

Vom 24. bis zum 26.06. fand in München die TDWI 2019 statt, Deutschlands größte Messe für BI und Analytics. Die viadee Berater Timm Euler, Tobias Otte, Markus Wulftange, Luzia Tinten, David Overfeld und Frank Hanke waren vor Ort, um sich über die neusten Entwicklungen zu informieren. Hier die Highlights.
Machine Learning und Data Science
Eines der bestimmenden Themen auf der TDWI war das Thema Machine Learning/KI sowie Data Science. Hierzu wurden u. a. Redner aus dem Silicon Valley wie Mark Madsen oder auch der durch die umfangreiche Analyse von Zusammenhängen zwischen Spiegel Online-Artikeln bekannt gewordene Data Scientist David Kriesel eingeladen. Fasst man die aktuelle Entwicklung in diesem Bereich zusammen, stechen fünf Bereiche heraus:
1. Nur sehr wenige Firmen nutzen bisher automatisierte Machine Learning (ML)-Modelle
Auch wenn das Thema in aller Munde ist, fehlt es vielen an brauchbaren Anwendungsfällen und zusätzlich dem Wissen, wie tatsächliche Anwendungsfälle mit Techniken des maschinellen Lernens sinnvoll und vor allem automatisiert unterstützt werden können. So schätzt Mark Madsen, dass momentan nur etwa 10 % der Firmen, die ML nutzen, tatsächlich automatisierte Modelle im Einsatz haben und der Rest hauptsächlich Ad-hoc-Analysen, sei es mittels grafischer Modelle aus dem Bereich Data Science oder tatsächlicher ML-Modelle, durchführt.
2. Bisher unzureichende Erklärbarkeit von und Vertrauen in ML-Modelle
Punkt 1 ist auch dadurch begründet, dass viele Firmen den ML-Modellen nicht genügend vertrauen, um ihnen eine autonome Handlungsfreiheit zu gewähren. Dies hat auch damit zu tun, dass es kaum brauchbare Ansätze zur Erklärbarkeit von Entscheidungen vor allem in neuronalen Netzen gibt. In vielen Vorträgen wurde auch darauf hingewiesen, dass dieser Mangel an Vertrauen durchaus gerechtfertigt ist: Nicht selten werden Modelle trainiert, bei denen eine winzige Änderung der Eingangsdaten eine unverhältnismäßige Verhaltensänderung zur Folge hat. Ebenso werden immer wieder ungewollt Modelle trainiert (speziell bei Bilderkennung), die auf die falschen Details im Bild fokussiert sind. Gute Beispiele waren hier Zeitstempel von Röntgenaufnahmen, für die eine Krebsdiagnose gestellt werden sollte oder auch ein Hundehalsband bei der Unterscheidung zwischen Katze oder Hund. Wer sein Modell nicht genau versteht, kann hier schnell in eine Falle tappen. Ein dramatisches Beispiel war eine frühere Version des Teslas, welcher aufgrund von unerwarteten Punkten auf der Fahrbahn plötzlich in den Gegenverkehr fuhr. Deshalb: Bei kritischen Entscheidungen sollte Machine Learning in erster Linie unterstützend wirken und Ergebnisse von Menschen überprüft werden. Bei unkritischen Entscheidungen wie Produktempfehlungen kann dagegen auch eine Automatisierung in Betracht gezogen werden.
3. Deploybarkeit sowie Skalierbarkeit
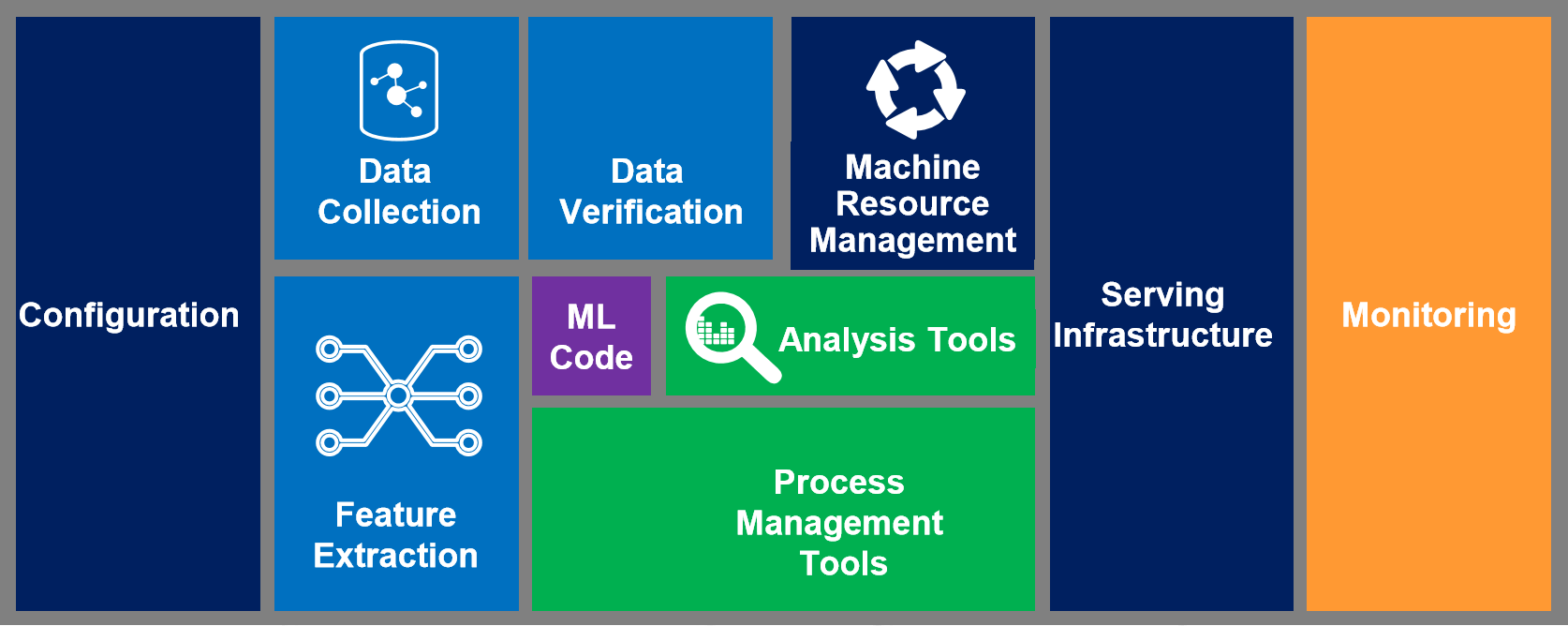
Es wurden viele Beispiele genannt, bei denen mittels R oder Python ausgezeichnete Machine Learning-Modelle entwickelt wurden, die am Ende aber neu geschrieben werden mussten, weil nicht bedacht wurde, dass diese Modelle einmal im Live-Betrieb laufen sollen und die vorhandene Infrastruktur nicht für einen Betrieb der entwickelten Modelle ausgelegt war. Hier muss von vornherein abgeklärt werden, was am Ende mit den Modellen passieren soll. Denn bei operationalisiertem Machine Learning ist das eigentliche Modell nur der kleinste Teil der zu bewältigenden Aufgaben.
4. Mangelnde Performance und Robustheit
Viele ML-Modelle funktionieren gut und performant, wenn sie mit den vorhandenen Trainingsdaten arbeiten müssen. Es muss jedoch bedacht werden, dass Modelle im Live-Einsatz auf einer möglicherweise rasant wachsenden Datenbasis arbeiten müssen und dazu ständig neu trainiert werden müssen, um z. B. geändertem Kundenverhalten gerecht zu werden. Auf einer Shopping-Plattform entscheiden Millisekunden darüber, ob ein Kunde ein Produkt kauft oder genervt zu einem Konkurrenten wechselt.
5. Unterschätztes Monitoring
Um zu beurteilen, ob ein ML-Modell die Erwartungen erfüllt oder ob es besser oder schlechter wird, ist ein gutes Monitoring unerlässlich. Gut bedeutet, dass alle Daten (bzw. so viele wie möglich) pro Entscheidung gespeichert werden, um später eine umfangreiche Analyse und Reproduzierbarkeit zu gewährleisten. Zusätzlich muss ein gutes Monitoring, insb. bei vollständig automatisierten Modellen, die richtigen Stakeholder rechtzeitig über ungewolltes Verhalten (z. B. Underperformance) informieren.
Data Virtualization
Datenvirtualisierung ist die Erstellung einer logischen Datenzugriffsschicht, die die (dispositiven) Datenproduzenten von den Datenkonsumenten trennt. Logisch heißt hier, dass diese Schicht nur in Form von Views auf die Datenproduzenten realisiert wird. Die Lese-Performanz wird durch (automatisches oder gesteuertes) Caching sichergestellt.
Auf der TDWI 2019 gab es mehrere Praxisvorträge von Firmen (u. a. Schaeffler, AXA, ING DIBA), die diesen Ansatz nutzen, um die Anbindung ihrer BI-Frontends stabil zu halten, während die DWH-Landschaft dahinter sich weiterentwickelt und beispielsweise teilweise in die Cloud wandert oder um Big Data-Ansätze ergänzt wird. Die Unterstützung solcher Migrationsszenarien wird als einer der Hauptvorteile von Datenvirtualisierung gesehen; ein anderer ist die einheitliche Darstellung verschiedener Quellsysteme in einer Schicht, und damit i. d. R. in einem Werkzeug, für alle Datenkonsumenten. Dies erleichtert etwa die Erstellung und Wartung eines Data Dictionarys.
Weitere Hinweise zu Datenvirtualisierung finden sich auch in diesem Blog-Beitrag.
DWH in der Cloud
Ebenso gab es auf der TDWI 2019 mehrere Firmen, die von Praxiserfolgen beim Betrieb eines Teils ihres DWHs oder ihres gesamten DWHs in der Cloud berichteten. Die großen Cloud-BI-Anbieter wie Microsoft, Amazon oder IBM waren denn auch ebenfalls auf der Messe vertreten. Diese Anbieter stellen Cloud-basierte Werkzeuge entlang des gesamten BI-Stacks bereit. Doch man kann auch klein anfangen, so gab es Berichte davon, sich zunächst "nur" die relationale Datenbank, die das Enterprise DWH speichert, von einem Cloud-Anbieter hosten zu lassen, oder nur das BI-Frontend.
Viele Wege führen in die Cloud und fast alle klassischen BI-Hersteller bieten mittlerweile Lösungen für den Cloud-basierten Betrieb an. Kaum jemand wird dabei sein gesamtes DWH mit einem Rutsch in die Cloud portieren. Es gibt jedoch diverse Migrationswege: Man kann etwa zunächst nur einzelne Teile der vorhandenen BI-Landschaft Cloud-basiert betreiben, oder schrittweise in der Cloud ein vollständiges DWH "bottom-up" neu aufbauen, während das alte DWH noch auf der eigenen Hardware weiterläuft. In beiden Fällen ist der oben erläuterte Virtualisierungsansatz sehr nützlich, um technische Änderungen im Backend zu kapseln gegenüber dem Frontend.
New SQL
Wer sich in den letzten Jahren mit Big Data-Technologien und alternativen Datenbanken wie MongoDB, HBase etc. beschäftigte, konnte den Eindruck gewinnen, dass die beliebte Abfragesprache SQL an Bedeutung verliert, da zahlreiche neue Datenbanken SQL nicht oder nicht vollständig unterstützen. Rick van der Lans wies jedoch in seinem Vortrag bei der TDWI 2019 auf die Renaissance von ACID-kompatiblen Datenbanken, die SQL vollständig unterstützen, für unterschiedlichste Einsatzzwecke hin. Er betonte, dass bei der Evaluation von Datenbank-Technologien stets die Frage nach der vorgesehenen Anwendung im Vordergrund stehen müsse. Geht es um transaktionsbasierte Verarbeitung nach klassischer ERP-Manier, so sind klassische relationale Datenbanken immer noch die richtige Wahl; jedoch sind diese oft als "General Purpose"-Technologien ausgelegt und müssen daher bei der Skalierbarkeit Kompromisse machen.
Werden die Datenmengen zu groß für die klassischen Datenbanken, will man jedoch dennoch transaktionsbasiert arbeiten, so gibt es mittlerweile eine Reihe von sehr gut horizontal skalierenden Technologien mit vollständiger ACID-Garantie, die zum Beispiel Performanz gewinnen, indem sie auf das "Locking" beim Schreiben von Tabellen verzichten und stattdessen Queues verwenden, oder indem sie anderen aufwendigen internen Verwaltungs-Overhead vermeiden. Gerne wird das Schlagwort "NewSQL" für solche Datenbanken verwendet. Beispiele sind VoltDB, Clustrix oder Drizzle. Auf der anderen Seite können solche Technologien weniger geeignet für OLAP-Zwecke sein.
Für OLAP-Zwecke, also BI- und Analytics-ähnliche Auswertungen, bieten sich daher neue Technologien an wie SQL-on-Hadoop (SparkSQL, Dremio, Presto oder Apache Drill) oder auch Datenbanken, die auf die speziellen Vorteile von GPUs setzen (Kinetica, BlazingDB) oder die von vorneherein für die horizontale Skalierung in einer Cloud-Umgebung ausgelegt sind, etwa Snowflake.
Wichtig ist also, sich zuerst gründlich mit den eigenen Anforderungen auseinanderzusetzen und dann anhand klarer Kriterien den Zoo an neuen Technologien zu sortieren. Auf diese Weise wird man schnell zu einer recht kurzen Liste an Datenbanken gelangen, deren genauere Betrachtung dann in vernünftiger Zeit möglich ist, um am Ende das am besten passende Produkt für sich zu finden.
data warehouse automation
Die Automatisierung von ETL- bzw. ELT-Prozessen ist mittlerweile in vielen Projekten angekommen. Auf der Messe waren auch verschiedene Produkte vertreten, z. B. Attunity, biGenius, integration-factory, Datavault Builder und Wherescape.
Welches Tool für das eigene Projekt das richtige ist hängt stark von den Anforderungen ab. Wherescape, mit dem wir als viadee bereits intensivere Erfahrungen gesammelt haben, erscheint uns aktuell als das ausgereifteste Produkt, da es nicht nur ELT-Code erzeugt, sondern auch umfassende Dokumentation, Data Lineage, Data Profiling, Modellierung in 3NF, Data Vault und Dimensionalen Modellen, Jobsteuerung, Einbettung von eigenem Code, etc. bietet. Um diese Fülle an Möglichkeiten richtig zu nutzen, ist aber auch intensives Toolwissen erforderlich.
Data Vault Builder geht einen anderen Weg und ist stark auf die Automatisierung des CORE-DWH als Data Vault spezialisiert. Dabei sind viele Standards fest vorgegeben, die teilweise von den Lehren Dan Linstedts (dem Erfinder von Data Vault) abweichen. So werden im Data Vault Builder z.B. alle Transaktionen als Hubs und nie Satelliten an Links modelliert. Wenn man mit den Vorgaben des Datavault Builders zurechtkommt ist er dafür schnell und leicht erlernbar. Auf einem 3-stündigen Workshop während der TDWI Konferenz konnten sich die Teilnehmer selbst davon überzeugen, dass es möglich ist, in so kurzer Zeit mit mehreren Teams Data Vault-Modelle für Sales, Orders, Customers und Products zu erstellen, Dimensionen und Fakten daraus abzuleiten und diese Modelle dann wieder zu integrieren.
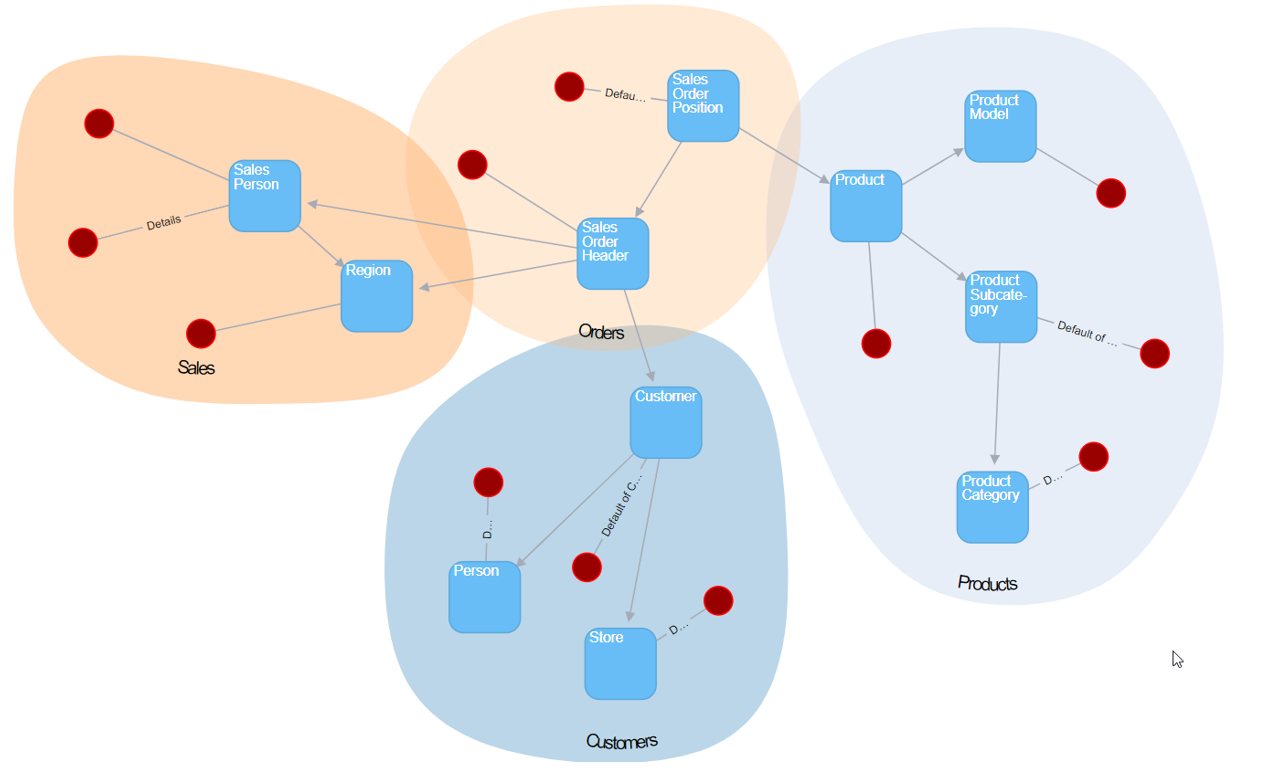
Den Überblick über die Daten behalten
Damit aus dem Data Lake kein Sumpf wird sondern ein Reservoir sauberer und wertvoller Daten, ist es wichtig, Metadaten zu erfassen. Der Themenbereich Metadaten / Data Lineage / Data Governance ist nicht neu und seit jeher ein wichtiges, aber schwieriges Thema für DWH / BI Umgebungen, neu ist aber die automatisierte Ermittlung der Daten, bei der auch KI Methoden eingesetzt werden.
So gibt es neue Tools wie den Talend Data Catalog, Alation, Collibra und weitere, die sich auf die automatische Ermittlung, Katalogisierung und Bereitstellung von Metadaten spezialisiert haben. Auch im Hinblick auf die Datenschutz Grundverordnung können diese Technologien helfen, sensible Daten nur berechtigten Interessenten bereitzustellen.
Entspannte Atmosphäre
Neben spannenden Vorträgen und Workshops hatte die TDWI 2019 auch eine gute Atmosphäre zu bieten, die in den letzten Jahren zunehmend lockerer geworden ist. So sieht man einerseits - sicher auch durch die Hitze bedingt - weniger Krawatten, andererseits wird auch mehr geduzt als früher.
Am Dienstag Abend wurde das 15-jährige Jubiläum der Konferenz im Kesselhaus ausgiebig gefeiert.
Nach den letzten Vorträgen am Mittwochnachmittag hatten wir am Flughafen noch Zeit, das dicht gepackte Programm Revue passieren zu lassen. Wir haben viele Inspirationen mitgenommen und freuen uns auf die nächsten 15 Jahre TDWI Konferenz.

zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



