
 MLOps-Plattformen wie z. B. Kubeflow versprechen Data Scientists viele Vorteile. Sobald man die Tutorials und Beispiel-Pipelines hinter sich gelassen hat, stößt man bei der Zerlegung des Workflows in unabhängige Komponenten allerdings auf einige Probleme. Wir berichten hier aus unseren Erfahrungen mit entsprechenden Kubeflow-Pipelines.
MLOps-Plattformen wie z. B. Kubeflow versprechen Data Scientists viele Vorteile. Sobald man die Tutorials und Beispiel-Pipelines hinter sich gelassen hat, stößt man bei der Zerlegung des Workflows in unabhängige Komponenten allerdings auf einige Probleme. Wir berichten hier aus unseren Erfahrungen mit entsprechenden Kubeflow-Pipelines.
Die Ziele von Kubeflow und vergleichbaren Plattformen sind verlockend: Wir hoffen darauf, die Lebenszyklen von ML-Modellen einfach in automatisierten, skalierbaren und reproduzierbaren Pipelines zu orchestrieren und die Machine Learning (ML)-Systeme somit erfolgreich in Produktion zu bringen. Mit der Skalierbarkeit ist sowohl der Umgang mit großen Datenmengen gemeint als auch die sinnvolle Arbeit in großen Teams an mehreren Fragestellungen.
In diesem Blogpost gehen wir auf unsere Erfahrungen mit der MLOps-Plattform Kubeflow Pipelines (KFP) ein, die dabei aufgetretenen Probleme und jeweilige Lösungsansätze ein.
Modulare Komponenten in ML – Was wollen wir erreichen?
Für die Erstellung einer End-to-End Pipeline wird ein ML-Workflow in einzelne Komponenten aufgeteilt und die Schritte somit, gemäß dem Design Pattern Separation of Concerns, logisch voneinander getrennt. Dieser modulare Aufbau macht Pipelines hochflexibel und Komponenten können, einmal geschrieben, in anderen Kontexten beliebig wiederverwendet werden.
Was zunächst nach oberflächlichen Buzzwords klingt, scheint mit der Kubeflow Plattform erstmals realistisch erreichbar: Jeder Arbeitsschritt wird in einem Container gekapselt und ist auf diese Weise isoliert und reproduzierbar.
Es entstehen ganze ML-Ökosysteme, wie bspw. AI Hub von Google mit dem Ziel eine Zusammenarbeit und die Reusability von Anwendungen und Ressourcen im ML-Umfeld zu fördern. Die Modularität erhöht nicht nur die Transparenz der Pipeline durch Nachvollziehbarkeit der automatisch archivierten Komponentenergebnisse (gut für Debugging), sondern sollte generell auch das Schreiben komponentenbasierter Unit-Tests erleichtern (gut zur Qualitätssicherung).
Auf die Fragen, was bei ML-Systemen wie intensiv getestet werden soll, um eine Production Readiness und eine Reduzierung der technischen Schulden ("technical debts") zu erreichen, geht Google in einem Paper genauer ein. Da technische Schulden dazu tendieren, sich zu vermehren, sollte von Anfang an auf die dort aufgeführten Tests der Trainingsdaten, der Modellentwicklung und des Monitorings während des Einsatzes sowie auf Infrastrukturtests geachtet werden. Letzteres bezieht sich u. a. auf den Determinismus der Pipeline-Schritte, z. B. des Trainings, bei dem dieselben Daten dieselben Modelle produzieren sollten, und auf das Unit Testing der Modellspezifikation, d. h. der API-Nutzungen und der algorithmischen Korrektheit.
Auch bei Googles empfohlenen, ML-zentrierten Test sind deterministische Schritte mit gekapselter Logik für die Produktionsreife eines ML-Modells bzw. der ML-Pipeline immer anzustreben. Die Überlegungen in diesem Research Paper haben letztlich zur Entwicklung von TFX und Kubeflow geführt. Jetzt gilt es diese Ziele einzulösen.
Probleme mit modularen Komponenten in Kubeflow Pipelines
Eine Kubeflow-Pipeline besteht aus mehreren orchestrierten Komponenten (sog. Operations), welche Ergebnisse (Outputs) produzieren können, die von nachfolgenden Komponenten konsumiert und weiterverarbeitet werden können.
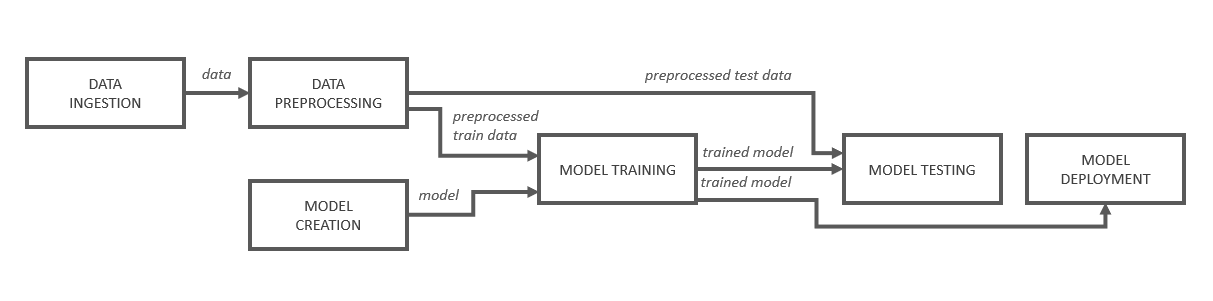
Abbildung 1: Schematischer Aufbau einer ML Pipeline
In Abbildung 1 ist eine Beispielpipeline schematisch aufgeführt. Dort empfängt die „Model Training“ Komponente vom „Model Creation“ Schritt die Referenz zu einem Modell, welches dann geladen und mit den in einem anderen Schritt vorverarbeiteten Trainingsdaten trainiert wird. Durch den Datenfluss leitet Kubeflow automatisch einen Directed Acyclic Graph (DAG) ab.
Jede containerisierte Komponente wird bei Ausführung in einer Pipeline in ihrem eigenen Kubernetes-Pod gestartet. Das bringt maximale Flexibilität: Wechselnde Programmiersprachen und Versionen von Frameworks können sich bei Bedarf mischen.
Im einfachen Idealfall besteht ein Projekt nur aus einem Stück Python-Code und der DAG wird ebenfalls in Python deklariert. Das Modulkonzept hat zur Folge, dass Module keine Abhängigkeiten "nach oben" (also zu ausführendem Code) auflösen können und der Code aus diesem Grund self-contained sein muss, d. h. die ganze für die Ausführung notwendige Funktionalität muss direkt in der Modul-Methode selbst definiert sein. Auch verwendete Bibliotheken sind dort lokal zu importieren.
Eine Wiederverwendung zentral bereitgestellter Funktionalitäten (z. B. aus Helper-Modulen) ist in vielen Fällen sehr sinnvoll und gewünscht, dadurch jedoch schwer möglich. Die benötigten Funktionen können zwar in Submethoden der Komponenten verpacken werden, wodurch die Komponenten allerdings unnötig groß werden und der Boilerplate Code durch sein Vorkommen an mehreren Stellen schwer wartbar und ggf. inkonsistent wird. Außerdem sind Submethoden in Python nicht sinnvoll testbar: Unit-Tests sind dadurch nur auf ganze Operationen anwendbar. Ob eine ganze komplexe Operation mit mehreren Verarbeitungsschritten dabei noch als einzelne Unit betrachtet werden kann bzw. sollte, ist fraglich, da sich Unit-Tests vor allem durch kleine, logisch voneinander getrennte Teilbereiche eines Systems auszeichnen.
Die Kubeflow-Komponenten laufen in eigenen Pods, weshalb sie sich kein gemeinsames Dateisystem teilen und alle verarbeiteten Daten nach dem Terminieren des Pods verloren gehen. Um eine Weiterverarbeitung der produzierten Daten zu ermöglichen, geschieht der Datentransfer zwischen den Komponenten i. d. R. mithilfe von explizit vereinbarten Übergabepunkten, den sog. OutputPaths und InputPaths. Auf diese von Kubeflow bereitgestellten Dateipfade, welche entweder auf einen Persistent Volume Claim (PVC) oder einen Cloud Storage Service verweisen, können Komponenten Dateien speichern und laden. Da die Ergebnis-Artifacts aus jeder Komponente aller Pipelinedurchläufe von Kubeflow zuverlässig archiviert werden, kann es zu Problemen führen, wenn beispielsweise einen Datensatz mit Tausenden hochauflösenden Bildern verarbeitet und immer zwischenspeichert werden muss. Auf einige dabei auftretende Probleme sowie auf Lösungsvorschläge gehen wir in diesem Blogpost ein. Daher ist eine Auslagerung der Helper-Funktionen in eigene Komponenten meist auch nicht erwünscht - um das mehrfache Zwischenspeichern der Daten zu verhindern, aber auch um die logische Struktur der Pipeline aufrechtzuerhalten und sie nicht unnötig unübersichtlich zu gestalten.
Lösungsansätze: Wie kann die Wiederverwendbarkeit von Code innerhalb von Kubeflow Komponenten umgesetzt werden?
Wie bereits erwähnt ist es sinnvoll, eine Komponente möglichst schlank zu halten, um sowohl die Wartbarkeit und Testbarkeit der Komponente als auch der in ihr verwendeten Helper-Funktionen zu ermöglichen. Für manche Aspekte ist es auch schlicht fachlich wichtig, dass diese überall identisch umgesetzt werden und bei Bedarf an zentraler Stelle weiterentwickeln werden können. Es gilt also gängige Visualisierungen, Datenqualitätsprüfungen und Vorverarbeitungsschritte wie bspw. eine Kontrastverstärkung oder Feature-Imputation auszulagern.
Aber wie wird dann auf diesen ausgelagerten Code aus einer Kubeflow Pipeline heraus sinnvoll zugegriffen?
In unseren Projekten mussten wir uns mit dieser Frage beschäftigen und gehen nachfolgend auf mehrere Möglichkeiten und Workarounds ein, die sich abhängig von dem Reifegrad der Helper-Funktionen mehr oder weniger gut eignen. Dabei konzentrieren wir uns auf die Data Scientist- und experimentierfreundliche Komponentenerstellung innerhalb eines Jupyter Notebooks mithilfe von func_to_container_op. Diese Funktion der Kubeflow Python domain-specific language (DSL) ermöglicht es direkt aus Python-Funktionen unter Angabe eines spezifischen Docker Images Kubeflow-Komponenten zu erstellen.
Den Code als Package zur Verfügung stellen
Sofern die Entwicklung der wiederverwendbaren Helper-Funktionen bereits abgeschlossen ist, können sie in einem Package in einem öffentlichen (z. B. Python Package Index (PyPI)) oder privaten Repository zur Verfügung gestellt werden. Dieses Code Sharing ist sehr sinnvoll, um getesteten Code team- bzw. sogar organisationsübergreifend zur Verfügung zu stellen.
Um diese innerhalb der Operation importieren und verwenden zu können, stehen einem zwei Optionen zur Auswahl:
1. Es wird ein benutzerdefiniertes Docker-Image, welches das Package bereits vorinstalliert hat, gebaut und als Base-Image in func_to_container_op verwendet.
2. Zu installierende Pakete werden an func_to_container_op als „packages_to_install“ Argument übergeben. Diese übergebene String-Liste (versionierter) Packages wird vor Ausführung der Komponentenfunktion automatisch von Kubeflow mittels „pip install“ installiert.
Beide Optionen setzen allerdings voraus, dass der Code innerhalb des Packages einen gewissen Reifegrad aufweist, da jede Iteration einer Weiterentwicklung recht umständlich ist. Änderungen sollten dokumentiert, getestet und der Code mit einer Versionsverwaltung, z.B. git, getaggt werden, bevor das Package neu gebaut und im Repository veröffentlicht werden kann.
Für Code im Entwicklungsstadium, der oft geändert wird, ist dieser Ansatz zu unhandlich.
Die Nutzung eines zugänglichen Volumes für den Code
Eine weitere Möglichkeit ist die Speicherung des Codes auf einem Kubernetes Persistent Volume. Im Prinzip ist ein Volume ein Verzeichnis, auf dessen Dateien Pods zugreifen können, wenn sie dieses unter einem angegebenen Pfad mounten. Wenn die einzelnen Komponenten das Volume jeweils mounten, können die Dateien dort importiert oder aufgerufen werden und die Persistenz des Helper-Codes ist nicht an den Lebenszyklus der Pods gebunden.
Dies wollen wir an einer Beispielkomponente ausprobieren, welche die Funktion test aus dem Modul helper aufruft.
In der Methode, die zu einer Operation konvertiert wird, muss das übergeordnete Verzeichnis sowie der Volume-Pfad zum Systempfad hinzugefügt werden, sodass der Python Interpreter das Verzeichnis nach den benötigten wiederverwendbaren Modulen durchsuchen kann - und fündig wird. In der Pipeline wird das Volume mit dem PVC „sharedcode“, auf dem das Helper-Modul liegt, nun in dem „test“ Task unter „/sharedcode“ eingehängt.
Falls Jupyter Notebooks zur Entwicklung verwendet werden und die Pipelines dieselben Volumes mounten, eignet sich dieser Lösungsansatz sehr gut, wenn sich der Code noch in der Entwicklung befindet: Änderungen können direkt in der Benutzeroberfläche vorgenommen werden und die Funktionalität wird bei Neustart der Pipeline automatisch aktualisiert. Wenn der von git verwaltete Workspace nicht dem des Volumes entspricht, muss allerdings auf die Versionierung der dort liegenden Dateien geachtet werden. Um immer die aktuelle Version zu verwenden und Inkonsistenzen zu vermeiden, ist eine Prüfung bzw. ein Herüberkopieren der benötigten Dateien vor jeder Pipeline-Ausführung zu empfehlen. Auch sollte man sicherstellen, dass das ausgewählte Volume verfügbar ist und den „accessMode“ „ReadWriteMany“ hat, sodass es von mehreren Pods (gleichzeitig) gemountet werden kann.
Diese Lösung macht Kollaboration einfach, aber auch potenziell riskant: Es könnte jederzeit Änderungen von anderen Team-Mitgliedern geben - auch während eine Pipeline läuft.
Die Verwendung einer ConfigMap
ConfigMaps sind Kubernetes-Objekte, die zum Speichern nicht vertraulicher Daten in Schlüssel-Wert-Paaren verwendet wird. Sie sind innerhalb eines Kubernetes Namespaces verfügbar und können auch in Kubeflow-Pipelines (im jeweiligen Namespace) verwendet werden. I. d. R. werden sie zur Speicherung umgebungsspezifischer Konfigurationen verwendet, allerdings lassen sich auch einzelne Dateien oder ganze Ordner mit Python Code in ein YAML Format überführen. Die ConfigMaps können in Form von Volumes an die Pods gemounted werden. Die Keys werden dabei als Dateinamen verwendet, sofern kein spezifisches Mapping von Key zu Dateipfad angegeben wird.
Es wird eine ConfigMap "helpercm" mit dem reusable Code der Datei "helper.py" erstellt, was überprüft werden kann.
Innerhalb der Pipeline wird dann das Volume erstellt und analog zu dem Code der Pipeline "pipeline_volume" an den Pod gemounted. Die oben aufgeführte test_func bleibt dabei unverändert
Der Workaround mit den ConfigMaps ist im Vergleich zu der Volumes-Alternative leichtgewichtiger und sicherer, da das Volume nur zur Laufzeit der Pipeline existiert.
Den Code mit "modules_to_capture" injizieren
In einem letzten Lösungsvorschlag stellen wir das „modules_to_capture“ Argument der func_to_container_op vor. Herauszufinden, wie das Argument genau genutzt werden kann, war mit etwas Aufwand verbunden. Wenn man die nachfolgend aufgeführten Schritte beachtet, ist die Verwendung allerdings einfach und im Vergleich zu den obigen Varianten sehr komfortabel.
- Ähnlich wie dem „packages_to_install“ wird der Name des Moduls als Zeichenkette übergeben.
- Es muss davor global, d. h. außerhalb der Komponenten-Funktion, die es benötigt, geladen werden (z. B. im Jupyter Notebook).
- Der Code wird mittels code-pickling serialisiert und in die Komponente injiziert. Dafür wird im Hintergrund „cloudpickle“ verwendet, weshalb dieses zusätzlich als Package installiert werden muss (packages_to_install=['cloudpickle']). Die Abhängigkeiten in dem Modul werden ebenfalls serialisiert, weshalb das Helper-Modul auch Gebrauch von weiteren Paketen machen kann.
- Innerhalb der Komponente werden die übergebenen Module deserialisiert und sind dann normal und ohne weitere Importe verwendbar.
Die Vorteile dieses Ansatzes sind, dass sich die Helper-Module auch im aktuellen Workspace befinden können, was eine einfache Verwaltung des Moduls mit git ermöglicht. Da die Serialisierung bei Erstellung der Komponente erfolgt, werden Code-Änderungen an den Helper-Funktionen sofort übernommen.
Fazit
Auch wenn Kubeflow stark zur Wiederverwendung ganzer Komponenten (in Form von YAMLs) ermutigt, ist die Unterstützung bei der Wiederverwendung von kleineren Funktionalitäten (z.B. aus Helper-Modulen) weiterhin nur schwer möglich. Daher wurden in diesem Beitrag vier Lösungsansätze aufgeführt, die es ermöglichen, Funktionalitäten in Kubeflow Komponenten trotz ihrer starken Kapselung wiederzuverwenden.
Eine optimale Lösung gibt es (noch) nicht und hängt vom Projekt sowie vom Entwicklungsstadium des wiederverwendbaren Codes ab. Zusammenfassend kann man sagen, dass sich bei der Verwendung bereits veröffentlichter (versionierter) Packages die Installation via pip (Argument „packages_to_install“), oder die Angabe eines benutzerdefinierten Docker Images sehr gut eignen. Wenn man in einem (Jupyter) Notebook arbeitet, kann man Shared Code auf einem Volume ablegen, das sowohl von dem Notebook als auch von Pipelines gemounted wird. Änderungen des Codes über das Notebook werden direkt gespiegelt, weshalb sich dieser Modus gut eignet, wenn sich der Code noch im Entwicklungsstadium befindet. Alternativ kann man ihn in eine ConfigMap schreiben, die dann von jeder Komponente hinzugefügt wird. Dabei muss darauf geachtet werden, dass der Code immer up-to-date ist und dem im Workspace gleicht. Ggf. ist beim Volume ein Kopier-Zwischenschritt notwendig und bei der ConfigMap ein Update mittels „kubectl apply“. Ein Zwischenschritt fällt bei der letzten Variante mit „modules_to_capture“ aus. Änderungen werden direkt übernommen und weitere, darin verwendete Module, ebenfalls geladen.
Auch wenn diese Alternativen auf den ersten Blick umständlich wirken, lohnt sich ihre Anwendung. Man vermeidet Boilerplate Code, die Komponenten werden schlanker und sowohl sie, als auch die Helper-Methoden, sind besser testbar und wartbar. Außerdem gibt es durch die Wiederverwendung konsistent interpretierbare Ergebnisse und weniger technische Schulden.
Kubeflow und BIg Data Handling
Lesen Sie auch unseren Blogpost zu Kubeflow Big Data Handling, in dem wir verschiedene Lösungsansätze (und ihre Schwierigkeiten) für die Kombination aus großen Datenmengen und Kubeflow Pipelines erläutern.
Vertiefen Sie Ihr Wissen mit unserem Kubeflow-Seminar
Konnten wir Ihr Interesse wecken? Buchen Sie hier einen Termin für unser Cloud Native KI-Seminar, um mehr über MLOps mit der Kubeflow Plattform zu erfahren.
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



