
Automatisierung oder Virtualisierung? Grafisches Werkzeug oder eigenes Framework? Mehr Tests oder mehr Ad-hoc-Abfragen? Wohin geht die Reise beim Thema ETL, und wohin sollte sie gehen?
Noch immer stellt die regelmäßige Bewirtschaftung eines großen Data Warehouses (DWH) mit aktuellen Daten für viele Unternehmen eine Herausforderung dar. Der größte Teil des Aufwands für den Unterhalt eines DWH fließt in die Datenflüsse, erst mit großem Abstand folgen Datenmodellierung und Betrieb. Einer der wichtigsten Gründe dafür ist, dass im DWH zwei gegensätzliche Anforderungen unter einen Hut zu bringen sind: Einerseits muss ein DWH aktuelle Trends abbilden und zeitnahe Entscheidungen ermöglichen – dazu müssen neue Datenquellen und geänderte Datenstrukturen schnell und agil integriert werden können. Andererseits müssen die DWH-Daten eine hohe Qualität aufweisen – dafür müssen die Bewirtschaftungsprozesse, oft auch ETL-Prozesse genannt (Extraktions-, Transformations- und Ladeprozesse), unter professionellen Bedingungen wie eigene Software entwickelt, getestet, gewartet und betrieben werden, und sie selbst wie auch die Vorgehensweisen bei ihrer Entwicklung müssen Revisionsprüfungen standhalten.
Diesem Spagat versucht eine Reihe von Ansätzen gerecht zu werden, aber welcher ist für Sie geeignet? Schauen wir uns die wichtigsten Ideen an. Diese sind im Überblick:
- Self-Service BI
- Grafisches ETL
- Professionalisierung des ETL-Software-Entwicklungsprozesses
- DWH-Automatisierung
- Virtualisierung
DWH der zwei Geschwindigkeiten: Integration von Self Service BI
An diesem Ansatz führt heute für viele große Installationen kein Weg mehr vorbei. Die Grundidee dahinter wird jedoch selten offen ausgesprochen: Die IT nutzt die Expertise der Fachabteilung zur eigenen Entlastung. Dazu werden bestimmte, eher „technik-affine“ Fachexperten, die es in den meisten Fachabteilungen gibt, in die Lage versetzt, selbst Daten auszuwerten oder Berichte zu designen. Sie nutzen dafür mächtige, intuitiv bedienbare Werkzeuge, mit denen sie auch neue Datenquellen selbst untersuchen können (Self Service BI).
Dabei können manchmal Fehler aus Unwissenheit entstehen, indem Daten falsch interpretiert oder integriert werden. Daher sollten auf diesem Wege keine bestehenden Auswertungen geändert, sondern nur neue vorgeschlagen werden. Um deren Qualität zu sichern, sollten sie immer im 4-Augen-Prinzip geprüft werden, entweder durch weitere Fachexperten oder mittels eines Reviews durch die IT-Abteilung. Nur wenn sich herausstellt, dass eine neue Auswertung a) fehlerfrei ist und b) häufiger benötigt wird, wird die IT damit beauftragt, sie zu automatisieren, also in die reguläre Bewirtschaftung zu übernehmen.
Man sollte sich jedoch bewusst sein, dass es diese Entlastung der IT nicht umsonst gibt. Der höhere Aufwand auf der Fachseite sei dabei noch nicht einmal in Rechnung gestellt, denn es hat viele Vorteile, wenn dort genau verstanden wird, welche Daten und Berechnungen in die Entscheidungsgrundlagen einfließen. Aber auch in einer Self Service-Plattform müssen neue Datenquellen zunächst durch die IT angebunden werden und hier herrschen hohe Erwartungen an Flexibilität und Geschwindigkeit. Zudem muss die Zusammenarbeit zwischen IT und Fachabteilung dauerhaft lebendig gestaltet werden. Ein Muss sind regelmäßige Anwendertreffen in der Self Service Community, die durch weitere Maßnahmen wie die Schaffung interner Foren, Newsletter o. Ä. ergänzt werden sollten. Im Idealfall entsteht ein Teamgeist über die Abteilungen hinweg, der den Qualitätsanspruch bei neuen Auswertungen hochhält. Und warum dazu nicht einmal Gamification-Ansätze ausprobieren, wie sie in diesem Blog vorgestellt werden?
Verwendung von grafischen ETL-Werkzeugen
Viele Entwickler und BI-Projektleiter erhoffen sich eine Steigerung der Produktivität durch die Einführung von ETL-Werkzeugen, die den Aufbau der Datenflüsse grafisch darstellen und den für die Ausführung benötigten Code generieren. Und zweifellos ist die integrierte Dokumentation bzw. grafische Darstellung von ETL-Prozessen das große Plus dieser Tools. Wer möchte schon den folgenden Datenfluss erst mühselig aus einer langen Code-Seite erschließen? Ein Bild sagt schließlich mehr als 1000 Worte:
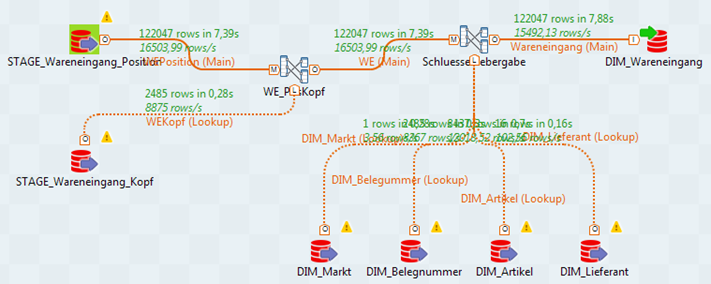
Werkzeuge, die so ein Bild automatisch aus Programmcode erzeugen können, sind leider Mangelware, und das manuelle „Nachzeichnen“ solcher Datenflüsse für Dokumentationszwecke wird im Projektgeschehen in der Regel „wegoptimiert“.
Doch warum werden solche Bilder eigentlich nicht automatisch aus Programmcode erzeugt? Am Grund dafür erkennt man zugleich einen wesentlichen Nachteil grafischer ETL-Werkzeuge. Angenommen, der im obigen Bild gezeigte Datenfluss soll auf die gleiche Weise für andere Quelltabellen erzeugt werden: Im grafischen Werkzeug bleibt dann nur Copy-Paste und Anpassung. Je unterschiedlicher die Metadaten, desto größer der Anpassungsaufwand. Ein Programmierer kommt dagegen schnell auf den Gedanken, das, was beiden Datenflüssen gemeinsam ist, in eine Unterroutine auszulagern und diese mit verschiedenen Parametern aufzurufen. Dann können ETL-Prozesse auch leicht in Schleifen mehrfach ausgeführt werden und es können zentrale Aufgaben wie die Ermittlung des aktuellen (logischen) Datums, des richtigen Datenbankzugriffs usw. leichter einheitlich umgesetzt werden. Auch die Verwendung eines einheitlichen, auf die eigenen Bedürfnisse angepassten Frameworks für alle ETL-Prozesse ist einfacher, wenn man selbst programmiert.
Programmiersprachen sind eben sehr mächtige Werkzeuge und daher ist die Datenfluss-Analyse eines komplexeren ETL-Programms schwierig, gerade für automatische Werkzeuge. Diese Macht ist Fluch und Segen zugleich, denn natürlich handelt man sich im Tausch gegen die Flexibilität der freien Programmierung alle üblichen Schwierigkeiten der Softwareentwicklung auch im ETL-Bereich ein, wie etwa die Pflege der Software-Architektur, die langfristige Wartbarkeit usw.
Hier die Vor- und Nachteile im Überblick:
GRAFISCHE WERKZEUGE |
EIGENE PROGRAMMIERUNG |
|
|---|---|---|
PRO |
|
|
CONTRA |
|
|
Doch egal, ob man sich für ein grafisches Werkzeug entscheidet oder dagegen – es wird in vielen Organisationen höchste Zeit, auch in der ETL-Entwicklung modernen Standards aus dem Software-Engineering zu folgen:
Professionalisierung der ETL-Softwareentwicklung
Viele moderne Vorgehensweisen, die im Software-Engineering in den letzten Jahren selbstverständlich geworden sind, haben ihren Weg noch kaum in die ETL-Entwicklung gefunden. An erster Stelle sind hier automatisierte Tests im Rahmen des „Test driven developments“ zu nennen: Jede neue Fachlichkeit wird zunächst in Testfällen abgebildet und erst anschließend folgt die Entwicklung der Software; bei jeder Änderung der Software müssen alle Testfälle wieder durchlaufen werden und dürfen keine Fehler erzeugen, sonst wird die Änderung zurückgewiesen. Der Umfang der Testfallsets steigt dabei in größeren Projekten schnell an, sodass Automatisierung unerlässlich ist. Im Bereich ETL benötigt man dafür eine Testumgebung mit definierten, ggf. synthetischen Quelldaten, sodass die Ergebnisse der ETL-Verarbeitungen spezifiziert und mit den tatsächlichen Ergebnissen abgeglichen werden können. Das erfordert auch, diese Spezifikationen ständig an neue Erfordernisse anzupassen, denn mit der Hinzunahme neuer Testfälle können sich z. B. die Summen in bestehenden Reports ändern. Der Lohn für diesen Aufwand ist jedoch eine wesentlich größere Stabilität der Software und ein viel größeres Vertrauen, dass Änderungen nicht zu unerwarteten Seiteneffekten führen.
Automatisierte Tests sind die Voraussetzung für die Schaffung einer Continuous-Deployment-Pipeline: Kleinere Änderungen können nach diesem Ansatz direkt in Produktion gegeben werden, wenn das definierte Testfallset keine Fehler nachweist. Beispielsweise könnte die aktuelle Codebasis jede Woche automatisiert in Produktion eingesetzt werden, falls alle Testfälle vorher korrekt durchlaufen wurden. Indem für fachliche Weiterentwicklungen zuerst die Testfälle angepasst werden, lässt sich dieses Vorgehen auch für größere Änderungen erweitern. Auf diese Weise kann ein DWH wesentlich agiler werden als bei klassischen Vorgehensweisen.
Die bisher genannten Software-Engineering-Ansätze sollten auch bei Verwendung grafischer ETL-Werkzeuge eingesetzt werden. Falls man sich für eigene Programmierung entschieden hat, bieten sich weitere Ideen an:
- Statische Code-Analyse: Auch dieses im klassischen Software-Engineering verbreitete Werkzeug ist im ETL-Bereich noch unterrepräsentiert. Die Idee ist, gewisse formale Schwächen von Programmen bereits zur Compilezeit aufzuzeigen; meist bleibt es den Entwicklern überlassen, ob und wie sie diese beheben, doch oft handelt es sich um gute Hinweise auf mögliche Fehlerquellen. Für Sprachen wie SQL oder PL/SQL dürfte die mangelnde Verfügbarkeit entsprechender Analyse-Werkzeuge ein Hindernis sein. Doch wer Programmiersprachen wie Java oder Frameworks wie Spark nutzt, kann auf eine Palette ausgereifter Werkzeuge zurückgreifen. Deren nutzbringende Handhabung in einem Team unterschiedlicher Programmierer erfordert sicherlich etwas Anlaufzeit, doch die Qualität der erstellten Software kann davon nur profitieren.
- Clean Code: Die Clean Code-Bewegung stellt eine Reihe von abstrakten Prinzipien bereit, die bei der Erstellung von les- und wartbarem Programmcode beachtet werden sollten. Dabei geht es nicht um Dogmen, sondern um die Reflexion von möglichen Wegen, Code effizient und verständlich zu gestalten. DWH-Architekten sollten ihr Team ermutigen, sich mit den zentralen Clean Code-Ideen zu beschäftigen und sich ständig dazu auszutauschen. Zwar stammen einige der Clean Code-Prinzipien aus der objektorientierten Programmierung, doch lassen sich viele auch auf Skriptsprachen übertragen, die im ETL-Bereich häufiger genutzt werden. Mehr zu Clean Code und zur Nutzung im ETL-Bereich am Beispiel SAS finden Sie hier.
Eine weitere Möglichkeit, die ETL-Entwicklung zu professionalisieren, ist die automatische Generierung von ETL-Prozessen; damit befasst sich der nächste Abschnitt.
DWH-Automatisierung und Schematisierung von ETL-Prozessen
Lässt man fachliche Aspekte einmal beiseite, so tun ETL-Prozesse immer wieder das Gleiche: extrahieren, integrieren und historisieren. Lässt sich hierfür ein allgemeines Schema finden? Das ist die Idee hinter dem Data Vault-Ansatz. Dabei ist das Ziel-Datenmodell im Kern-DWH nach einem stets einheitlichen System konstruiert, in dem nur drei Typen von Tabellen erlaubt sind, deren Grundaufbau vorgegeben ist (Hub, Link und Satellit). Fachliche Aspekte werden dabei bewusst noch nicht modelliert, sondern auf höhere DWH-Schichten verschoben. Somit lassen sich auch die ETL-Prozesse, die diese Kerntabellen befüllen, auf stets gleiche Weise erstellen. Es genügt im besten Fall, je eine „Schablone“ eines ETL-Prozesses für jeden der drei Tabellentypen zu entwickeln und diese immer wieder anzuwenden, um den konkreten ETL-Prozess zu generieren. Hierin liegt der wesentliche Vorteil des Data Vault-Ansatzes: die Kernaufgaben des DWH (Datenintegration und Historisierung) können „nach Schema F“ erledigt werden, fachliche Aspekte kommen erst in höheren Schichten zum Tragen.
Unter dem Schlagwort der DWH-Automatisierung stellen einige Hersteller Produkte bereit, die diese und weitere „ETL-Schablonen“ bereits beinhalten und die Generierung von ETL-Prozessen auf verschiedene Zielplattformen leisten. Damit kann die Produktivität eines DWH-Teams deutlich erhöht werden. Hier sollte man sich im Vorfeld jedoch intensiv Gedanken über die gewünschte Zielplattform machen und prüfen, welcher Hersteller diese am besten adressiert. Nicht jedes Automatisierungswerkzeug kann etwa effizienten, massendatentauglichen Java-Code oder PL/SQL-Code generieren, falls man seine Prozesse in diesen Sprachen umsetzen möchte. Außerdem sollte geprüft werden, inwiefern die Schablonen oder der Generierungsprozess für eigene Zwecke anpassbar sind. Die Neugenerierung von ETL-Prozessen aus einer Schablone heraus darf nicht zur Überschreibung individueller Anpassungen führen. Wenn dies gegeben ist, bietet die Automatisierung das Potenzial, die Vorteile grafischer ETL-Werkzeuge mit der Flexibilität individueller Programmierung zu verbinden.
Im Idealfall lassen sich die Automatisierungswerkzeuge in umfassende Software-Engineering-Umgebungen, wie im vorigen Abschnitt diskutiert, einbetten. Solche technischen Architekturen sind ein großer Schritt hin zu einem robusten und dennoch agilen Data Warehouse!
Virtualisierung des DWHs
Mit Virtualisierung ist im DWH-Umfeld meist nicht die virtuelle Hardware-Plattform, sondern das "virtuelle, übergreifende Datenmodell" gemeint. Die Idee ist, den Zugriff auf jede Art von Datenquelle – sei es das Kern-DWH, davon abgeleitete Cubes, der Data Lake, eine NoSQL-Datenbank oder externe Datenquellen – über eine gemeinsame Komponente einheitlich zu gestalten. Diese Zugriffskomponente ist ein spezielles DWH-Virtualisierungswerkzeug, wie es einige Hersteller anbieten. Es stellt allgemeine Datenmodelle und Transformationen zur Verfügung, mit denen jede der Quellen geeignet modelliert und angebunden werden kann. Letztlich geht es also auch hierbei um ETL-Aufgaben! Die Unterschiede zum klassischen ETL schauen wir uns im Folgenden an.
Die einheitliche, virtuelle Zugriffsschicht für alle Daten bietet viele Vorteile. Alle Datenkonsumenten (Reports, das BI-Portal, Ad-hoc-Abfragewerkzeuge etc.) greifen auf die gleiche Komponente und ein einheitliches Datenmodell zu. Alle Datenproduzenten werden hier angebunden, auch wenn ihre Daten nicht relational strukturiert sind. Technische Änderungen an einem Datenproduzenten, wie der Wechsel einer zugrunde liegenden Technologie, können hinter der Zugriffsschicht gekapselt und für die Datenkonsumenten transparent gestaltet werden. Neue Datenfelder oder -quellen können zunächst direkt angebunden und später auf dem "offiziellen" Weg durch das DWH integriert werden. Auch dies ist also ein Weg, im Data Warehouse agiler und flexibler zu werden.
Die für die Zusammenstellung der verschiedenen Quellen in einem einheitlichen Modell notwendigen Transformationen, auch Mappings genannt, werden im Virtualisierungswerkzeug definiert und erst zum Zeitpunkt eines Datenkonsums ad hoc berechnet. Damit dies effizient funktioniert, bietet das Virtualisierungswerkzeug umfangreiche Möglichkeiten, (abgeleitete) Daten zu cachen, sodass sie nicht neu berechnet oder transportiert werden müssen, wenn sie sich seit der letzten Abfrage nicht geändert haben. Der Virtualisierungsserver sollte daher ausreichend mit Hauptspeicher ausgestattet sein. Auch eine regelmäßige Vorausberechnung/Aktualisierung des Caches, etwa nachts, lässt sich vornehmen.
Statt der ETL-Transformationen, die alle Daten regelmäßig aktualisieren, gibt es also im Virtualisierungsszenario nur die Definition der Transformationen (Mappings), während deren tatsächliche Berechnung bedarfsgesteuert erfolgt. Daten, die selten konsumiert werden, werden damit auch selten berechnet. Dennoch erfüllen diese Mappings die gleichen Aufgaben, insbesondere zur Datenbereinigung und -integration, wie ETL-Werkzeuge. ETL-Kenntnisse werden also auch im virtualisierten DWH nicht überflüssig, und die fachliche Aufbereitung der Daten kann natürlich ebenfalls nicht entfallen. Aber Virtualisierung kann eben durchaus auch ein Weg sein, den eingangs beschriebenen gegensätzlichen Anforderungen an ein DWH zu begegnen, weil die Kapselung der Datenproduzenten gegenüber den Konsumenten mehr Flexibilität erlaubt.
Fazit
Die oben genannten Möglichkeiten, ETL-Prozesse agiler und zugleich robuster zu gestalten, schließen sich nicht gegenseitig aus, sondern können sich in modernen Architekturen durchaus gegenseitig ergänzen. Falls Ihr ETL-Team den Umgang mit modernen Programmierwerkzeugen beherrscht oder erlernen kann, sollten Sie über selbst erstellte ETL-Frameworks nachdenken und damit die oben unter Professionalisierung genannten Methoden verbinden, um einen agilen Entwicklungsprozess zu schaffen. Mit geeigneten Automatisierungswerkzeugen, die das Team bei Standardaufgaben unterstützen, ohne es bei Spezialaufgaben zu behindern, ist dieser Ansatz gut kombinierbar. Virtualisierung über "Mappings" bietet sich zunächst für bereits aufbereitete Daten an und kann von dort aus ausgedehnt werden, sodass hier Schritt für Schritt überprüft werden kann, welche ETL-Prozesse durch Mappings ersetzt werden können.
Viele Wege führen also nach Rom und wir unterstützen Sie gerne auf Ihrer Reise!
Autor
 Dr. Timm Euler war bis September 2020 Senior-Berater bei der viadee IT-Unternehmensberatung und Leiter des F&E-Bereichs Business Intelligence.
Dr. Timm Euler war bis September 2020 Senior-Berater bei der viadee IT-Unternehmensberatung und Leiter des F&E-Bereichs Business Intelligence.
Er interessiert sich für alles rund um Big Data, Data Warehousing und Data Mining.
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



