondingly large virtual address space. Since this is often larger than the standard values set in Linux distributions, an Out-Of-Memory error occurs when Elasticsearch starts. Since the settings in the host system are used as the starting point for the pods in Kubernetes clusters, either the address space can be increased through an init-container or memory mapping can be disabled in addition to increasing the values in the host. To increase the address space through an init-container, a corresponding section must be added to the values.yaml.
For this approach it is necessary that pods are allowed to run in privileged mode. If this is not allowed in the Kubernetes cluster, this approach cannot be used.
As a second option, memory mapping can be disabled. However, for use in production with high load, it is strongly recommended to increase the virtual address space accordingly. The following section in the values-yaml can be used to disable memory mapping:
Conclusion
Setting up a self-managed Camunda 8 cluster is achievable with the information and tools provided by Camunda. However, the effort and complexity involved in operating it should not be underestimated. There are also some teething problems, which is not surprising given the relatively young age of Camunda 8. Some of these issues will be addressed in the 8.2 release. Camunda is also constantly expanding and improving its documentation and tools for self-managed deployment, which is a very good sign in my opinion. Therefore, if there is no compelling reason for a self-managed deployment, we currently recommend using the SaaS offering, as it is (still) the more complete package and allows you to focus entirely on process design and implementation without having to worry about the infrastructure aspect.
Back to blog overview

