
Camunda 8 kann sowohl als Software-as-a-Service und Self-Managed betrieben werden. Aber wie gut klappt Betreiben in der Self-Managed-Variante und welche Fallstricke gibt es dabei? In diesem Artikel gehen wir darauf ein.

Die grundsätzliche Architektur
Bei Camunda 7 gibt es verschiedene Möglichkeiten für ein Deployment: Embedded Engine, Shared Engine und Remote Engine. Dies hat sich mit Version 8 nun auf eine Option reduziert, die der Remote Engine von Camunda 7 am nächsten kommt. Während bei Camunda 7 der Code zur Ausführung der Tasks noch sehr eng mit der Process Engine deployed werden konnte (Embedded Engine), ist dies bei Camunda 8 nun nicht mehr möglich. Die Process-Engine ist "nur noch" für die Ausführung der Tasks in der korrekten Reihenfolge zuständig, der Code zur Ausführung der Tasks wird jedoch von so genannten Job Workern übernommen. Diese werden getrennt von der Process-Engine betrieben und sprechen mit dieser über eine GRPC-Schnittstelle. Damit ist es auch grundsätzlich egal, ob die Process-Engine in der Cloud oder on-premise läuft.
Die Process-Engine basiert in Camunda 8 im Übrigen nunmehr auf der von Camunda selbstentwickelten Zeebe-Engine und nicht mehr auf Camundas Weiterentwicklung der ursprünglichen Activity-Engine. Weitere Information zu den Unterschieden zwischen Camunda 7 und 8 findet sich in unserem Blogbeitrag "Camunda 8 vs. Camunda 7: Wo liegen die Unterschiede?".
Welche Optionen für eine Nutzung der Camunda 8 Plattform gibt es?
Camunda bietet grundsätzlich zwei verschiedene Möglichkeiten an die Camunda 8 Platform zu nutzen: Als Software-as-a-Service (SaaS) oder Self-Managed.
Beim SaaS Angebot betreibt Camunda die Process Engine und kümmert sich damit auch um die Wartung und die Skalierung. Als Kunde muss ich mich nur darum kümmern, dass ich eine Lizenz passend zu meinem Einsatzzweck habe, für so genannte "low-volume Automatisierung" bietet Camunda eine nutzungsbasierte Professional-Lizenz an, für größere Einsatzzwecke ist wie bisher eine Enterprise-Lizenz abzuschließen. Es gibt aber eine 30-Tage-Testversion, um sich mit Camunda in der Cloud vertraut machen zu können. Der Kunde ist dann lediglich für das Hosting der Job Worker verantwortlich, die für die Abarbeitung der Tasks in den Prozessen verantwortlich sind. Da die Kommunikation der Job Worker mit der Process Engine immer von der Workern initiiert wird, ist keine Freischaltung von eingehendem Traffic in das Unternehmensnetzwerk in der Firewall nötig.
Bei der Self-Managed Variante ist der Kunde für den Betrieb und die Wartung zuständig und muss sich damit auch mit allen Themen die damit einhergehen, wie z.B. Update, Skalierung, Security, etc. auseinandersetzen. Andererseits hat man dabei die größtmögliche Kontrolle über das System und die darin gespeicherten Daten. Für den nicht-produktiven Einsatz hat man auch erstmal Zugriff auf alle Funktionen und kann sich somit ausgiebig und ohne Zeitdruck mit der Camunda 8 Plattform vertraut machen. Self-Managed bedeutet, dass man Camunda 8 entweder in der Private-Cloud, also z.B. im eigenen Kubernetes Cluster betreiben kann oder in der Public-Cloud beim einem Cloud-Provider der Wahl.
Was ist zu tun, um Camunda 8 Self-Managed zu deployen?
Generell gibt es drei Möglichkeiten Camunda 8 self-managed zu deployen: manuell, per Docker oder in Kubernetes. In diesem Blogeintrag gehe ich nur kurz auf die Variante per Docker ein und fokussiere mich dann auf das Deployment in Kubernetes.
Docker: Schnell mal eben lokal was hochziehen!
Der Weg über Docker ist nur für lokale Deployments zu Entwicklungszwecken gedacht. Für den Einsatz in Produktion empfiehlt Camunda das Deployment in Kubernetes. In dem Github-Repository camunda-platform von Camunda werden zwei docker-compose Dateien zur Verfügung gestellt. Die Datei docker-compose-core.yaml beinhaltet ein Standardset an Komponenten, um Camunda 8 zu betreiben:
- Zeebe (die Process Engine)
- Operate (das Pendant zu Cockpit in Camunda 7)
- Tasklist (die Tasklist halt)
- Connectors (benötigt für die Nutzung spezieller Ausprägungen von Service Tasks, die über die UI konfiguriert werden können)
- Elasticsearch (die Datenbank von Camunda 8)
- Kibana (zur Visualisierung der Daten)
Die Datei docker-comopse.yaml beinhaltet zusätzlich zu den oben gelisteten Komponenten noch folgende weitere, mit denen sich Prozessanalysen durchführen lassen. Außerdem kommen Komponenten für die Themen Authentifizierung und Autorisierung inkl. Single-Sign-On für das lokale Setup hinzu.
- Optimize (zur Prozessanalyse)
- Identity (Camunda Komponente für Single-Sign-On)
- Keycloak (von Camunda verwendeter, frei verfügbarer Identity Provider)
- PostgreSQL (Datenbank für Keycloak)
Kubernetes: In der Produktion besser Helm tragen!
Für den Einsatz in der Produktion empfiehlt Camunda das Deployment auf einem Kubernetes Cluster über Helm Charts. Helm ist eine Art Paketmanager für Kubernetes.
Camunda stellt offiziell Helm Charts in Ihrem Github Repository camunda-platform-helm zur Verfügung und unterstützt aktuell offiziell die Kubernetes Angebote von AWS, Google und Azure sowie der Red Hat OpenShift Distribution. Wir haben aber auch u. a. bereits erfolgreich Deployments auf einer RKE2-Distribution von Rancher installiert.
Um das Helm Repository einzurichten fügt man es zunächst hinzu:
helm repo add https://helm.camunda.iohelm repo updateNun kann man Camunda 8 über folgenden Befehl installieren, wobei das Customising des Deployments über eine values.yaml-Datei erfolgt:
helm install -f <values.yaml> <Name des Deployments in Kubernetes> camunda/camunda-platformBeispiel:helm install -f values.yaml camunda-platform-8 camunda/camunda-platformNach einem Update der Helm-Charts von Camunda lässt sich das Update einfach wieder über helm repo update beziehen.
In der folgenden Grafik sind die Komponenten abgebildet, die man bei einem self-managed Deployment betreiben muss.
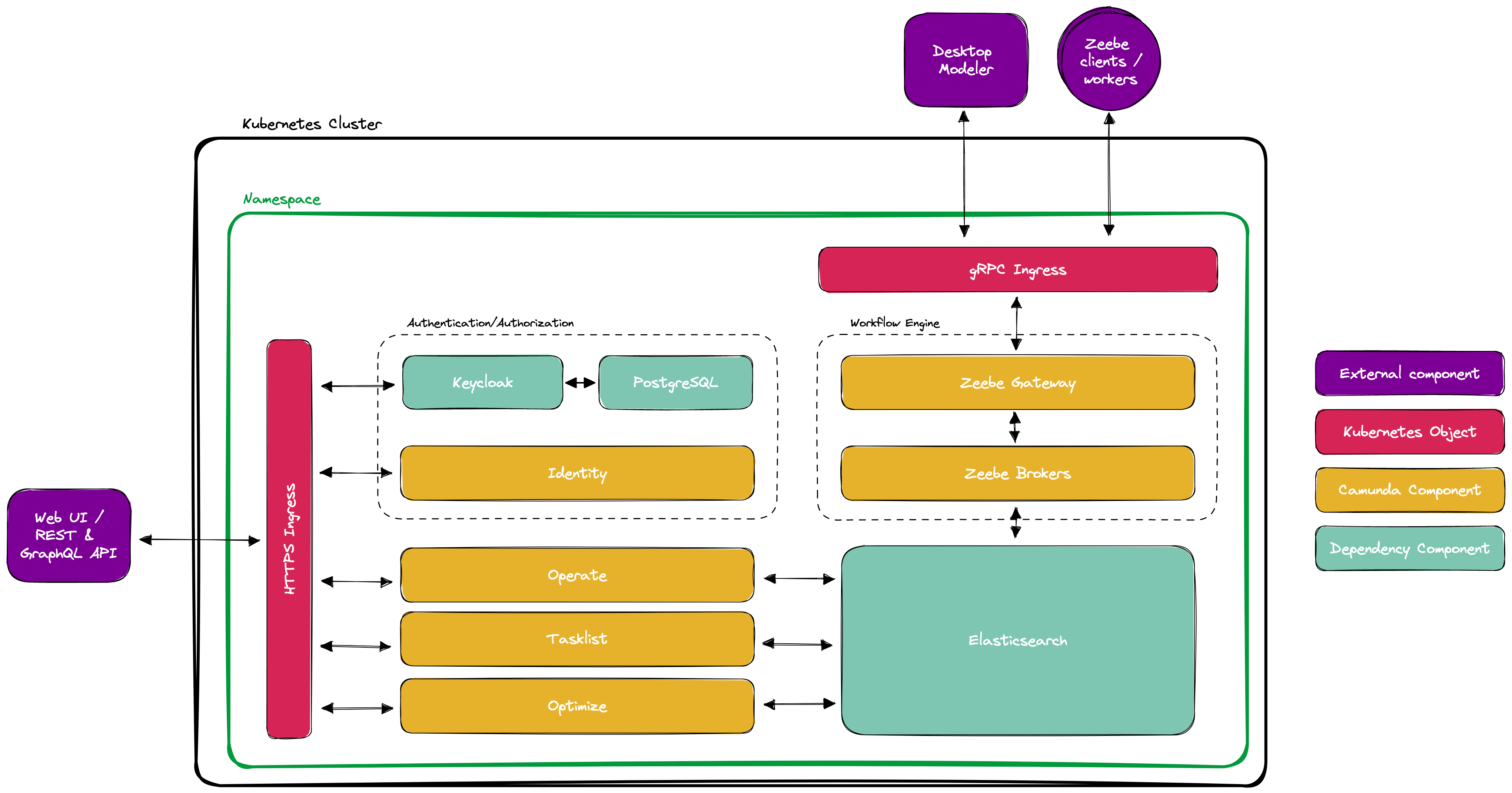
(Quelle: https://docs.camunda.io/docs/self-managed/platform-deployment/helm-kubernetes/deploy/)
Wie bereits im Abschnitt zu Docker erwähnt, werden neben den Camunda Komponenten auch weitere Abhängigkeiten installiert. Zum einen Elasticsearch für die Datenhaltung in Camunda 8, sowie der frei verfügbare Identity Provider Keycloak, den Camunda Identity voraussetzt, und eine von diesem benötigte Datenbank, hier PostgreSQL. Des Weiteren sind hier noch explizit die zwei benötigten Ingress-Konfigurationen erwähnt, da für Camunda 8 nicht nur HTTP-Ingresses für die Web-UIs, sowie REST- und GraphQL-APIs nötig sind, sondern auch ein gRPC-Ingress für die Kommunikation der Job Worker und Modeler mit Zeebe. Um den gRPC-Ingress nutzen zu können, muss der im Kubernetes Cluster verwendete Ingress-Controller gRPC unterstützen, wie z. B. der NGINX-Ingress-Controller.
Fallstricke beim Self-Managed Deployment
Die Konfiguration erfolgt über eine values.yaml-Datei, mit der man ein Kubernetes Deployment via Helm konfigurieren kann. Dabei lassen sich sowohl Konfigurationen zum Deployment hinterlegen, wie z.B. Ressourcenzuweisungen und -limits für Pods, Anzahl jeweiliger Replikas, Sicherheitseinstellungen für die laufenden Pods, Ingress URLs für die einzelnen Services, als auch Konfigurationen der Anwendung selber, wie z. B. die Konfiguration der Partitionierung der Daten im Zeebe Cluster.
Beim Deployment gibt es einige Fallstricke, die hier einmal samt Lösungsmöglichkeiten erwähnt werden sollen, um den Einstieg ins Self-Managed-Hosting zu erleichtern.
(Noch) keine out-of-the-box-Authentifizierung am Zeebe-Gateway
Aktuell bringt das Helm Chart noch keine Authentifizierung für den Traffic am Zeebe-Gateway mit. Während in der SaaS-Variante das Zeebe-Gateway über eine OAuth-basierte Authentifizierung geschützt ist, kommt das Zeebe-Gateway durch ein Deployment über das Helm-Chart ohne jegliche out-of-the-box-Authentifizierung daher. Es gibt zwar die Möglichkeit einen sogenannten Interceptor selbst zu entwickeln und mit dem Zeebe-Gateway z.B. über einen Init-Container zu deployen. Dies benötigt jedoch manuellen Implementierungsaufwand. Man könnte jedoch erwarten, dass zumindest ein Interceptor für OAuth mitgeliefert wird und out-of-the-box installiert werden kann, da man bereits OAuth-Credentials für andere Anwendungen in Camunda Identity erstellen kann. Schaut man in die aktuellen Github issues von Camunda scheint es so auszusehen, als wenn dies in Version 8.2 nachgeholt wird.
Keycloak wird zwingend benötigt
In Camunda 8 ist die Komponente Identity für die Authentifizierung und Autorisierung zuständig. Aktuell unterstützt Identity aber ausschließlich Keycloak als Identity Provider, wobei auch eine bereits bestehende Keycloak-Instanz verwendet werden kann. Hat man jedoch einen anderen Identity Provider bereits im Einsatz, muss dieser in Keycloak als Identity Provider eingerichtet werden, so dass man zusätzlich zu seinem bestehenden Identity Provider für Camunda 8 zwangsläufig auch Keycloak betreiben muss. Ein meiner Meinung nach unschöner Umstand, da sich die nötigen Authentifizierungs- und Autorisierungsszenarien mit allen OAuth-kompatiblen Identity Providern direkt umsetzen lassen sollten.
gRPC Kommunikation mit Tücken
Die Job Worker sowie der Camunda Modeler kommunizieren über den gRPC Ingress mit dem Zeebe-Gateway. Dabei gibt es auch einige kleine Hindernisse, die ich hier erwähnen möchte, um dem einen oder anderen die Suche nach der Lösung zu ersparen.
Häufig wird bei internen Kubernetes Clustern ein selbst-signiertes Zertifikat eingesetzt. In diesem Fall muss das Zertifikat explizit bei sämtlicher Kommunikation von Job Workern oder dem Modeler angegeben werden, um eine Verbindung aufbauen zu können. Bei zbctl, dem Tool zu Kommunikation mit Zeebe über die command line hilft dabei der Parameter --certPath <Pfad-zum-Zertifikat> oder alternativ die Umgebungsvariable ZEEBE_CA_CERTIFICATE_PATH=<Pfad-zum-Zertifikat>. Die jeweiligen gRPC Clients, die bei der Umsetzung der Job Worker zum Einsatz kommen besitzen auch jeweils entsprechende Parameter, welche aus der jeweiligen Dokumentation entnommen werden können.
Der Modeler verweigert standardmäßig seinen Dienst bei selbst-signierten Zertifikaten. Startet man ihn jedoch mit dem Parameter --zeebe-ssl-certificate=<Pfad-zum-Zertifikat> funktioniert es auch da. Manchmal verweigert der Modeler weiterhin die Zusammenarbeit über einen gRPC-Ingress, wenn z. B. dieser z. B. über den Standard HTTS-Port läuft, die URL also z. B. https://zeebe.my-kubernetes.com lautet und behauptet dann, dass die URL nicht auf ein laufendes Zeebe-Cluster zeigt. Gibt man den Port jedoch explizit an, also im Beispiel hier https://zeebe.my-kubernetes.com:443, so klappt es auch mit dem Modeler da.
Web-Modeler noch in Beta
Der Web-Modeler, welcher in der SaaS Lösung integriert ist, ist beim Self-Managed-Deployment bisher nur in einer Beta und nur für Kunden mit Enterprise-Lizenz verfügbar und auch nicht für den produktiven Einsatz freigegeben. Hier muss daher noch ausschließlich mit dem Desktop Modeler gearbeitet werden. Dies wird sich mit Version 8.2 aber ändern. Da verlässt der Web-Modeler den Beta-Status, ist aber weiterhin nur mit Enterprise-Lizenz nutzbar.
Virtual-Memory-Hunger von Elasticsearch
Elasticsearch verwendet für einen Zugriff auf Indizes memory mapping und benötigt eine einen entsprechend großen virtuellen Adressraum. Da dieser häufig größer als die üblicherweise gesetzten Standardwerte in Distributionen von Linux ist, kommt es beim Start von Elasticsearch zu einem Out-Of-Memory Fehler. Da in Kubernetes Clustern die Einstellungen im Hostsystem als Ausgangspunkt für die Pods gelten, kann neben einer Erhöhung der Werte im Host, entweder eine Erhöhung des Adressraums über einen Init-Container erfolgen oder das Memory Mapping abgeschaltet werden.
Um den Adressraum über einen Init-Container zu erhöhen muss in der values.yaml eine entsprechende Abschnitt hinzugefügt werden:
Für diesen Ansatz ist es aber erforderlich, dass Pods im privilegierten Modus laufen dürfen. Sollte dies im Kubernetes Cluster nicht erlaubt sein, ist dieser Ansatz nicht verwendbar.
Als zweite Möglichkeit kann das Memory Mapping abgeschaltet werden. Für den Einsatz in Produktion mit hoher Last wird aber dringend empfohlen, den virtuellen Adressraum entsprechende zu erhöhen. Über folgenden Abschnitt in der values-yaml kann das Memory Mapping abgeschaltet werden:
Fazit
Das Aufsetzen eines Self-Managed Camunda 8 Clusters ist mit den durch Camunda zur Verfügung gestellten Informationen und Hilfsmittel zu bewerkstelligen. Der dahinter stehende Aufwand und die damit einhergehende Komplexität im Betrieb ist jedoch nicht zu unterschätzen. Des Weiteren gibt es noch einige Kinderkrankheiten, was aber aufgrund des noch recht jungen Alters von Camunda 8 nicht verwunderlich ist. Einige Themen werden schon im Release 8.2 adressiert. Des Weiteren erweitert und verbessert Camunda stetig seine Dokumentation und Werkzeuge für ein Self-Managed Deployment. Dies ist meiner Meinung nach ein sehr gutes Zeichen. Schließlich kommen nicht für alle Kunden ein SaaS Angebot in Frage.
Sollte es keinen triftigen Grund für ein Self-Managed Deployment geben, empfehlen wir aktuell die Nutzung des SaaS-Angebotes, da dies (noch) das rundere Paket ist und man den Infrastrukturaspekt erstmal ausklammern und sich komplett auf die Prozessausgestaltung und -implementierung fokussieren kann.
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



