
 Metadaten von Daten und ML-Modellen sind entscheidend für die Reproduzierbarkeit beim maschinellen Lernen und Reproduzierbarkeit ist entscheidend für zuverlässige Produktionseinsätze.
Metadaten von Daten und ML-Modellen sind entscheidend für die Reproduzierbarkeit beim maschinellen Lernen und Reproduzierbarkeit ist entscheidend für zuverlässige Produktionseinsätze.
Um ein Modell zu verstehen, es zu analysieren, Probleme zu beheben und es zu verbessern, müssen Datenwissenschaftler:innnen die Input-Daten und ihre Verarbeitung verstehen. Die Kubeflow Plattform unterstützt uns dabei: Das automatische Tracken und Archivieren aller im Lebenszyklus eines Modells produzierten und erhobenen Daten ist ein Hauptmerkmal der Kubeflow Pipelines. Sobald die Plattform allerdings für reale Anwendungsfälle mit großen Datenmengen genutzt wird, können einige Features für die Reproduzierbarkeit des Modell-Lebenszyklus dem Nutzer zum Nachteil gereichen. In diesem Blogpost gehen wir auf die Gründe dafür ein und führen verschiedene Varianten (und ihre jeweiligen Schwierigkeiten) auf, die Big Data und Kubeflow Pipelines effizient kombinieren können.
Probleme im Zusammenhang mit großen Datenmengen in KFP
Eine Kubeflow Pipeline besteht aus mehreren orchestrierten Komponenten (sog. Operations), welche Ergebnisse (Outputs) produzieren können, die von nachfolgenden Komponenten konsumiert und weiterverarbeitet werden können. In Abbildung 1 ist eine Beispielpipeline schematisch aufgeführt.
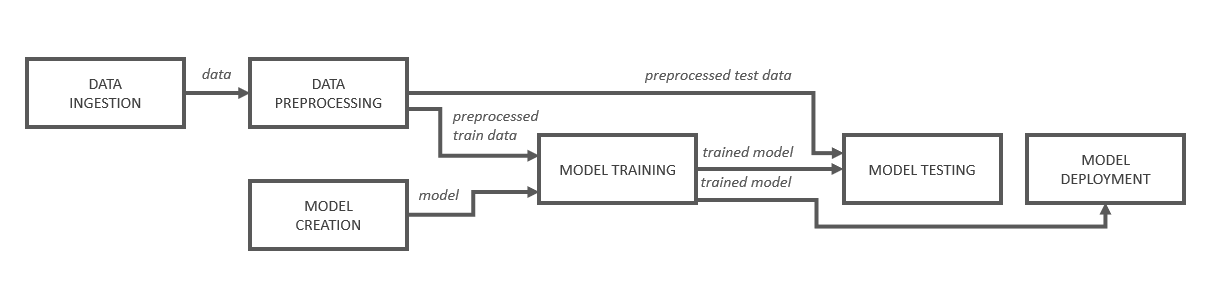
Abbildung 1: Schematischer Aufbau einer ML Pipeline
Dort empfängt die „Model Training“-Komponente vom „Model Creation“-Schritt die Referenz zu einem Modell, welches dann geladen und mit den in einem anderen Schritt vorverarbeiteten Trainingsdaten trainiert wird. Ein wichtiges Detail hierbei ist, dass Kubeflow jeden dieser Pipeline-Schritte in einer isolierten Umgebung bzw. in einem Pod ausführt. Somit teilen sich die Schritte kein gemeinsames Dateisystem, über welches Dateien geteilt werden könnten. Zudem gehen alle verarbeiteten Daten nach Terminieren des Pods verloren.
Um trotz dieser Limitierung eine Weiterverarbeitung der produzierten Daten zu ermöglichen, stellt Kubeflow einen Mechanismus bereit, der den Datentransfer zwischen den Komponenten organisiert. Entwickler:innen können diesen mit der Nutzung des TypeHints "OutputPath" anfragen. Daraufhin wird ein Dateipfad bereitgestellt, in den Dateien abgelegt werden können. Kubeflow kopiert den gespeicherten Inhalt anschließend wahlweise zum Artifact Storage ("Pipeline Root", MinIO, S3 oder GCS ) oder auf ein Persistent Volume Claim (PVC). Nachfolgende Schritte können diese Dateien mit dem Pendant "InputPath" anfragen und nutzen. Der Codeabschnitt 1 veranschaulicht die Verwendung der Kubeflow Pfade.
Codeabschnitt 1: Kubeflow Pipeline mit Verwendung von OutputPath und InputPath
Jeder Lauf einer ML-Pipeline generiert Metadaten mit Informationen über die verschiedenen Pipeline-Komponenten, ihre Ausführungen (z. B. Trainingsläufe) und die daraus resultierenden Artefakte (z. B. trainierte Modelle). Dass der Output jeder Pipeline Komponente zum Weiterreichen zwischengespeichert wird, ist zwar sehr gut für die Nachvollziehbarkeit der Ergebnisse einzelner Modelle und Experimente, bei großen Datenmengen führt dies allerdings zu Problemen.
Werden z.B. Datensätze mit Tausenden von hochauflösenden Bildern in jedem Pipeline-Durchlauf geladen (und gespeichert) und vorverarbeitet (und gespeichert), so wird das Speicherlimit des Artifact Storages schnell erreicht. Um die Menge gespeicherter Daten zu reduzieren und das Serialisieren und Deserialisieren zu beschleunigen, ist eine Reduktion der Anzahl der Komponenten allerdings auch keine Lösung: Modularität sollte angestrebt werden und die Aufgaben der einzelnen Pipeline Schritte gemäß dem Design Pattern "Separation of Concerns" logisch voneinander getrennt bleiben. Wie man das erfolgreich bewerkstelligt und Hindernisse bei Nutzung gemeinsamer Funktionalitäten überwindet, haben wir im Blogartikel Kubeflow Pipelines mit Teamwork und Wiederverwendung - DevOps für Data Scientists zusammengefasst.
Wie kann man nun aber das Weiterreichen und Archivieren großer Datenmengen in ML-Pipelines ermöglichen und effizient machen?
1. Verwendung von (temporären) Volumes zur Entlastung des Artifact Storages
Kubeflow erlaubt die Verwendung von Persistent Volumes (PV) in den Pipelines. Ein Kubernetes-Volume abstrahiert die Speicherebene und ist im Prinzip ein Verzeichnis, auf dessen Dateien Pods zugreifen können, wenn sie dieses unter einem angegebenen Pfad mounten. Wenn die einzelnen Komponenten das Volume jeweils mounten, können sie mit beliebigen Bibliotheken Daten oder Dateien darauf speichern und sie laden. Es können entweder existierende Persistent Volumes verwendet werden oder welche, die innerhalb der Pipeline mit einer VolumeOp erstellt und dann automatisch von Kubeflow verwaltetet werden. Zwar können in der Pipeline generierte Persistent Volumes nach dem Durchlauf der Pipeline wieder gelöscht werden, allerdings bietet es sich hinsichtlich des Cachings an, sie zu behalten (mehr dazu später).
2. Weiterreichen von Referenzen statt sehr großer Datenmengen
In einem Projekt mit vielen GB an Bildern war es uns aufgrund der Speicherlimits des Artifact Storages nicht möglich, die verarbeiteten Daten nach jedem Schritt in einen OutputPath zu serialisieren und sie in Form eines InputPaths in die nächste Komponente zu reichen. Die Funktionalitäten auf Kosten der Modularität zusammenzulegen und somit ein Zwischenspeichern zu vermeiden, kam für uns nicht infrage. Stattdessen haben wir die Speicherpfade der Daten als Argumente übergeben, die auf ein für alle Komponenten zugängliches Volume verweisen. Die Referenzen können dabei als String übergeben werden (z. B. ein Ordnername); bei einer Vielzahl einzelner Dateipfaden bietet sich allerdings weiterhin eine Speicherung der Strings in einem OutputPath an.
Für Option 1 müssen die Operationen der Pipeline jeweils das Volume mounten, um auf die Daten zugreifen zu können. Mit einer für die Weitergabe von Referenzen angepassten Methodendefinition (d.h. String Argumente statt OutputPath() und InputPath()) sähe die Pipeline Implementierung folgendermaßen aus:
Codeabschnitt 2: Verwendung von Volumes für die Übergabe von Referenzen auf Daten
Auf diese Weise wird ein Austausch von sehr großen Daten zwischen den einzelnen Schritten mit minimalem Overhead (kein Upload/Download von Daten zu/von externen Objektspeichern) und auf anbieterneutrale Weise ermöglicht. Die Komponenten können direkt auf den Objektspeicher mit einer beliebigen Lade-Bibliothek zugreifen und ihre Ausführung wird schneller. Es werden keine TB an Daten zwischengespeichert und das Problem des volllaufenden Storages ist bei der Verwendung von Volumes gelöst - allerdings gehen dadurch auch die Vorteile der Archivierung verloren: Mit den dort gespeicherten Metadaten kann nur noch nachvollzogen werden, welche Daten verarbeitet wurden, jedoch nicht, was ihr Eingangs- und Ausgangszustand an jeder Komponente war.
Eine Möglichkeit, dennoch Persistenz der Workflow-Historie und die Reproduzierbarkeit der Schritte zu gewährleisten, ist die Erstellung von Volume-Snapshots. Diese Point-in-time Kopie eines Volumes kann entweder verwendet werden, um ein neues Volume zu rehydrieren (mit den Snapshot-Daten vorbesetzt) oder um einen früheren Zustand des im Snapshot repräsentierten Volumes wiederherzustellen. Die Erstellung ist auch bei mehreren GB recht effizient und aus einer Kubeflow Pipeline heraus anstoßbar. Bevor die Daten an den nächsten Task weitergereicht werden, kann so ein Snapshot erstellt werden, der auch von Pods gemountet werden kann.
Achtung beim Schreiben von Pipelines: Die Nutzung eines Volumes zur Datenweitergabe gibt der Pipeline Steuerung keinen Aufschluss darüber, in welcher Reihenfolge die Tasks ausgeführt werden! Der Directed Acyclic Graph (DAG) wird von Kubeflow normalerweise durch den Datenfluss mit Output- und InputPaths abgeleitet. Daher ist es notwendig, die Tasks explizit mit der Methode <task2>.after(<task1>) zu konkatenieren, sodass jede Methode zum richtigen Zeitpunkt auf die abgelegten Daten zugreift.
3. Nutzung des Kubeflow Cachings
Der Caching-Mechanismus von Kubeflow operiert auf Komponenten-Ebene und ist standardmäßig aktiviert. Sobald ein Task, d.h. eine instanziierte Operation, ausgeführt wird, überprüft Kubeflow, ob bereits eine Ausführung des gleichen Task-Interfaces existiert. Dafür werden die Task-Spezifikation (das Docker Base Image, der ausgeführte Befehl und die Argumente), und die Task-Eingaben (Eingabewert oder -artefakt) berücksichtigt. So ermöglicht die Archivierung im Artifact Store bei einer Übereinstimmung, dass der Task nicht ausgeführt, sondern die Ausgabe der identischen Komponente wiederverwendet wird.
Bei zeit- oder rechenintensiven Aufgaben, wie z.B. beim Download großer Datenmengen oder beim Training mit denselben Daten, erweist sich die Verwendung des Cache als sehr nützlich. Für bestimmte Aufgaben ist er jedoch unerwünscht und kann gezielt für ganze Pipelines oder einzelne Schritte deaktiviert werden, indem die Expiration Time des Caches auf „0 days“ gesetzt wird. Deaktiviert man das Caching für einen Task, werden nachfolgende Tasks auch nicht mehr gecacht - es sei denn, das Interface (Eingaben, Ausgaben, Spezifikation) ist gleich. Dabei ist Vorsicht geboten, wie die nächsten Abschnitte zeigen.
Fehlerquellen bei der Nutzung des Cachings
Caching trotz Deaktivierung
In Abbildung 2 ist die vorhin erwähnte, bildverarbeitende Pipeline zu sehen. Hier wurde der Cache für den "Process data"-Schritt explizit deaktiviert, dennoch wird der nachfolgende Schritt gecacht. Warum?
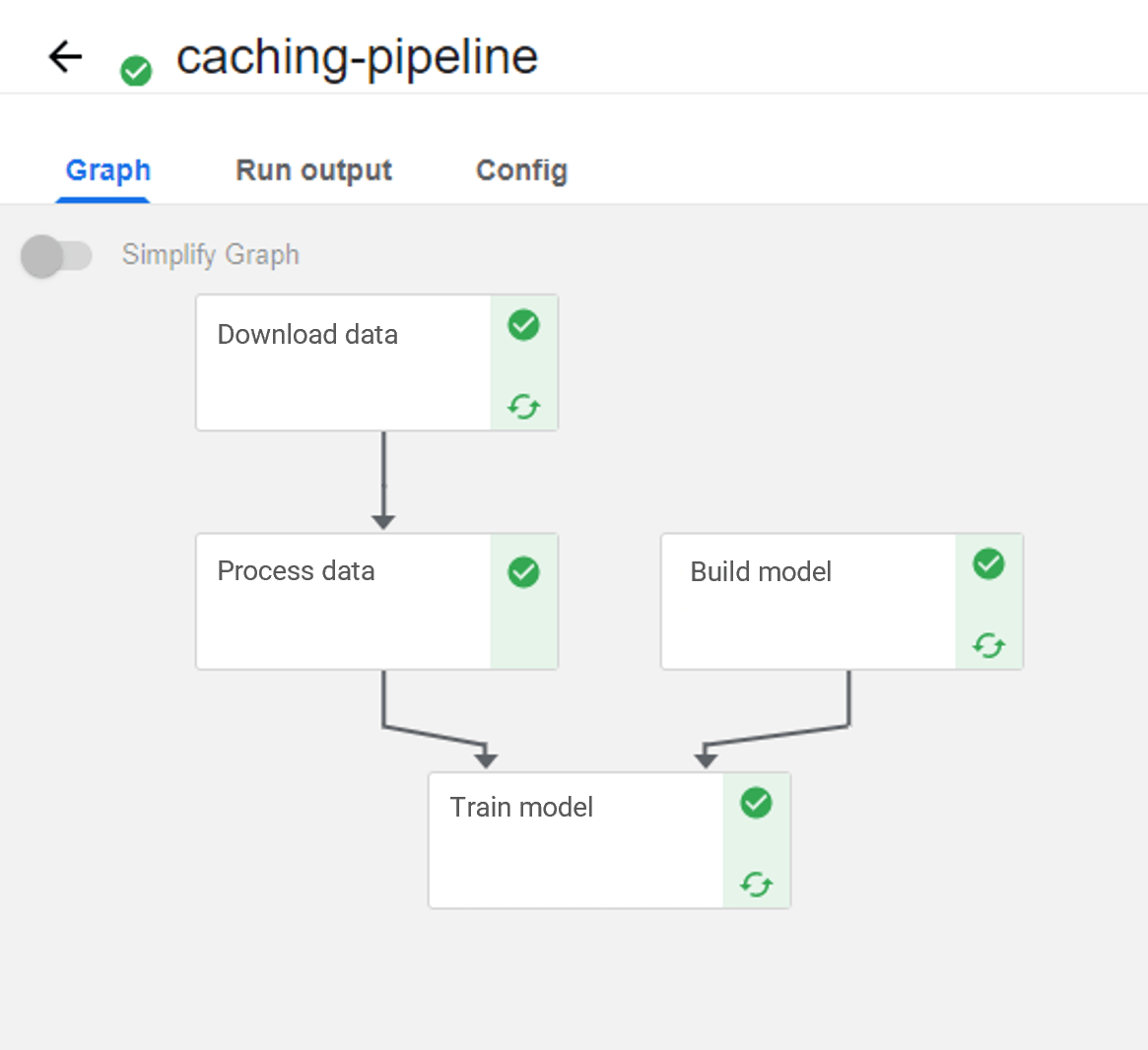
Abbildung 2: ML Pipeline mit deaktiviertem Cache für "Process data"
Anstatt die Bilder in den OutputPath zu schreiben, wurde der Komponente nur eine Liste ihrer Dateipfade übergeben (siehe Option 2), da sie auf einem gemounteten Volume liegen, um Speicherplatz im Artefakt-Repository zu sparen. Das Problem hierbei ist, dass sich dadurch die Eingaben (die Bild-Pfade) nicht ändern und das Caching greift, selbst wenn sich die Bilder hinter den Pfaden geändert haben.
In dieser Hinsicht unterscheidet sich das Kubeflow Pipelines SKD v1 übrigens von der zweiten Version (bzw. dem v2 kompatiblen Modus): Dort wird nicht nur das Input-Artefakt, sondern auch sein Name und seine ID betrachtet. Ein nicht gecachter Task produziert in jedem Fall ein Artefakt mit neuer ID, weshalb die Nachfolgenden ebenfalls neu ausgeführt werden. In Kubeflow Pipelines SDK v2 DSL kann aktuell zudem noch keine Cache Expiration Time auf Task-Ebene festgelegt werden. Das Caching kann nur für ganze Pipelines gezielt deaktiviert werden, indem man der run_pipeline (bzw. create_run_from_pipeline_func) Funktion das Argument "enable_caching=False" übergibt.
Tipp: Wenn man das Problem aus Abbildung 2 umgehen möchte, kann der nachfolgenden Methode ein zusätzlicher Parameter (z. B. einen Hash) übergeben werden, der sich von den Eingaben der gecachten Komponentenausführungen unterscheidet. Dies triggert eine Neudurchführung.
Caching von Dateien an anderen Speicherorten
Die Verwendung von String-Referenzen statt den Kubeflow Paths bietet in Kombination mit dem Caching auch eine mögliche Fehlerquelle.
Nehmen wir an, in einem Schritt werden Dateien auf ein Volume geschrieben. Wenn bei einer erneuten Pipeline Ausführung ein anderes Persistent Volume unter demselben Pfad gemountet wird, werden die Ergebnisse des vorherigen Volumes gefunden und "wiederverwendet". Sie werden daher nicht auf das eigentlich angebundene Volume geschrieben. Wenn der nachfolgende Schritt, der keinen Cache verwenden soll, diese dann einsammeln will, kann es zu Inkonsistenzen zwischen den Daten und dem eigentlichen Output des vorherigen Schritts kommen, da die Ergebnisse der Schritte davor nicht zwangsläufig am selben Speicherort liegen.
Tipp: Ein einfacher Workaround hierfür ist, den Namen des verwendeten Volumes (bzw. des PVCs) in den Volume Mount Path aufzunehmen. In Codeabschitt 2 wäre z.B. "my_mounted_volume" mit "my_volume" zu ersetzen. Wenn ein anderes Volume verwendet wird, ändert sich die Eingabe der Komponente und das Problem besteht nicht. Jedoch muss nach wie vor sichergestellt werden, dass die Daten auf dem Volume nicht manipuliert/gelöscht werden.
4. Änderung der Data Passing Method
Durch Änderung der Datenübertragungsmethode in der Pipeline-Konfiguration können wir ein Volume verwenden, ohne es in jede Komponente einbinden zu müssen. Alle Artefakte werden dadurch über das ausgewählte Volume übertragen, das vor Start der Pipeline allerdings bereits existieren muss. Diese Übertragungsart hat die Vorteile, dass wie gewohnt Output- und InputPaths verwendet werden können und ein Volume-Mount an jede einzelne Komponente obsolet wird.
Codeabschnitt 3: ML Pipeline mit einer Volume-basierten Data Passing Method
Allerdings gehen beim Löschen des Volumes alle Artifakte verloren, weshalb ggf. auch auf eine Sicherung des Standes mittels eines VolumeSnapshots geachtet werden muss.
Achtung: Aktuell funktioniert das Caching mit der geänderten Data Passing Method noch nicht. Die Schritte werden jedes Mal erneut ausgeführt (siehe hierzu folgendes GitHub Issue).
Schlussfolgerungen und Empfehlungen
Welche Methode des Datenweiterreichens sich am besten für eine Pipeline eignet, ist - wie so oft - Use Case abhängig. Man kann/sollte sich die folgenden Fragen stellen:
Wie viele Daten werden zwischen wie vielen Schritten ausgetauscht?
Da der Speicherplatz der Pipeline Root von allen Komponenten aller Pipelines verwendet wird, ist ein Hineinspeichern sehr großer Datenmengen in die OutputPaths eher nicht zu empfehlen. Stattdessen kann man Referenzen auf die Datensätze (z.B. Bildpfade) über Strings oder über OutputPaths weiterreichen. OutputPaths geben im Vergleich zu Strings immerhin Aufschluss darüber, welche Daten von den Schritten betrachtet wurden (wenn auch nicht über ihren Zustand). Wenn eine ausführliche Versionierung der Zwischenergebnisse wichtig ist, dann kann man die Data Passing Method auf die Verwendung von Volumes umkonfigurieren. Aber auch hier muss darauf geachtet werden, dass das verwendete Volume nicht gelöscht wird.
Bei der Verwendung des Caching-Mechanismus sollte darauf geachtet werden:
- Wurden die Output-Artefakte auf dem Volume modifiziert?
- Verwende ich innerhalb einer Pipeline stets die Ergebnisse desselben Volumes?
- Möchte ich das Caching gezielt deaktivieren, da sich einige Verarbeitungsschritte geändert haben?
Unabhängig von der Größe der abzuspeichernden Daten muss man sich die Frage stellen, wie kritisch die Nachvollziehbarkeit der Pipeline ist:
Sollen alle Schritte und ihre Ein- und Ausgaben archiviert und versioniert werden?
In diesem Zuge wird die Reproduzierbarkeit relevant: Durch eine End-to-End Verfolgung und Versionierung der Zwischen- und Endartefakte eines ML-Workflow wird den ML-Modellbauer:innen Zugang zu vollständig reproduzierbaren Ergebnissen ermöglicht, was ihre Modelliteration und -neuerstellung beschleunigt. In ML-Projekten ist nämlich nicht nur die Versionierung des Codes wichtig, der von eine:r Softwareentwickler:in stets vorbildlich versioniert wird, sondern auch die der Daten und Modelle.
Zum Stichwort Reproduzierbarkeit und schlussendlich der Nachvollziehbarkeit bezüglich des Data Preprocessings: Hilfreiche Tipps können unseren bpmn.ai-Mustern entnommen werden, u.a. dem Process Pattern "Increasing Levels of Deconstruction".
Wenn das Tracking der Experimente wichtig ist und die Zwischenergebnisse der Pipelines erhalten und einsehbar bleiben sollen, dann ist die Verwendung des "normalen" InputPaths und OutputPaths und der dadurch stattfindenden Speicherung im Artifact Storage zu empfehlen, da Volumes an Kubeflow Profiles gebunden sind und theoretisch von jedem Mitglied des jeweiligen Kubernetes Namespaces gelöscht werden können. Zwar lassen sich Artifakte theoretisch auch aus dem Artifact Storage löschen, allerdings fehlen Nutzern hierzu in der Praxis die Berechtigungen und Kubeflow-spezifisches Wissen.
Upcoming: Wir möchten eine Lösung zu Kubeflow beitragen, die das Löschen von Artefakten und deren Caches ermöglicht. Sollte eine solche Lösung Einzug in das Kubeflow Ökosystem finden, würden Nutzer:innen ihre Artefakte im Artifact Store selbstständig verwalten und somit Platzmangel verhindern können (siehe hier).
Zusammenfassend stellen große Datenmengen MLOps Plattformen wie Kubeflow zwar vor Herausforderungen, aber wie in diesem Artikel ersichtlich sind diese handhabbar. Sicher ist, dass wenn eine Verarbeitung dieser notwendig ist, Kubeflow mit den ihm zugrundeliegenden, quasi "unerschöpfbaren" Cloud Ressourcen eine gute Wahl darstellt.
Wenn wir Interesse an Kubeflow als MLOps Plattform wecken konnten, buchen sie hier einen Termin für unser Cloud Native KI-Seminar, um mehr über MLOps mit der Kubeflow Plattform zu erfahren.
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



