

Unsere Erfahrungen aus einem Kundenprojekte in der Energiebranche bereiten wir in einer dreiteiligen Serie auf. Erfahren Sie wie Datenmigration mit RPA gelingt, welche organisatorischen Rahmenbedingungen beachten werden müssen und wie RPA-Entwicklung mit mateo umgesetzt werden kann.
Im dritten Teil unserer Blog-Reihe über Robotic Process Automation (RPA) geht es um den praktischen Einsatz von mateo rpa. Wir stellen Ihnen den RPA-Prozess des Migrationsprojekts vor und geben Ihnen einen Einblick, wie wir mit mateo rpa Prozessschritte automatisiert haben und welchen Herausforderungen wir gegenüberstanden. Wie in den beiden vorangegangen Artikeln, basieren die Erkenntnisse auf den Erfahrungen aus einem unserer Kundenprojekte in der Energiebranche.
Was sie erwartet
In den beiden vorangegangen Blog-Artikeln haben wir Ihnen erklärt, warum RPA als Lösungsansatz zur Datenmigration geeignet sein kann und welche organisatorischen Aspekte beim Einsatz zu beachten sind.
Im Folgenden möchten wir Ihnen den RPA-Prozess des Migrationsvorhabens aus der Perspektive von Entwickler:innen näherbringen. Wir werden Ihnen die einzelnen Prozessschritte vorstellen und erläutern, wie wir diese integriert und parallelisiert haben. Darüber hinaus gehen wir auf das Thema Datenbereinigung ein, das im Verlauf der Migration eine wichtige Rolle spielte.
Der Artikel richtet sich an technisch interessierte Manager:innen, (RPA-)Entwickler:innen oder solche die es einmal werden möchten und an alle, die einen Einblick in mateo rpa erhalten möchten.
RPA-Prozess
Der RPA-Prozess zur Migration der Kundendaten aus den Quellsystemen in das Zielsystem gliedert sich in drei Prozessschritte: Stammdaten sammeln, Kunden anlegen und Stammdaten erweitern. Für jeden dieser Prozessschritte wurde ein Automationsskript entwickelt. Darüber hinaus gibt es weitere Skripte zur Integration und Parallelisierung der Prozessschritte.
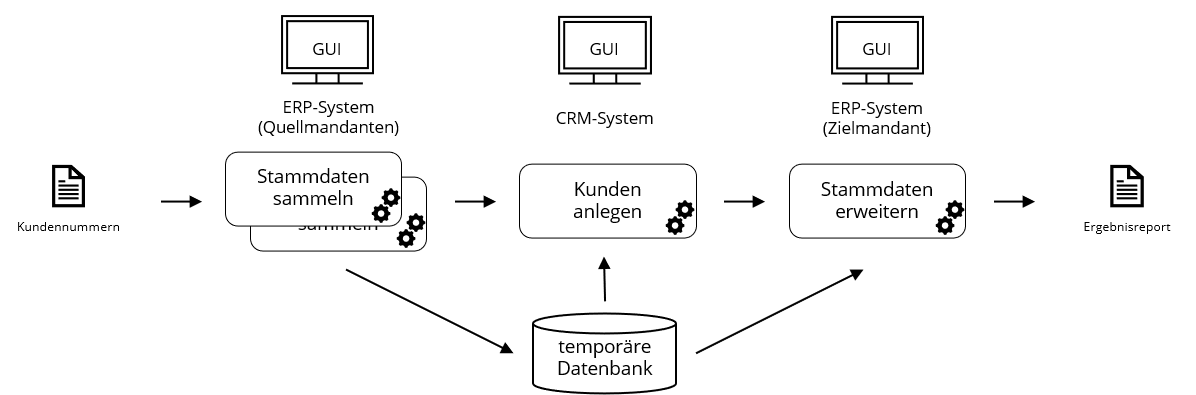
Automatisierte Prozessschritte
Im ersten Prozessschritt wurden die zu migrierenden Kundenstammdaten gesammelt. Ausgangspunkt für mateo rpa war eine CSV-Datei mit den Kundennummern der zu migrierenden Kunden. Eine Herausforderung beim Auslesen der Stammdaten bestand darin, dass die zu migrierenden Datenfelder nicht in einer Tabelle zu finden waren. Es war auch nicht möglich, über das ERP-System eine eindeutige Abfrage für einen Kundendatensatz zu erstellen. Ein Datenbankzugriff stand uns nicht zur Verfügung. Stattdessen mussten wir mit mateo mehrere Listen mit relevanten Kundendaten, wie beispielsweise Namens-, Adress- oder Bankdaten, auslesen. Diese haben wir anschließend anhand der Kundennummer automatisiert zu einer Ansicht zusammengefasst, die uns einen eindeutigen und aktuellen Datensatz mit allen migrationsrelevanten Datenfeldern lieferte.
Im zweiten Prozessschritt wurden die gesammelten Kundenstammdaten im Zielmandanten angelegt. Die Anlage der Stammdaten war nicht über das ERP-System möglich. Daher mussten wir den Umweg über das Kundenmanagement-System gehen. Hierbei handelte es sich um eine Webanwendung, welche ausschließlich über den Internet Explorer bedient werden durfte. Das entwickelte Automationsskript hat pro Ausführung genau einen Kunden angelegt. Das Skript musste also mehrere Tausend mal gestartet werden, um alle Kunden anzulegen. Um dies nicht manuell zu tun, haben wir mateo mit Hilfe eines kleinen Batchskriptes von außen gesteuert. Mateo stellt hierzu eine Schnittstelle bereit. Dementsprechend bestand das Batchskript aus einer einfachen Schleife mit N Durchläufen, die pro Durchlauf eine Anfrage an mateo sendet, um das Skript zu starten, und darauf wartet, dass das Skript fertig ausgeführt wird.
Beispiel – Web-Automatisierung mit mateo rpa
Für die Automatisierung von Webanwendungen greift mateo rpa auf das Open-Source-Framework Selenium zurück und stellt dazu benutzerfreundliche Kommandos bereit. Mit Kommandos wie clickWeb, sendTextWeb oder getTextFromElementWeb ist es möglich Elemente des Systems zu bedienen, Eingaben zu tätigen oder Informationen zu erhalten. Zudem unterstützen Kommandos, wie equalsAlpha, if, then und else dabei, Werte zu prüfen und Kontrollstrukturen umzusetzen.
step Kundenanlage prüfen:
Im letzten Prozessschritt wurden die Stammdaten erweitert und es wurde überprüft, ob ein Kunde vollständig sowie fehlerfrei migriert wurde. Dies war notwendig, da nicht der gesamte Kundenstamm über das Kundenmanagement-System angelegt werden konnte. Einige Datenfelder, wie zum Beispiel Bankverbindungen oder die Einstellung der Zahlungswege, konnten ausschließlich über das ERP-System gepflegt werden. Eine finale Überprüfung der korrekten Anlage des Kundenstamms war im Sinne der Qualitätskontrolle opportun. Die Ausführungssteuerung dieses Skripts erfolgte analog zum Anlegen der Stammdaten über ein Batchskript.
Beispiel – SAP-Automatisierung mit mateo rpa
Zur Automatisierung eines nicht-webbasierten SAP-Systems greift mateo rpa auf einen AutoIt Treiber zurück und stellt hierzu Kommandos bereit, um alle Elemente des Systems zuverlässig zu steuern. Beispielhafte Kommandos heißen hier sapObjSelect, sapObjValueSet oder sapObjValueGet. Mittels Konstanten (%-Schreibweise), zentral definierte Schlüssel-Wert-Zuordnungen, können schwer verständliche SAP-Objekt-IDs in das Automationsskript integriert werden.
step Anlage Bankverbindung prüfen:
Integration, Parallelisierung und Datenhaltung
Darüber hinaus ist für die Integration der drei Prozessschritte ist eine Betrachtung der Datenhaltung notwendig.
Damit die ausgelesenen Kundenstammdaten aus dem ersten Prozessschritt als Input für die folgenden Automationsskripte dienen konnten, mussten diese zwischengespeichert und in eine zeilenweise abzuarbeitende Form transformiert werden. Dazu wurde eine temporäre Datenbank für den Zeitraum der Migration aufgebaut. Diese enthielt verschiedene Tabellen mit den Kundenstammdaten sowie eine Tabelle zur Steuerung der einzelnen Prozessschritte. Um zum einen zu vermeiden, dass einzelne Datensätze mehrfach abgearbeitet werden und um zum anderen den Bearbeitungsstatus eines jeden Datensatzes nachvollziehen zu können, haben wir verschiedene Statuswerte gebildet. Zu Beginn der Skriptausführung konnte auf diese Weise ein zu migrierender Datensatz mit einem Status ‘zu_bearbeiten‘ selektiert werden und auf den Status ‘in_bearbeitung‘ gesetzt werden. Abhängig vom Erfolg der weiteren Skriptausführung wurde der Datensatz im Anschluss als ‘erfolgreich_bearbeitet‘ oder ‘fehlerhaft_bearbeitet‘ gekennzeichnet.
Zur Erhöhung der Migrationsgeschwindigkeit wurde mateo rpa auf mehreren Rechnern installiert. So konnten mehrere Datensätze parallel migriert werden. Hierfür musste jeder Rechner Zugriff auf die temporäre Datenbank mit den Stammdaten haben. Es lag die Überlegung nahe, einen Datenbank-Server einzurichten, auf den jede mateo Instanz Zugriff hätte. Dies war jedoch aus organisatorischer und IT-Security-konformer Sicht schwierig umzusetzen. Daher beschlossen wir mit einem verschlüsselten internen Netzlaufwerk und mit mehreren lokalen Datenbanken auf den jeweiligen Rechnern mit den mateo rpa Instanzen zu arbeiten. Um dieses Szenario zuverlässig und automatisiert umzusetzen und dabei nicht die Kontrolle über die zu migrierenden Daten zu verlieren, wurde auf einem der Rechner eine Art „Master-Datenbank“ erstellt. Diese diente als zentrale Datenbasis, aus welcher die Daten auf die anderen Rechner verteilt und in welcher die bearbeiteten Daten wieder zusammengeführt wurden. Zum Verteilen, Importieren und Zusammenführen der Datensätze wurden wiederum Automationsskripte entwickelt. Diese dienten damit als unterstützende Skripte zur Integration und Parallelisierung der Prozessschritte.
Beispiel - Datenbank-Automatisierung mit mateo rpa
Mit mateo lässt sich mehr als nur das User-Interface von Anwendungen automatisieren. Mit Kommandos wie openSql, querySql, executeSql und closeSql kann die Arbeit mit unterschiedlichsten Datenbanken automatisiert werden. Es lassen sich nicht nur einzelne SQL-Statements ausführen, sondern auch ganze SQL-Skripte. Das Abfrageergebnis liegt im JSON-Format vor. Mit dem Kommando queryJson können einzelne Werte selektiert werden.
Datenbereinigung vor und während der Migration
Die Bereinigung und Transformation der zu übertragenden Daten hat während der Migration einen hohen Zeit- und Ressourcenanteil in Anspruch genommen. Im Zuge der Anforderungsanalyse konnte nicht jede mögliche Stammdatenkonstellation in einem angemessenen Zeitaufwand hinreichend spezifiziert werden. Dies führte dazu, dass sowohl während der Entwicklung als auch während des Go-Lives und Betriebs auf dem produktiven System Sonderfälle bei bestimmten Datenkonstellationen auftauchten und geklärt werden mussten. Durch die enge Zusammenarbeit mit den Mitarbeiter:innen der Fachabteilung unseres Kunden war es möglich, schnelle Entscheidungen für den Umgang mit diesen Sonderfällen zu treffen.
Bereits während der Entwicklung der Automationsskripte auf den Testsystemen mit pseudonymisierten Echtdaten wurde festgestellt, dass einige Datensätze nicht mehr den aktuellen Anforderungen an die Stammdaten entsprachen und in ihrer derzeitigen Form gar nicht migriert werden konnten. In diesen Fällen wurde im Automationsskripte definiert, wie mit diesen Datensätzen umgegangen werden sollte.
Beispiel: Bei der Anlage eines neuen Kunden im Kundenmanagement-System gab es ein Dropdown-Menü zur Selektion der korrekten Anredeform. Die Auswahl der zur Verfügung stehenden Anredeformen hatte sich jedoch im Verlaufe der Zeit verändert. Im Kundenmanagement-System wurde die Anrede „Lebensgemeinschaft“ nicht mehr unterstützt. Im ERP-System wurde diese Anredeform jedoch weiterhin geführt. In diesem Fall wurde definiert, dass aus der Anrede „Lebensgemeinschaft“ die Anrede „Herrn/Frau“ werden sollte.
Trotz umfänglicher Tests zeigte sich während der Migration, dass die zu migrierenden Daten an einigen Stellen nicht immer der Erwartungshaltung entsprachen.
Beispiel: Die Migration der Kundenstammdaten hat unter anderem die Übertragung der E-Mail-Adresse des Kunden beinhaltet. Ausgehend von den Anforderungen wurde erwartet, dass jedem Kunden genau eine E-Mail-Adresse zugeordnet ist. Im Kundenmanagement-System gab es ein entsprechendes Textfeld, in welches diese eingetragen werden sollte. Nachdem alle zu migrierenden Daten ausgelesen worden waren, zeigte sich, dass in etwa 0,1 Prozent der Fälle zwei E-Mail-Adressen zu einem Kunden hinterlegt worden waren. Welche E-Mail-Adresse sollte nun migriert werden? Da diese Möglichkeit während der Anforderungsanalyse und Entwicklung der Skripte nicht bedacht worden war, wurden die entsprechenden Datensätze aussortiert und an die Fachabteilung weitergeleitet. Im Nachhinein stellte sich heraus, dass es in der Vergangenheit Überlegungen zur Hinterlegung einer zweiten E-Mail-Adresse gegeben hatte und dass die in diesem Kontext testweise modifizierten Stammdaten nicht wieder bereinigt worden waren.
Sonderfälle wie diese, die während der Migration identifiziert und nicht abschließend geklärt werden konnten, wurden zur manuellen Migration an die Fachabteilung weitergeleitet. Dies geschah manuell und auf Basis der Analyse nicht erfolgreich verarbeiteter Datensätze aus der temporären Datenbank. Die Integration der Fachabteilung in den RPA-gestützten Prozess der Datenmigration war damit ein wichtiger Baustein.
Fazit
In unserer dreiteiligen Blog-Serie haben wir den Einsatz von RPA zur Datenmigration aus unterschiedlichen Blickwinkeln beleuchtet. Im ersten Teil haben wir erläutert, warum RPA in unserem Kundenprojekt als geeigneter Lösungsansatz in Frage kam und welche Überlegungen bei dieser Entscheidung gegeneinander abzuwägen waren. Im zweiten Teil haben wir das Projekt aus organisatorischer Sicht betrachtet und die Interessen der verschiedenen Anspruchsgruppen sowie die zu berücksichtigenden Sicherheitsaspekte thematisiert. Im vorliegenden Artikel wurde die praktische Umsetzung des Projektes mit mateo rpa erörtert.
mateo hat sich als zuverlässige und flexibel einsetzbare Automatisierungslösung bewährt. Der gesamte Migrationsablauf konnte von mateo übernommen werden. Dabei wurden nicht nur unterschiedliche Anwendungen über das User-Interface automatisiert gesteuert, sondern auch die Arbeit mit Datenbanken. Einzig für das Starten der drei Prozessschritte und die Analyse und Bereinigung von Sonderfällen wurde in den Gesamtprozess eingegriffen. Die einfache und intuitive Entwicklung mit mateo ermöglichten eine schnelle Umsetzung des Prozesses innerhalb von 2-3 Wochen von einer Person.
Sie fragen sich, ob RPA auch für Ihr Migrationsvorhaben der richtige Ansatz ist oder Sie haben Fragen, wie Sie Ihr eigenes Automationsvorhaben in die Tat umsetzen können? Wir beraten und unterstützen Sie gerne.
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



