
Was ist eigentlich Data Vault? Und welche Vorteile bietet es im Vergleich zur klassischen Data Warehouse-Modellierung- und Architektur? Diese und weitere Fragen werden im folgenden Beitrag mit konkreten Beispielen beantwortet.
Warum Data Vault?
Unternehmen müssen ihr Geschäft in immer kürzeren Zyklen transformieren und sich permanent den Marktbedürfnissen oder auch neuen regulatorischen Anforderungen anpassen. Data Warehouse-Verantwortliche stehen deshalb unter Druck, da die bestehenden Datenstrukturen häufig zu schwerfällig und komplex sind und notwendige Anpassungen in vielen Fällen als zu teuer und zeitaufwändig wahrgenommen werden. Ein Lösungsansatz hierfür ist Data Vault.
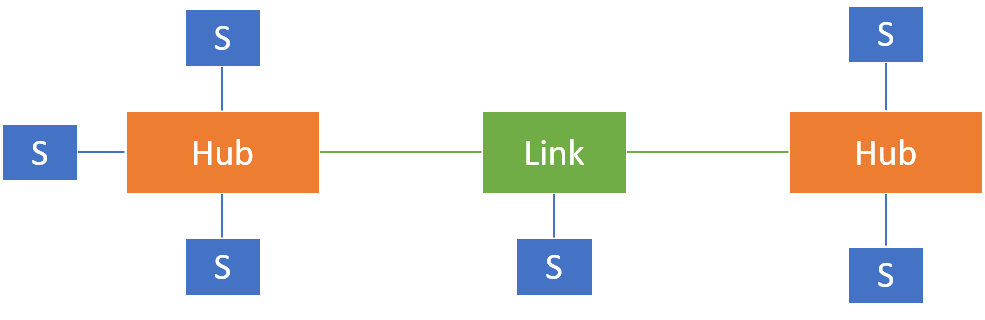
Kernstück von Data Vault ist eine Modellierungstechnik, welche Eigenschaften aus der dimensionalen (Sternschema) und normalisierten Modellierungswelt vereint und hierdurch die Befüllung beschleunigt und die Erweiterung um neue Informationen vereinfacht. Dabei soll das Data Vault-Datenmodell kein vollständiger Ersatz für das bereits viele Jahre erprobe Sternschema sein, sondern dieses vielmehr ergänzen, indem es zur Modellierung des Core-DWH (zentrale DB zur Integration und Historisierung von Daten) verwendet und klassischen Data Marts (themenspezifische Datenaufbereitung) vorgelagert wird. D.h. Data Vault (in der Version 2.0) ist kein reiner Modellierungsansatz, sondern berücksichtigt ebenso die Gesamtarchitektur und die Weiterentwicklung eines Data Warehouse. Abbildung 1 fasst die Data Vault Architektur in vereinfachter Form zusammen.
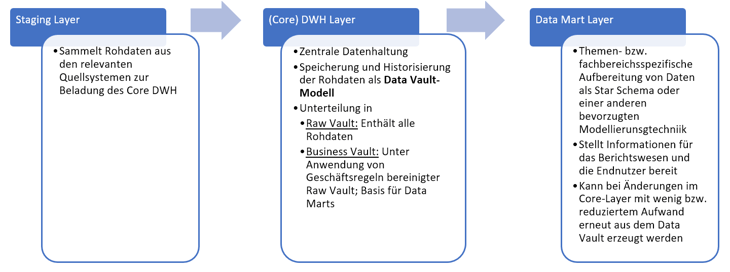
Abbildung 1: Data Vault - Architektur
Entwickelt wurde die Data-Vault-Modellierung in den 1990ern von Dan Linstedt, der zu dieser Zeit für die National Security Agency und das Department of Defense tätig war. Von diesen wurde er beauftragt eine einheitliche Modellierungstechnik für Data Warehouses zu entwickeln, welche es ermöglicht, diese nachträglich leicht zu erweitern und zu auditieren. Nach ersten Veröffentlichungen im Jahr 2000 erlangte Data Vault ab 2002 durch eine Reihe von Artikeln in "The Data Administration Newsletter" größere Aufmerksamkeit. 2009, 2011 und 2015 veröffentlichte Linstedt, teilweise zusammen mit anderen Autoren (u.a. Michael Olschimke), Bücher über Data Vault. Seit 2013 propagiert er unter der Bezeichnung Data Vault 2.0 ein Paket aus Modellierungs-, Architektur- und Methodologieansätzen.
Grundbausteine
Bei der Data Vault-Modellierung werden die Informationen in drei Kategorien eingeteilt und diese in entsprechenden Datenbanktabellen gespeichert:
- Hub: Der Hub ist das Kernobjekt der Geschäftslogik. Hierin werden die eindeutigen Business Keys gespeichert, die ein Geschäftsobjekt identifizieren. Z.B. Kundennummer, Rechnungsnummer oder Artikelnummer.
- Link: Ein Link verbindet Geschäftsobjekte (Hubs) miteinander und bildet somit die Beziehung zwischen den Informationen ab. Z.B. von einer Rechnungsnummer zu einer Kundennummer. Links unterstützen dabei immer N:M-Beziehungen, egal ob sie verwendet werden oder nicht.
- Satellit: Ein Satellit enthält eine Menge an Attributen, die ein Geschäftsobjekt (Hub) oder Beziehung (Link) beschreiben. Z.B. Name, Geburtsdatum oder Geschlecht. Attribute können auf verschiedene Satelliten verteilt werden (z.B. Trennung hinsichtlich DSGVO-relevant und Sonstige denkbar)
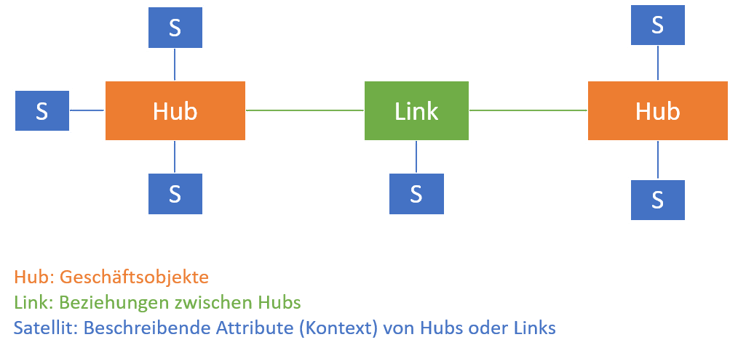
Abbildung 2: Data Vault - Modell
Durch die Art der Modellierung müssen bei Änderungen in den Quelldaten in der Regel keine bestehenden Tabellen angepasst werden, sondern es werden einfach neue Tabellen (z.B. zusätzliche Satelliten) hinzugefügt. In den Satelliten findet auch die Historisierung statt. Durch einen „INSERT-Only“ Ladeprozess sollen zudem immer nur zusätzliche Daten im Data Vault gespeichert werden (mit dem Zeitstempel des Einfügens). Letzteres trägt insbesondere zu einer Beschleunigung des Ladeprozesses bei, weil zeitaufwände Aktualisierungen und Löschungen vermieden werden.
Änderungen im Data Vault ziehen typischerweise auch Änderungen im Data Mart Layer nach sich. Da die Informationen im Data Vault jedoch immer der gleichen Struktur folgen und bspw. neue Attribute einfach in neuen Satelliten abgelegt werden, können Data Marts in vielen Fällen mit wenig Aufwand (oder sogar automatisiert) neu erzeugt oder auch als View bereitgestellt werden.
Die Data Vault - Methodik nach Linstedt unterscheidet zwischen dem Raw Vault, der 100% der Quelledaten enthält und dem Business Vault, welcher auf Basis des Raw Vaults aufgebaut und bereits unter Anwendungen von Geschäftsregeln bereinigt/verdichtet wird. Der Raw Vault folgt dabei einem eindeutigen Schema und kann daher automatisch erzeugt und beladen werden. Der Business Vault soll als Quelle für das nachgelagerte Berichtswesen bzw. die Data Marts dienen, welche eine gezielte themenspezifische Aufbereitung vornehmen.
Ein weiterer Grundbaustein von Data Vault ist Hashing. Dieses soll eingesetzt werden, um eindeutige Surrogate Keys auf Basis von einzelnen Business Keys in Hubs oder zusammengesetzten Business Keys in Links und Satelliten von Links zu generieren. Dies hat insbesondere folgende Vorteile:
- Schnelleres und besser parallelisierbares Beladen, da kein Lookup eines künstlich generierten Surrogate Keys (wie z.B. aufsteigende ID) notwendig ist. Dieser kann direkt als Hash von z.B. Kundennummer oder einem sonstigen zusammengesetzten Schlüssel berechnet werden. Dies ist insbesondere in verteilten Big Data-Umgebungen ein Vorteil, in denen nicht immer ein Zugriff auf alle Daten möglich ist
- Schnellere Joins: Links referenzieren potenziell sehr viele verschiedene Geschäftsobjekte. Jeder Satellit, welcher einen Link-Datensatz beschreibt, muss diese Spalten ebenfalls verwenden, um einen Datensatz eindeutig beschreiben zu können. Joins über viele Spalten mit unterschiedlicher Länge können schnell zu Performance-Problemen führen, während der Join über nur einen Hashkey (welcher auf Basis mehrerer Spalten erzeugt werden kann) deutlich schneller ist
Neben dem Hashing von Schlüsseln, kann die Hash-Differenz zum Erkennen von Veränderungen in Attributen (Satelliten) verwendet werden. Dies funktioniert, indem zu jedem Datensatz eines Satelliten ein Hashwert über die beschreibenden Attribute generiert wird. Beim Beladungsprozess wird dieser Hashwert auch für die Rohdaten erzeugt und nun zuerst geprüft, ob ein Hashwert bereits vorliegt (dann ist der Datensatz in der Ausprägung schon vorhanden) oder, ob sich der Hash-Wert zu einem Schlüssel geändert hat. Ist dies der Fall, kann ein neuer Datensatz mit neuem Gültigkeitszeitstempel eingefügt werden. Hierdurch kann er Ladeprozess (im Vergleich zum manuellen Vergleichen einzelner Spalten) weiter beschleunigt werden.

Data Vault als Kombination von 3 NF und dimensionaler Modellierung
Data Vault ist die logische Weiterentwicklung eines DWH-Datenmodells auf Basis der bisher gemachten Erfahrungen mit klassischen OLTP-Modellen (üblicherweise 3. NF) und dimensionaler Modellierung nach Kimball/Inmon. Neben einer flexiblen Erweiterbarkeit ermöglicht es einerseits schnelle Lade-/Schreibprozesse (Vorteil der 3. NF) sowie andererseits schnelle Lesezugriffe (Vorteil dimensionaler Modellierung). Dabei ist es als Kompromiss aus beiden Welten zu sehen, da nicht alle Ziele gleichzeitig und in gleicher Ausprägung erreicht werden können.
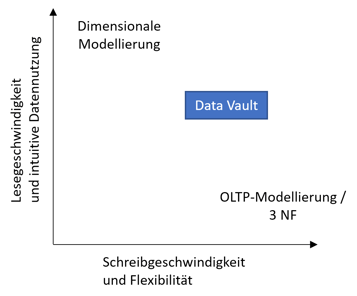
Abbildung 3: Data Vault als Kompromiss zwischen schnellen Lese- und Schreibzugriffen
Hierzu ein konkretes Beispiel: Eine Wohnungsgesellschaft hat ein Anwendungssystem entwickelt, welches zur Verwaltung von Immobilien, deren Besitzern sowie Mietern genutzt wird. Der grundsätzliche Aufbau des Systems (Tabellen und Beziehungen) bleibt i.d.R. über längere Zeit unverändert, jedoch finden durch die tägliche Nutzung verschiedener Service Mitarbeiter viele Schreibvorgänge statt. Sei es für die Anlage neuer Objekte oder die Aktualisierung bestehender. Ein hierfür bewährtes relationales Datenmodell ist die dritte Normalform, welche eine Balance aus Redundanz, Performance und Flexibilität anstrebt und insbesondere für schnelle Schreibzugriffe optimiert ist. Ein solches Modell ist vereinfacht in Abbildung 4 abgebildet.
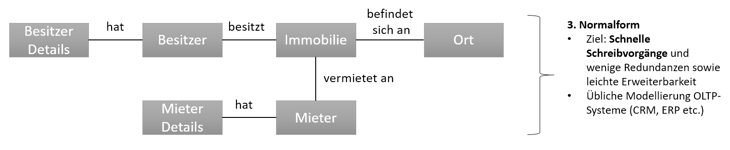
Abbildung 4: Dritte Normalform
Neben dem beschriebenen Anwendungssystem für die tägliche Arbeit der Service Mitarbeiter wurde ein klassisches Data Warehouse nach Kimball aufgebaut, in dessen Zuge unter anderem das in Abbildung 5 dargestellte Sternschema erstellt wurde, welches zur Analyse der Mieteinnahmen, Kosten und Wohneinheiten genutzt wird. Um historische Veränderungen in den Daten nachvollziehen zu können, wurde für die Dimensionen eine Typ 2-Historisierung (nach Kimball) eingerichtet, welche jedem Datensatz einen Gültigkeitszeitraum zuweist, welcher bei neuer Beladung geprüft/aktualisiert werden muss. Die Data Warehouse-Abteilung ist immer wieder vor die Herausforderung gestellt, dass die Geschäftsleitung plötzlich neue Aspekte auswerten möchte, seien es neue Attribute in den Dimensionen, andere Geschäftszahlen oder einfach eine andere Granularität der Auswertung. Dadurch müssen das bestehende Sternschema und auch die Beladungsprozesse (inkl. Historisierung) häufig und aufwändig angepasst werden.
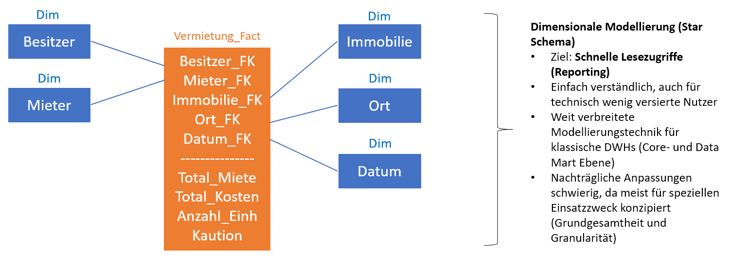
Abbildung 5: Dimensionale Modellierung
Hier setzt Data Vault an: Durch den Insert-Only-Ansatz können neu angeforderte Informationen (und ebenso deren Historisierung) mit wenig Aufwand - im Raw Vault sogar automatisiert - über neue Hubs, Links oder Satelliten ergänzt werden. Soll beispielsweise eine neue Eigenschaft der Mieter in einen Bericht einfließen, kann diese über eine neue Satellitentabelle dem Hub „Mieter“ hinzugefügt werden. Bestehende dimensionale Modelle bzw. Data Marts bleiben von dieser Änderung erst einmal unberührt und müssen nicht getestet werden. Die Integration des neuen Feldes in das relevante dimensionale Modell ist in diesem Fall einfach, da alle Informationen (auch die Historisierung) im Data Vault enthalten sind und das Modell hieraus erneut erzeugt und aktualisiert werden kann.
Auch größere Änderungen innerhalb des Quellsystems (3. NF) lassen sich im Data Vault leicht berücksichtigen: Wird zum Beispiel aus einer 1:N-Beziehung zwischen Mieter und Immobilie eine N:N-Beziehung, weil plötzlich Immobilien von Wohngemeinschaften bewohnt werden können, so würde dies im Quellsystem zu einem größeren Redesign (u.a. Anlage neuer Beziehungstabellen) führen, während diese Beziehung im Data Vault-Modell bereits berücksichtigt ist. Denn Links unterstützen immer N:N-Beziehungen.
Natürlich gibt es auch Änderungen oder Anforderungen der Fachabteilungen, die mit einem erhöhtem Anpassungsaufwand im Data Vault oder im Data Mart einhergehen. Dennoch werden viele typische und häufig durchgeführte Änderungen und Erweiterungen vereinfacht.
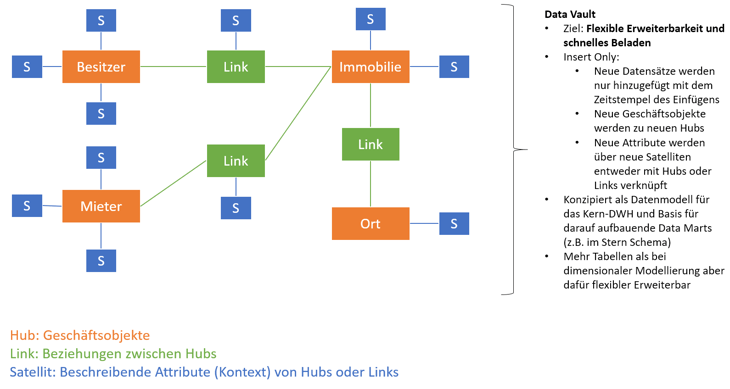
Abbildung 6: Data Vault - Modellierung
Gibt es auch Nachteile?
Dadurch, dass ein Data Vault-Modell eine Aufteilung der Informationen in Hubs, Links und Satelliten vorsieht und neue Informationen immer über neue Tabellen hinzugefügt werden (Insert-Only), kann die Anzahl der Tabellen eines Data Vault-Modells schnell anwachsen. Abhilfe hierbei kann der Ansatz „Data Warehouse Automation“ liefern, bei dem ein Data Vault-Modell toolgestützt erzeugt, befüllt und verwaltet wird. Ein prominenter Anbieter einer solchen Lösung ist WhereScape.
Das für die Schlüsselgenerierung und Änderungserkennung verwendete Hashing birgt die geringe, aber dennoch vorhandene, Gefahr der Schlüsselkollision. D.h. in extrem seltenen Fällen kann es vorkommen, dass verschiedene Eingangswerte zum gleichen Hashwert führen. Bei einem MD5 HashKey beträgt die Wahrscheinlichkeit etwa 1 : 2^128. Im Falle einer Kollision müssen alle Hashkeys im Data Vault neu berechnet werden, um die Eindeutigkeit wiederherzustellen.
Auf Grund der relativen Neuheit im Vergleich zur klassischen DWH-Architektur und Modellierung nach Kimball/Inmon gibt es bisher nur wenig Literatur und wenige Praxisbeispiele. Falls Sie sich für das Thema interessieren oder darüber nachdenken Data Vault in einem Ihrer Projekte einzusetzen, stehen wir Ihnen gerne mit Rat und Tat zu Seite.
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



