

Eine Zusammenfassung der Ergebnisse aus der Master Thesis von Hendrik Winkelmann, in Zusammenarbeit mit Prof. Dr. Herbert Kuchen an der WWU Münster: Machine Learning, insbesondere das Teilgebiet Supervised Learning, ist derzeit ein Hype-Thema, von dem Unternehmen enorme Auswirkungen auf ihre zukünftige strategische Entwicklung erwarten. Genauer betrachtet beschreibt Supervised Learning die Entwicklung eines Modells. Hierfür werden bekannte historische Daten generalisiert und dabei oft frühere Entscheidungen als richtig vorausgesetzt. Das kann gefährlich sein.
Problematisch an derartiger Automatisierung kognitiver Prozesse ist, dass domänenspezifische Ansprüche erfüllt sein müssen:
- Ein Patient möchte sichergehen, dass seine Diagnose auf Grundlage von medizinischem Fachwissen mit Berücksichtigung aller Eigenheiten erstellt wurde.
- Ein Antragsteller, dem ein Kredit verweigert wurde, möchte die Gründe hierfür erfahren.
- Bei einem Verwaltungsakt muss sichergestellt werden, dass beispielsweise Rassismus keine Rolle bei der Erstellung der Entscheidung(-sempfehlung) gespielt hat.
- DSGVO-Normen müssen eingehalten werden.
Kurz gesagt: Es sollte gewährleistet werden, dass die Modelle ein semantisch sinnvolles Entscheidungsverhalten an den Tag legen und Rechtfertigungen für das Verhalten gegeben werden können. Im aktuell verbreiteten Black-Box-ML-Vorgehen ist das nicht der Fall.
Hierfür gibt es prominente Beispiele: In dem bekannten COMPAS-Algorithmus, der in der US-amerikanischen Judikative eingesetzt wird, wurde ein Bias gegen Afro-Amerikaner festgestellt, der auf Grundlage der vorliegenden Daten erlernt wurde1. Das zu erkennen ist oft wertvoll, es nicht zu hinterfragen gefährlich. Ggf. ist die Erkenntnis sogar wertvoller als die Möglichkeit einer Automatisierung.
Erschwerend kommt hinzu, dass präzise Supervised-Learning-Modelle wie Ensemble-Methoden und neuronale Netze im Gegensatz zur traditionellen linearen Regression oftmals unübersichtlich sind. Das bedeutet, dass Gründe für ihre Vorhersagen nicht anhand des Modells selbst abgelesen werden können. Es ist sogar so, dass für komplexe Datensätze ein inhärenter Trade-off zwischen der Interpretierbarkeit und der Präzision in Supervised-Learning-Modellen zu beobachten ist.
Explainable Artificial Intelligence (XAI) ist eine relativ neue Bewegung, die sich dediziert damit beschäftigt, die semantische Validierung von Supervised-Learning-Modellen zu ermöglichen. Grundsätzlich gilt es hierbei, vier verschiedene Ziele von XAI zu differenzieren:
- Erklären, um zu rechtfertigen: Für ein gegebenes Black-Box-Modell und eine individuelle Entscheidung/Vorhersage sollten die Gründe erkennbar sein.
- Erklären, um zu kontrollieren: Es dürfen nicht nur Einzelfälle analysiert werden. Stattdessen sollte für den gesamten Raum klar werden, welche Entscheidungen weshalb gefällt werden. Unter diesem Ziel können somit Audit-Verfahren für Supervised-Learning-Modelle subsumiert werden.
- Erklären, um zu verbessern: Aufbauend auf dem Ziel der Kontrolle von Supervised-Learning-Modellen, sollten Erkenntnisse und Erklärungen außerdem genutzt werden können, um das Modell systematisch zu verbessern.
- Erklären, um zu entdecken: Wer in die Black-Box hineinschauen kann, wird ggf. selbst direkt davon profitieren. Das gelingt oft schon durch das Aufzeigen von Datenqualitätsproblemen.
Die viadee hat sich bereits ausführlich im Zusammenhang mit dem Anchors-Algorithmus mit der Thematik “Erklären, um zu rechtfertigen” auseinandergesetzt2. Im Rahmen einer darauf aufbauenden Master-Arbeit wurden nun außerdem verstärkt die Ziele zwei bis vier evaluiert, durch welche ein Modell in seiner Gesamtheit verstanden werden soll.
Die Lösung – Zusammenfassung
Die Frage, wie eine gute Erklärung für ein Supervised-Learning-Modell aussieht, ist oft umstritten. Das Modellverhalten soll nachvollziehbar sein, also sollten am besten wenige, einfache Erklärungen gegeben werden. Hierbei gilt es jedoch auch, den notwendigen Detailgrad zu wahren. Adobe veröffentlichte ein vielversprechendes Paper3, in dem die Model Agnostic Globally Interpretable Explanations (MAGIX)- Methode vorgestellt wurde.
In diesem Verfahren wird eine Menge von Regeln der Form „IF <Bedingungen> THEN <Entscheidung>“ akkumuliert, die das Modellverhalten unter dem vorher beschriebenen Trade-off approximieren können soll. Diese Darstellung ist interessant, da sie intuitiv verständlich ist und direkt in automatisierte Entscheidungen übersetzt werden kann. So können sie z.B. im Rahmen der Geschäftsprozessautomatisierung in auf DMN-Tabellen basierenden Regel-Engines genutzt werden, um Prozesse und Entscheidungen nachvollziehbar zu approximieren.
Eine OpenSource-Implementierung dieses Verfahrens wurde allerdings nicht veröffentlicht. Dies haben wir zum Anlass genommen, das bestehende MAGIX-Verfahren zu analysieren, zu erweitern, und effizient zu implementieren. Die Implementierung dieses Softwarepakets, „Model Agnostic Globally Interpretable Explanations“ (MAGIE), steht in einem Repository der viadee mit einer liberalen Lizenz (BSD-3) bereit4.
Erstellung von Globalen Erklärungen
Im Rahmen dieser Masterarbeit wurden einige bekannte Erklärungsverfahren analysiert und das bestehende MAGIX-Verfahren/Framework erweitert. Das neu entstandene Framework kann genutzt werden, um beliebige Supervised Learning-Modelle anhand eines Sets von Regeln der Form „IF <Bedingungen> THEN <Entscheidung>“ global zu erklären. Diese einzelnen Regeln ahmen das Entscheidungsverhalten eines beliebigen Black-Box-Modells (zum Beispiel eines neuronalen Netzes, einer Support Vector Machine, eines Random Forest etc.) nach. Anders als bei lokalen Erklärern (wie bspw. Anchors) wird hierbei nicht je eine Regel für einen individuellen Datenpunkt ausgegeben. Das Verhalten des Black-Box-Modells wird mittels möglichst weniger Regeln für einen gegebenen Referenzdatensatz akkurat nachgebildet.
Die bestehenden analysierten Verfahren, die in diesem Sinne Regelsätze erstellen, sind vergleichbar mit dem Konzept Rule Mining. Es wird versucht, interessante Regeln zu finden, die das Modellverhalten gut nachahmen und etwaige Besonderheiten aufdecken.
Problematisch bei bekannten Rule-Mining-Verfahren wie Apriori5 ist, dass die „Interessantheit“ von Regeln schwerlich a priori feststellbar ist. Mittels des in der Masterarbeit erstellten Frameworks wird es dem Nutzer ermöglicht, auch neue Verfahren zur Regelerstellung schnell zu integrieren. Somit können verschiedene Regelsätze erstellt werden, um ein Modell sowie mögliche Besonderheiten zu erkunden. Eine weitere Motivation für eine solche Flexibilität liegt in der kontextabhängigen Qualität von Erklärungen.
Das für Optimierung und Supervised Learning bekannte No-Free-Lunch-Theorem6 gilt in seinem Kerngedanken auch für das Erklären von einem Black-Box-Modell: Es gibt kein generell optimales Erklärungsverfahren. So ist die Güte einer Erklärung abhängig von externen Faktoren wie Zeitrestriktionen für das Erstellen oder auch Verstehen einer Erklärung und auch dem Anwendungsszenario, also zum Beispiel, ob das Modell in seinem Verhalten kontrolliert werden soll oder als Ausgangspunkt für die Erstellung weiterer Hypothesen dient. An dieser Stelle sei erwähnt, dass nicht nur Erklärungen zu Black-Box-Modellen generiert werden können. Vielmehr ist das Framework auch leicht nutzbar, um direkt effizientes Rule Mining zu betreiben.
Die Algorithmischen Komponenten
Das Framework unterscheidet fünf verschiedene Ansätze zur Generierung eines finalen Regelsets. Als erstes können Regeln durch lokales Erklären individueller Datenpunkte (bspw. mittels Anchors) erstellt werden (Explanation Mapping). Weiterhin können bestehende Regeln mittels eines Optimierungsverfahrens verbessert werden (Rule Optimization). Zudem können aus der akkumulierten Menge von Regeln irrelevante Regeln herausgefiltert werden (Postprocessing). Die relevanten Regeln können außerdem auch in ihrer Komposition optimiert, statt gefiltert werden (Rule-Set-Optimization). Zuletzt können Regeln noch gruppiert werden (Explanation Structuring)7, um dem Nutzer eine übersichtlichere Ergebnismenge zu liefern. Das Ergebnis eines Schrittes wird in den jeweils nächsten Schritt weitergeleitet. Hierbei wird für jeden Wert des vorherzusagenden Features (dem Label) jeder Schritt einzeln ausgeführt.
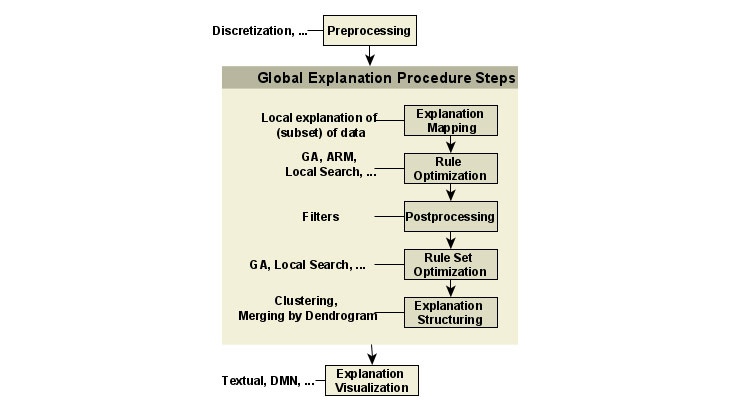
Die in der Grafik dargestellte Reihenfolge dieser Komponenten ist exemplarisch: Zwar müssen der erste und letzte Schritt ein Explanation-Mapping- bzw. ein Explanation-Structuring-Schritt sein, jedoch ist die Abfolge von Rule-Optimization-, Postprocessing- und Rule-Set-Optimization-Schritten beliebig und optional. So können Pipelines die drei genannten Schritte entweder (mehrfach) verwenden, auslassen oder in beliebiger Reihenfolge hintereinanderschalten.
Eine exemplarisch verwendete Pipeline verwendet - in Anlehnung an das originale MAGIX-Verfahren - einen lokalen Erklärer und lässt die generierten Erklärungen mittels eines genetischen Algorithmus verfeinern und diversifizieren. Weiterhin werden die Regeln mit einer k-optimalen lokalen Suche verbessert und anschließend auf diverse Arten gefiltert. Im Folgenden werden die zuvor angesprochenen Schritte detailliert erklärt:
- Preprocessing: Die analysierten Verfahren zur regelbasierten Erklärung von Black-Box-Modellen arbeiten sowohl im In- als auch im Output auf diskreten Daten. Das bedeutet, dass die verwendeten Daten entweder bereits vor dem Laden diskretisiert sein müssen oder noch diskretisiert werden müssen. Vorimplementiert ist ein einfacher Quantil-Diskretisierer: Während das Black-Box-Modell noch mit kontinuierlichen Daten rechnen kann, wird spätestens zu der Generierung von Erklärungen jedes kontinuierliche Feature in einen kategoriellen Wert überführt.
- Explanation Mapping: Nach dem Preprocessing erklärt die ReorderedKOptMAGIX-Pipeline eine Teilmenge von individuellen lokalen Datenpunkten. Hierbei können der Aufwand und die Redundanz beim Erklären von „großen“ Datensets erheblich reduziert werden, indem lediglich neue Datenpunkte erklärt werden, wenn diese noch nicht von einer bereits erstellten Regel überdeckt werden. In der Vergangenheit wurde hierfür die Erklärung verteilt8. Das MAGIE Framework hingegen setzt auf einen neuen Akkumulationsmechanismus sowie eine effiziente Datenstruktur: Roaring Bitmaps9.
- Rule Optimization: Ein Nachteil am Explanation-Mapping-Schritt ist, dass das Format der Regeln durch den genutzten Erklärer, beispielsweise Anchors, beschränkt ist: So werden Regeln der Form „IF Sex=‘Male‘ AND 3,000<=Income<4,000“ erstellbar. Jedoch ist es nicht möglich, eine Regel „IF Sex=‘Male‘ OR Sex=‘Female‘ AND 3,000<=Income<4,000“ zu formulieren. Hierfür müssten zwei Regeln erstellt werden. In komplexeren Fällen wird es hierbei schwieriger, das Verhalten des Modells nachzuvollziehen, da eine große Menge an Regeln generiert werden muss. Um dieses Problem zu umgehen, können die lokal generierten Regeln mithilfe einer flexibleren Repräsentation rekombiniert werden.
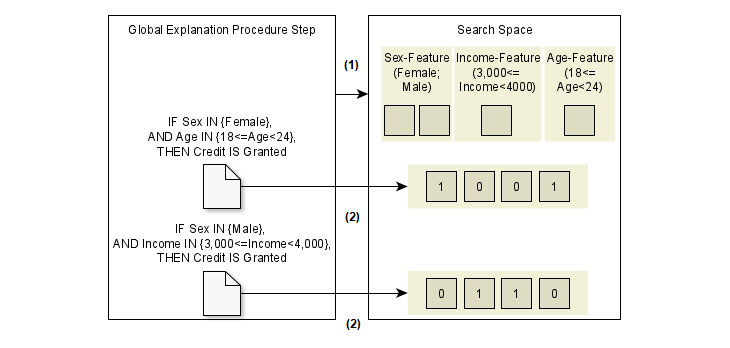
In dem dargestellten Beispiel besteht die Regelmenge aus zwei Regeln. Jede Bedingung wird durch ein Bit kodiert. Ist ein Bit aktiviert, so ist die Bedingung in einer Regel aktiviert. So kann das in dem Optimierungsverfahren genutzte Suchverfahren den gesamten Suchraum erkunden. Beispielsweise kann folgende neue Regel gebildet werden.
- Postprocessing: Während die Schritte Explanation Mapping und Rule Optimization die Struktur von einzelnen Regeln betreffen, wird Postprocessing auf die Ergebnismenge an Regeln angewandt. Es können verschiedene Filter angewandt werden, die die Regeln und potenzielle Regelsets miteinander vergleichen. Beispielsweise kann eine Mindestpräzision definiert werden, die die Regeln der Ergebnismenge haben sollen. Der BaselineRuleExplanationFilter, den die ReorderedKOptMAGIX-Pipeline nutzt, evaluiert die relative Häufigkeit der Label-Werte. Lediglich Regeln, deren Präzision für den gegebenen Label-Wert höher als diese relative Häufigkeit ist, werden in die Ergebnismenge übernommen.
- Rule Set Optimization: Eine naheliegende Idee ist es, nicht nur die Bedingungen in einer Regel mittels eines genetischen Suchverfahrens zu optimieren, sondern auch die Komposition des Regelsets. Während diese Idee naheliegend ist, ist es schwierig, eine entsprechende Fitnessfunktion zu erstellen. Eine Zielfunktion, wie sie beispielsweise in BETA5 definiert ist, stellt einen systematischeren, jedoch komplexeren Ansatz für die Optimierung von der Ergebnismenge dar als das heuristische Filtern des Postprocessing-Schritts.
- Explanation Structuring: Als Vorbereitung für die Präsentation der resultierenden Regelmenge sollte es möglich sein, die Regeln zu strukturieren. Diese Idee ist abgeleitet aus einem Verfahren, welches mangels eines dedizierten Namens im Folgenden „Bottom-Up-Dendrogram“ genannt wird11. Das prototypische Verfahren erstellt zuerst lokale Erklärungen mittels des bekannten LIME-Verfahrens12 und verschmilzt sequenziell ähnliche Regeln mittels eines hierarchischen Clusterverfahrens. Die Ähnlichkeitsfunktion zwischen zwei Regeln kann hierbei durch die Anzahl an Datenpunkten, die durch beide Regeln überdeckt werden, gegeben sein.
- Explanation Visualization: Der letzte Schritt ist die Darstellung des Ergebnisses. Es gibt hier diverse Möglichkeiten, wie das Generieren einer DMN-Tabelle oder einer dynamischen Visualisierung. Die einfachste Lösung ist eine textuelle Darstellung, hier am Beispiel des Iris-Datensets:
IF PetalWidth[cm] IN {1.5<=PetalWidth[cm]<2.1, 2.1<=PetalWidth[cm]},
AND PetalLength[cm] IN {4.707<=PetalLength[cm]<5.543, 5.543<=PetalLength[cm]},
THEN Species IS Iris-virginica
Coverage: 0.3167
Recall: 1.0
Accuracy: 0.975
Precision: 0.9211
F1-Score: 0.9589
MCC: 0.9426
Normalized RMI: 0.8551
Anhand dieser Erklärung ist ersichtlich, dass alle Datenpunkte mit der Spezies „Iris-virginica“ mit hoher Präzision durch die Regel erklärbar sind (Accuracy) und, dass mit dieser Regel schon ein großer Teil des Daten-Raums beschrieben ist (32.7 % Coverage).
Fazit
Mittels des MAGIE-Frameworks wurde eine effiziente Implementierung von bekannten XAI-Verfahren veröffentlicht. Diese Verfahren können durch die Rekombination von algorithmischen Bausteinen leicht ergänzt werden. Der Nutzer hat somit die Möglichkeit, die Ergebnismenge an Regeln mit verschiedenen Verfahren zu validieren und eines auszuwählen, was den Trade-off zwischen der Komplexität und dem Detailgrad der Erklärung maximiert.
Die viadee sucht Test-Nutzer und Kooperationspartner, die an der Erklärung komplexer Supervised-Learning-Modelle interessiert sind. Hierbei freuen wir uns über Fragen und Feedback auf dem zugehörigen Github-Repository.
Quellen:
1. https://www.propublica.org/article/how-we-analyzed-the-compas-recidivism-algorithm
2. https://blog.viadee.de/machine-learning-modelle-erklaerbar-machen-mit-anchors
3. https://arxiv.org/abs/1706.07160 und https://theblog.adobe.com/magix-the-solution-to-the-black-box-issue-of-ai-driven-personalization/
4. https://github.com/viadee/magie/tree/master
5. https://www.kdnuggets.com/2016/04/association-rules-apriori-algorithm-tutorial.html
6. https://www.kdnuggets.com/2019/09/no-free-lunch-data-science.html
7. Dieser Schritt ist noch work-in-progress.
8. https://blog.viadee.de/machine-learning-modelle-erklaerbar-machen-mit-anchors
10. https://www.kdnuggets.com/2019/01/explainable-ai.html
11. https://www.kdnuggets.com/2019/03/ai-black-box-explanation-problem.html
Die Ergebnisse stammen aus der Master Thesis von Hendrik Winkelmann in Zusammenarbeit mit Prof. Kuchen an der WWU Münster.
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



