

Eine Prozessapplikation benötigt wie jede andere Software auch Variablen, um zu funktionieren. In Variablen werden Referenzen auf Geschäftsobjekte oder Daten transportiert, die Prozesse „zum Leben“ brauchen. Darüber hinaus werden automatisiert (per Entscheidungstabelle oder Service-Aufruf) oder manuell getroffene Entscheidungen in Variablen abgelegt, um den Prozessfluss steuern zu können. Werkzeuge wie die Process Engine von camunda bieten dazu Möglichkeiten, den Prozessdatenhaushalt (auch Prozesskontext genannt) zu verwalten. In camunda ist dieser Datenhaushalt ähnlich wie ein Key-Value Store realisiert. Zur Laufzeit einer Prozessinstanz werden Variablen hinzugefügt, gelesen und ggfs. aktualisiert. Der Zugriff auf die Daten passiert sowohl aus dem Java-Code (z. B. in Delegates oder Listenern) sowie auch aus dem Prozessmodell heraus (z. B. per Expression an einem Gateway bzw. den ausgehenden Sequenzflüssen). Das Verwalten des Datenhaushalts einer Prozessapplikation bringt aufgrund des dynamischen Charakters des Key-Value Stores und des „hybriden Zugriffs“ auf Datenobjekte einige Herausforderungen mit sich, auf die im Folgenden eingegangen werden soll.
Naiver Ansatz zum Zugriff auf Variablen
Die einfachste Möglichkeit, auf Variablen zuzugreifen, ist direkt den Key als String zu verwenden. camunda bietet hierzu Methoden an, mit denen auf den Prozesskontext zugegriffen werden kann. Konkret kann innerhalb eines Delegates oder eines Listeners überexecution.setVariable("key", new Schaden()); eine Variable gesetzt und über execution.getVariable("key"); gelesen werden. Jeder erfahrene Entwickler und Verfechter von Prinzipien des Clean Code wird hier Optimierungspotenzial erkennen. Schließlich muss der Entwickler an jeder Stelle einer Prozessapplikation wissen, wie einzelne Variablen benannt sind und ob sie bereits zur Verfügung stehen. Ebenso wird ein Refactoring über die IDE nicht funktionieren, da der Zugriff an jeder Stelle über einen unabhängigen String passiert. Es bleibt jedoch weiterhin das Problem, dass man sich bei jedem Abruf einer Variablen um Typkonvertierung kümmern muss, da natürlicherweise der o. g. Getter ein Object zurückgibt. D. h. wir müssen an jeder Zugriffsstelle einen Cast vornehmen:
Value v = (Value) execution.getVariable("key");
Auch bei der Verwendung der Typed-Value-API ist dies nicht viel anders:
ObjectValue objectValue = execution.getVariableTyped("key");
Value v = objectValue.getValue(Value.class);
Clean Code für Variablenzugriff
Die Optimierungsmöglichkeit liegt auf der Hand. Die lokalen Strings sollten in Konstanten ausgelagert werden, um Fehlerpotenzial (etwa Tippfehler) zu vermeiden, Umbenennung einzelner Variablen einfach zu machen und die Übersicht zu wahren. Üblicherweise führen wir in den Prozessapplikationen unserer camunda-Projekte dazu eine Klasse ProcessConstants ein, in der wir die genutzten Keys für den Variablenzugriff definieren. Somit haben wir ein zentrales „Nachschlagewerk“ für alle möglichen Variablen und können dieses beim Variablenzugriff nutzen. Die o. g. Zugriffe nutzen dann nicht mehr einen konkreten String, sondern je Variable einenProcessConstants.KEY.Konkret könnte dieses Nachschlagewerk so aussehen:
public class ProcessConstants { public static final String EXTIN_VSNR = "extIn_vsnr"; public static final String EXTIN_SCHADEN = "extIn_schaden"; public static final String EXTIN_PRUEFBERICHT = "extIn_pruefbericht"; public static final String INT_LEISTUNGSANSPRUCH_VORHANDEN = "int_leistungsanspruchVorhanden"; public static final String INT_PRUEFBERICHT_NOTWENDIG = "int_pruefberichtNotwendig"; public static final String INT_VERTRAG = "int_vertrag"; public static final String INT_AUSZAHLUNGSBETRAG = "int_auszahlungsbetrag"; public static final String EXTOUT_ZAHLUNGSBERICHT = "int_zahlungsbericht"; // .... }Listing 1: Konstanten für Zugriff auf Prozessvariablen mit Namensschema zur Trennung in logische Bereiche
Der Zugriff innerhalb eines Delegates auf die Variable des übergebenen Schadens würde dementsprechend wie folgt aussehen:
public class SchadenAnlegenDelegate implements JavaDelegate { @Override public void execute(DelegateExecution execution) throws Exception { Schaden schaden = (Schaden) execution.getVariable(ProcessConstants.EXTIN_SCHADEN); // .... } }Listing 2: Zugriff auf Prozessvariable über Konstante
So ist der Zugriff besser organisiert als beim direkten Zugriff über Strings. Dennoch bleibt bei der Entwicklung die notwendige Typkonvertierung an jeder Zugriffsstelle und die Fragestellung, ob eine Variable gerade bereits gesetzt ist oder nicht. Darüber hinaus kann es bei großen Prozessapplikationen passieren, dass die Übersicht über die Variablen und ihre Herkunft verloren geht.
Accessor Pattern und Trennung des Prozesskontexts in logische Bereiche
Um die Übersicht über die Variablen zu wahren, haben wir gute Erfahrungen damit gemacht, den Prozesskontext nochmals in logische Bereiche aufzutrennen. Wir trennen den Datenhaushalt logisch in einen externen (external), einen internen (internal) und einen technischen (technical) Bereich. Der externe Bereich enthält Variablen, die von extern in unsere Prozessapplikation übergeben werden (externalIn) oder die die Prozessapplikation extern bereitstellt (externalOut). Interne Prozessvariablen entstehen zur Prozesslaufzeit und werden nur intern genutzt und technische Variablen dienen technischen Aspekten wie bspw. zur Speicherung von Authentifizierungstoken für Service-Aufrufe oder Ähnlichem.Diese logische Trennung des Datenhaushalts wird primär über eine Namenskonvention für die „Keys“ der Variablen realisiert. Zum Beispiel beginnen interne Variablen immer mit
int_, extern eingehende Daten mit extIn_ und so weiter (vgl. Listing 1). Jetzt könnte die Konstantenklasse ebenso in die drei Bereiche aufgeteilt und so mehr Übersicht über den Variablenhaushalt geschaffen werden. Dies würde allerdings nicht die Probleme der fehlenden Typsicherheit lösen, außerdem wäre es doch erstrebenswert, den Variablenzugriff zumindest so aussehen zu lassen, als wäre er objektorientiert.Hier behelfen wir uns mit einem Accessor-Pattern auf den Prozesskontext. Wir definieren eine Klasse, die wir an jeder Stelle, an der wir auf Variablen zugreifen wollen, mit einer Referenz auf den aktuellen Variablen-Scope der Prozessinstanz bzw. der Execution initialisieren. Diese Klasse realisiert die Trennung in die verschiedenen logischen Bereiche und ermöglicht uns typsicheren Zugriff auf Variablen.
Am konkreten Beispiel könnte eine solche Accessor-Klasse wie folgt aussehen:
public class ProcessContext { private InternalProcessContext internalProcessContext; private ExternalInProcessContext externalInProcessContext; private ExternalOutProcessContext externalOutProcessContext; private TechnicalProcessContext technicalProcessContext; public ProcessContext(VariableScope execution) { this.internalProcessContext = new InternalProcessContext(execution); this.externalInProcessContext = new ExternalInProcessContext(execution); this.externalOutProcessContext = new ExternalOutProcessContext(execution); this.technicalProcessContext = new TechnicalProcessContext(execution); } public InternalProcessContext getInternal() { return internalProcessContext; } public ExternalInProcessContext getExternalIn() { return externalInProcessContext; } public TechnicalProcessContext getTechnical() { return technicalProcessContext; } public ExternalOutProcessContext getExternalOut() { return externalOutProcessContext; } }Listing 3: Accessor-Klasse zum Kapseln des Zugriffs auf den Prozesskontext
public class ExternalInProcessContext { private VariableScope execution; public ExternalInProcessContext(final VariableScope execution) { this.execution = execution; } public Schaden getSchaden() { return (Schaden) execution.getVariable(ProcessConstants.EXTIN_SCHADEN); } public void setSchaden(Schaden schaden) { execution.setVariable(ProcessConstants.EXTIN_SCHADEN, schaden); } //... }Listing 4: Accessor-Klasse zum Zugriff auf den „ExternalIn” Prozesskontext
Der Zugriff passiert dann innerhalb eines Delegates wie folgt:
public class SchadenAnlegenDelegate implements JavaDelegate { @Override public void execute(DelegateExecution execution) throws Exception { ProcessContext processContext = new ProcessContext( execution ); Schaden schaden = processContext.getExternalIn().getSchaden(); // .... } }Listing 5: Zugriff auf eine Prozessvariable über Accessor-Objekt
Die logische Trennung des Datenhaushalts ist über die Klasse ProcessContext technisch manifestiert, wir müssen uns beim Zugriff auf Variablen innerhalb des Java-Codes keine Gedanken mehr über die Benennung der einzelnen Variablen machen und die Typsicherheit wird durch die korrekte Verwendung der ProcessContext-Klassen gewährleistet. Darüber hinaus gibt es dann durch geeignete Entwicklungswerkzeuge Auto-Vervollständigung für alle möglichen Prozessvariablen innerhalb der logischen Prozesskontexte „geschenkt“.
Offene Herausforderungen und wie wir ihnen begegnen können
Dennoch bleiben Herausforderungen bestehen, die wir nicht allein mit einfacher Abstraktion des Prozesskontexts in Java-Klassen lösen können. Der hybride Charakter einer Prozessapplikation macht den Umgang mit Variablen schwer und fehleranfällig. In den Ausdrücken des BPMN 2.0 Prozessmodells bspw. zur Verzweigung des Prozessflusses muss weiterhin über einen String auf die Variablen zugegriffen werden (vgl. Abbildung 1). Der Entwickler muss immer noch wissen, wie die Variablen benannt sind, es existiert ein „Medienbruch“ zwischen der Java- und der Prozessmodell-Welt. Die Prozesskontext-Klassen können zwar dabei helfen, die Übersicht zu wahren, aber dennoch passieren beim Variablenzugriff über Ausdrücke im Prozessmodell häufig Flüchtigkeits- oder Tippfehler.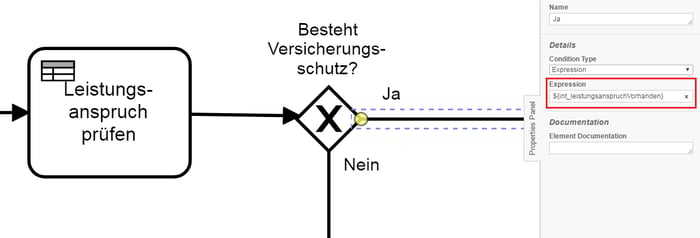
Abbildung 1: Zugriff auf Variablen per Expression im Prozessmodell
Es bleibt der Umstand, dass Variablen erst zur Laufzeit einer Prozessinstanz entstehen und an beliebigen Stellen hinzukommen bzw. verändert werden können. Man muss also wissen, welche Variable zu welcher Zeit belegt ist und ob diese gerade zugreifbar ist oder nicht. Dies wird man sicherlich zu Teilen mit JUnit Tests des Prozessflusses abdecken können. Dennoch ist eine statische Validierung, beispielsweise mithilfe von DEF-USE-Ketten, eine geeignete Erweiterung, um zu gewährleisten, dass ein Variablenzugriff gerade sinnvoll und richtig ist. So kann z. B. sichergestellt werden, dass eine Variable zwischen Initialbelegung und späterer Nutzung nicht unvorhergesehen (z. B. in einem „versteckten Listener“) gelöscht wurde, oder geprüft werden, ob sie vor einem Lesezugriff überhaupt gesetzt wurde.
Ganz unabhängig vom Lebenszyklus von Prozessvariablen ist es erstrebenswert, die o. g. Modellierungs- und Entwicklungskonventionen für Variablen (aber auch für andere Aspekte innerhalb einer Prozessapplikation) einzuhalten und v. a. automatisiert einzufordern.
Um diese Aspekte möglichst gut zu unterstützen und die Entwicklung von Prozessapplikationen im Team einfacher zu machen, haben wir den viadee Process Application Validator (vPAV) entwickelt. Es ist ein Open-Source-Werkzeug (GitHub), um übergreifende Validierung zwischen Java-Code und Prozessmodell einer Prozessapplikation zu realisieren. Das Werkzeug integriert sich einfach in eine Continous-Integration Pipeline und gibt einem Entwicklungsteam so unmittelbares Feedback über potenzielle Probleme einer Prozessapplikation. Wir stellen das Werkzeug bei Interesse gerne in einem kurzen Webinar vor. Über Feedback, Feature-Requests, „Contributions“ oder Fragen zum vPAV würden wir uns sehr freuen.
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



