
Camunda has introduced the External Task Handler Pattern in Camunda 7 Platform some time ago. It is a mechanism that reverses the execution service tasks from a push to a pull principle, i.e. the process engine is no longer responsible for the actual execution, which is different to Java Delegates. Instead, (external) tasks are provided for individual topics that an External Task Handler can fetch, process and then finally complete. This procedure already is explained in more details in a previous blog post. Furthermore, the differences in the error and retry behavior between External Task Handlers and Java Delegates are also explained another blog post. Finally, the goal of this article is to explain how to store complex data from an External Task Handler in the process context and what to care about in contrast to Java Delegates. A runnable example application, which demonstates the procedure, can be found on GitHub.
A German version of this blog post can be found here.
Read and write complex data
Java Delegates
With the commonly used type of implementation for service tasks Java Delegates, software developers do not have to worry about storing complex objects, as long as the process application has a sufficiently configured Jackson ObjectMapper, e.g. for a legible representation of date and time formats, and no unusual inheritance structures are used for the data types. Usually, most things already works out-of-the-box. Data can be read or created arbitrarily from the execution object and is serialized in the process context at the end of the transaction:
Note: this is only a simplified example. It is highly recommended to not store any foreign data-type in the process context!
As a result, the Customer data object in the process context is serialized as Json:
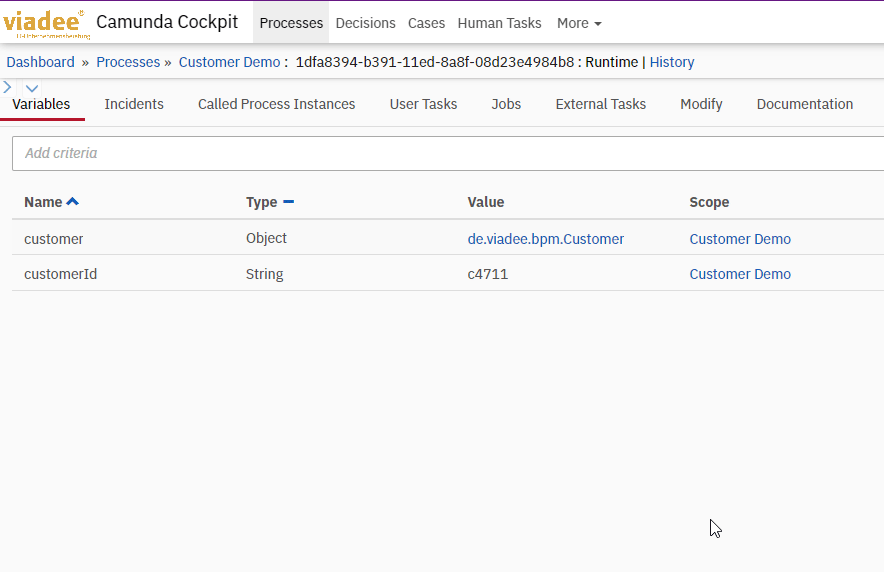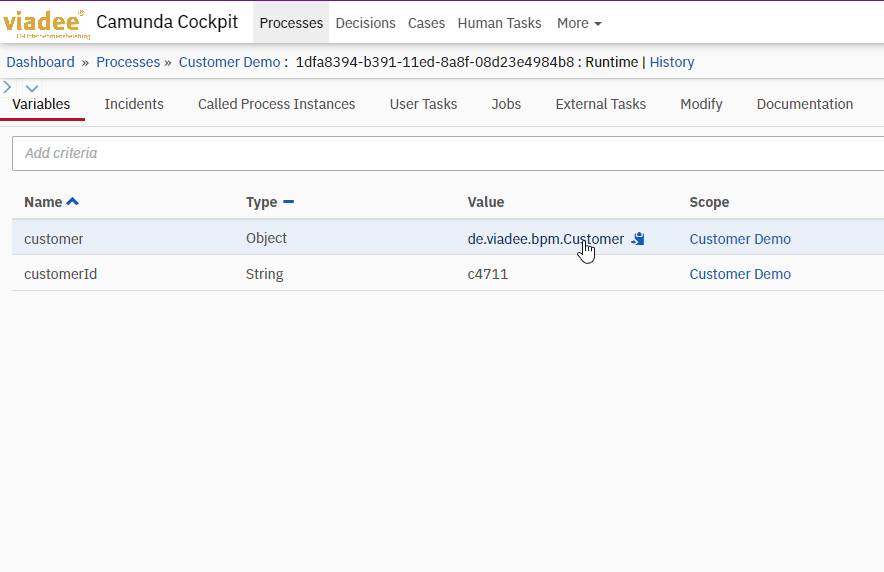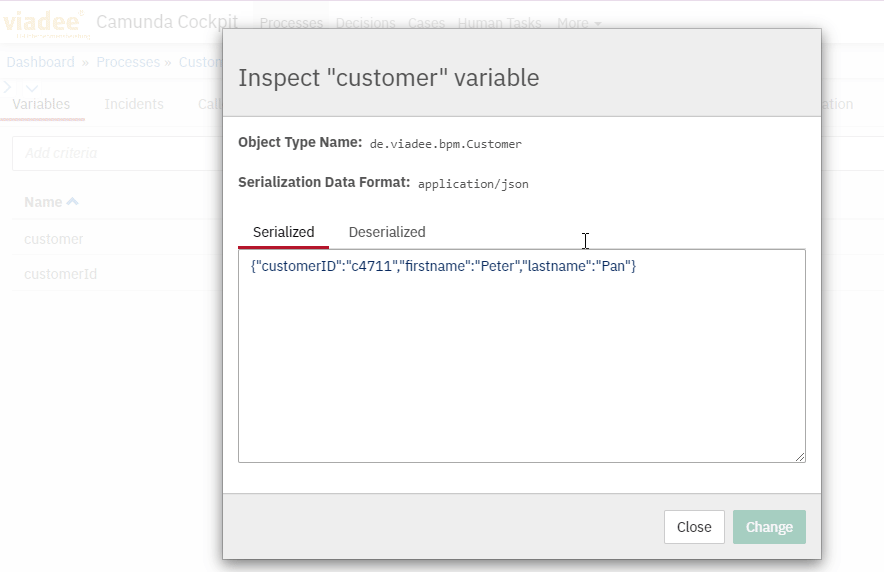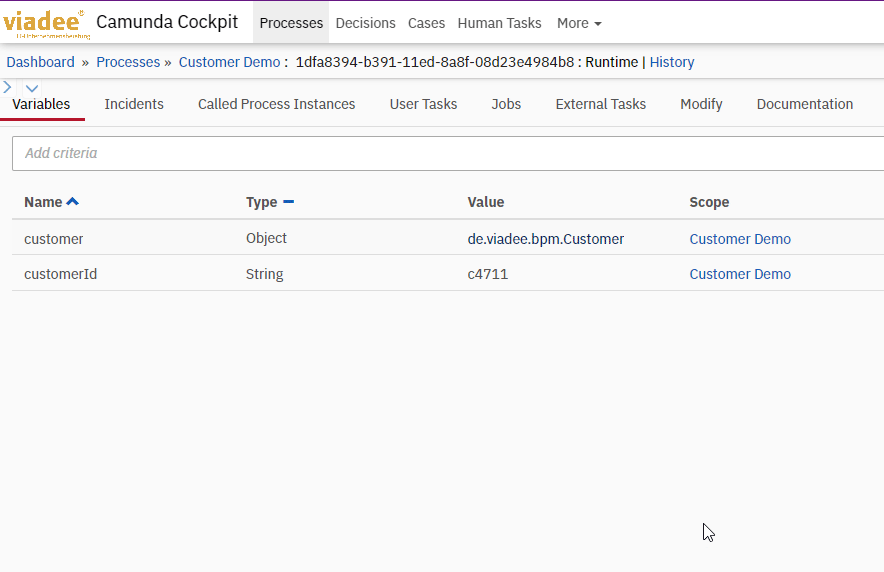
The execution object is also used in order to read values from either primitve or complex data objects in the process context.
External-Tasks
The core idea of the External Task Pattern is that the process engine only orchestrates processes and ensures the correct flow of a process instance, but does not execute any business logic like calling web services or the like, and finally no data has to be processed by the engine itself. This makes it possible to distribute the actual execution to decentralized applications, of which the process engine does not need to know any technical detail. In technical terms, there is usually not any Domain Object, e.g. customer type in this example, on the classpath of exactly this application which provides the process engine. As a result, only generic structures, such as Json, are permitted in the process context The (de-)serialization of complex data becomes part of the External Task Handlers.
This behavior is shown by the following example. Primitive data types, such as the customerId, can still be read as usual from the process context. For writing the customer object, it is necessary to manually serialize it before the correponding Json-string is converted into a (Camunda) Json-value:
Note: a try-catch-block is missing in this example, which aim would be to catch and handle possible errors caused by serialization and to avoid getting stucked in an endless loop. There is a blog post that explains how the error and retry behavior can be automated for External Task Handlers.
As a result, there is now a corresponding Json object in the process context, which has the same content as the result of the previous Java Delegate, but it is no longer of type Object, but of type Json:
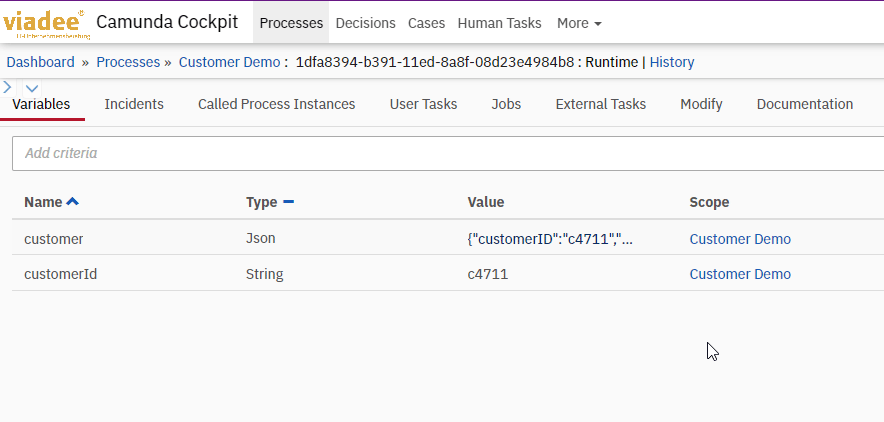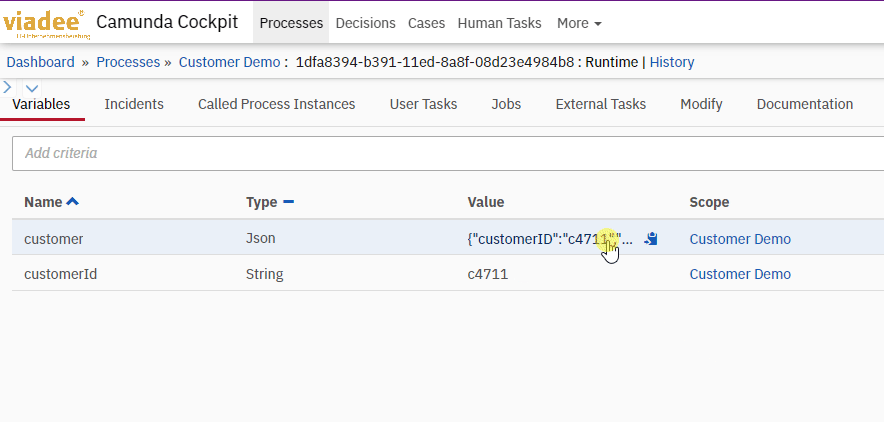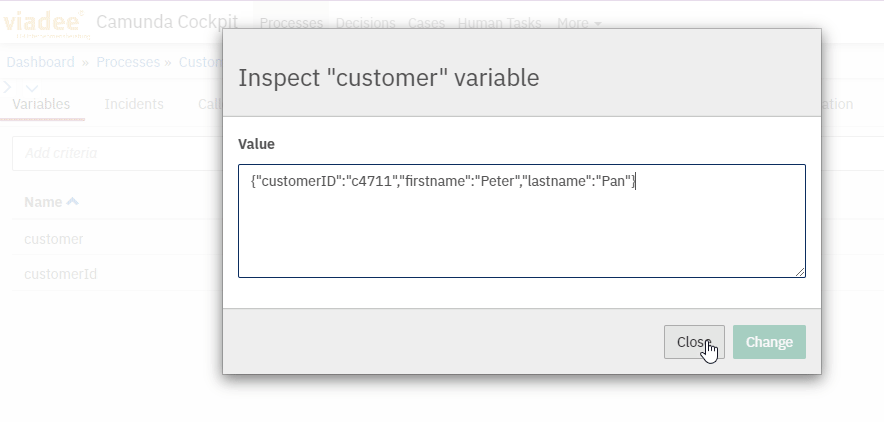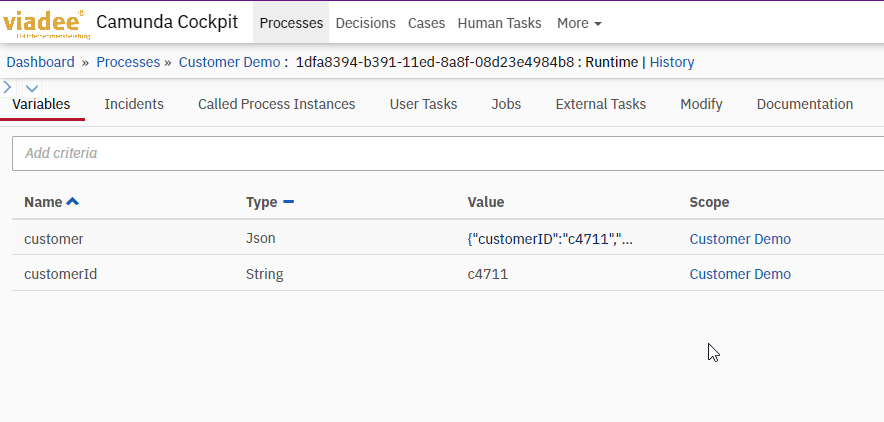
When reading complex objects in External Tasks, the serialized Json values need to be converted on the client side as well. For this purpose, the library for serialization and deserialization is used again:
Encapsulate process context wrapper and (de-)serialization
The procedure described so far shows the differences between Java Delegates and External Tasks when storing data in the process context. However, it is advisable to encapsulate the logic for generating Json data, so this does not have to be done individually in each External Task Handler. In the example on GitHub, the corresponding code is shifted into the process context object, which enables simple handling of complex data, even in Json format. As a wrapper-class the process context encapsulates all necassary methods that are needed in order to properly read and write data or even type-castings. Specialized methods directly return expected types, e.g. a customer-object (see below). For more details on the subject of "process context", read the following blog post (German only).
The JsonDataType interface provides a default method toJson(), which is used to convert any data type into a Json-string (that implements it) with a single method call. The real serialization as well as any error behavior are part of this excapsulating method. This leads to the business logic in the External Task Handler staying completly free of any technical detail regarding (de-)serialization and error behavior:
The Customer-Type and the respective interface look like this:
Further, specialized methods can be used to directly access data types. Reading and transforming data into domain objects happens as part of the JsonDataType-interface. Additionally, the process context might be designed in a manner, so that it can be used for Java-Delegates as well as with External Task Handlers. This is very usefull during a potential transition phase, when there are both: Java-Delegates and External Tasks within one process application.
The business logic is completely separated from any technical detail regarding (de-)serialization and error behavior:
Conclusion
The conversion of Java Delegates to External Tasks requires a different approach to complex data structures. Serialization and deserialization are no longer handled by the process engine, since it exists decoupled from the actual business logic. For this reason, these steps must be taken client-side in the External Task Handlers - with all the consequences that this entails for developers. However, by using an intelligent structure of a ProcessContext class as a wrapper for the data and possibly a common interface for the data types that are stored as variables, the effort for (de-)serialization can be centralized and kept as low as possible. If there is already a wrapper class for accessing process variables, this can be extended or restructured accordingly, so that the conversion to External Tasks, resp. Json data, has very little impact on the actual business logic, since the data types remain unchanged. Another advantage of decoupling the mechanisms for serialization and deserialization is the reuse over several External Task Handlers and data types, so that e.g. the error handling in the form of a try-catch construct does not have to be copied into every handler.
Back to blog overview

