

Sowohl bei der Entwicklung als auch bei der Verwendung von Machine-Learning-Modellen steht man vor mehreren Herausforderungen: Die Modelle müssen validiert und Vertrauen muss geschaffen werden. Sofern es außerdem um automatisierte Entscheidungen geht, müssen einzelne Vorhersagen bzw. Entscheidungen erklärt werden. Dazu haben Marco Tulio Ribeiro, Sameer Singh und Carlos Guestrin in 2018 den Algorithmus Anchors entworfen.
Kurz zusammengefasst wird bei Anchors versucht, herauszufinden, welche Features eines Datensatzes sich nicht ändern dürfen, damit die Vorhersage gleich bleibt. Die Aussage des Ergebnisses ist: Egal welche Daten der Datensatz erhält, wenn Feature a den Wert x und Feature b den Wert y enthalten, kommt es mit einer gewissen Wahrscheinlichkeit zur gleichen Vorhersage. Die Erklärung einer Einzelentscheidung bildet somit den Gedankengang eines menschlichen Entscheidungsträgers nach.
Im Rahmen einer Master-Thesis wurde dieser Algorithmus für Java implementiert. Gleichzeitig wurden Optimierungen zur Reduzierung der Laufzeit entwickelt. Da, wie eben angedeutet, Anchors lediglich einen einzelnen Datensatz erklärt, wurde auch ein übergeordneter Algorithmus entwickelt (Coverage Pick), um aus verschiedenen Erklärungen wenige, repräsentative Erklärungen auszuwählen und so zu einer globalen Erklärung zu kommen. Darüber hinaus wurde auf Basis der globalen Erklärungen eine Ansicht zur Übersicht und zur Beurteilung entwickelt. Diese beschränkt sich auf tabellarische Daten, da eine datenagnostische Darstellung nicht möglich ist. Mit der Ansicht wird eine schnelle und einfache Übersicht der globalen Erklärung gegeben – so übersichtlich wie die im Modell gelernten fachlichen Zusammenhänge eben sind.
Visualisierung einer globalen Erklärung
Bei der globalen Erklärung erhält man eine Liste von Regeln und Kennzahlen, die das erlernte Wissen im Modell ausdrücken. Um diese beurteilen zu können - zum Beispiel dahingehend, ob sie das Modell hinreichend erklären oder um sich einen einfachen Überblick verschaffen zu können -, wird eine sinnvolle Darstellung benötigt.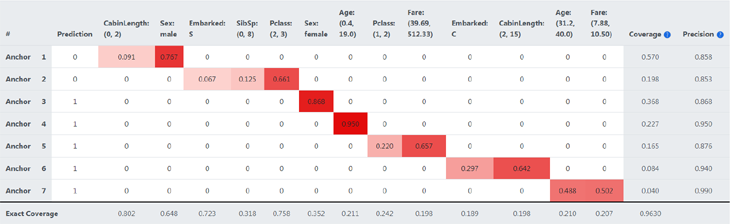 Abbildung 1 zum Vergrößern klicken
Abbildung 1 zum Vergrößern klicken Wie in Abbildung 1 zu sehen ist, werden alle verwendeten Features, inklusive der Teilbereiche bzw. der Kategorien, in Spalten dargestellt. Die Zeilen stellen die Regeln dar. Schon alleine mit diesen Informationen kann schnell und einfach eine Beurteilung der globalen Erklärung stattfinden. Die von Anchors gefundenen Muster werden in einer für den Nutzer angenehmen und schnell erfassbaren Grafik visualisiert: In unserem Beispiel geht es um die Überlebenschancen beim Untergang der Titanic. Männliche Passagiere der Titanic hatten kaum Chancen, Kinder und Menschen mit bestimmten Ticketpreisen für bestimmte Klassen aber sehr wohl.
Darüber hinaus wird in unserem Beispiel sowohl eine Coverage als auch eine Precision pro Regelsatz angegeben. Damit kann jede Regel beurteilt werden: Allein mit dem Wissen über das Schicksal männlicher Gäste sind 57% des Verhaltens des Machine-Learning-Modells erklärt und es hat zu 86% auch recht damit.
Pro Regelsatz wird neben der Gesamt-Precision auch die additive Precision pro hinzugefügtem Prädikat angegeben. Es wird also die Reihenfolge ersichtlich, in der die Prädikate zum Regelsatz angefügt wurden.
Bei der Verwendung von Anchors können einige Parameter angepasst werden. Hier ist zum Beispiel die Größe der Stichprobe zu nennen. Da es bei großen Datenmengen unwirtschaftlich ist, die genaue Coverage und Precision zu berechnen, werden diese anhand einer Stichprobe ermittelt. Weichen die ermittelten Werte stark von der Wirklichkeit ab, kann dies Nachteile bei der Ermittlung der Regelsätze haben. Denn ob ein Feature zum Regelsatz hinzugefügt wird, oder nicht wird anhand von Precision und Coverage bestimmt. Daher wird in der letzten Zeile des Diagramms auch die wahre Coverage pro Feature angegeben. Zuallerletzt ist noch die Zelle der letzten Zeile in Höhe der Spalte Coverage zu nennen. Diese zeigt die Coverage an, welche mit allen Regelsätzen ermittelt wird. Dabei macht es keinen Unterschied, ob ein Datensatz zu einem oder zu mehreren Regelsätzen passt.
Aus der globalen Erklärung (Abbildung 1) wird ersichtlich, dass das Modell Muster erkannt hat, die auch so von Überlebenden erzählt wurden. So ist zu erkennen, dass ein Lebensalter zwischen 0,4 und 19 Jahren ein Indikator für das Überleben war (Prediction = 1). Ähnlich verhält es sich mit weiblichen Personen. Es wird ersichtlich, dass für die Auswahl von Personen, die in ein Rettungsboot steigen durften, vor allem das Geschlecht, Alter und Vermögen ausschlaggebend waren.
Für die Auswahl der Regelsätze wurde der selbstentwickelte Algorithmus Coverage Pick verwendet. Dieser konnte mit nur sieben Regelsätzen eine Abdeckung von 96,3 % erreichen.
Adapter zur Erklärung unterschiedlicher Daten
Anchors Anwendungsfall-Spezifizität wird als größte Gefahr für dessen produktiven Einsatz angesehen. Zwar operiert Anchors modellagnostisch, jedoch muss für jede Anwendung eine Vielzahl von Einstellungen und Parametern konfiguriert werden.Dafür wurden unter anderem die wichtigsten Einsatzgebiete identifiziert und Standardlösungen implementiert. Somit können in vielen Domains, wie z. B. Tabellen-, Bilder- oder Text-Domains, Erklärungen schnell und ohne großen Konfigurationsaufwand angefertigt werden.
Zudem werden DL4J-, Smile- und H2O-Modelle unterstützt sowie die Verteilung mehrerer Erklärungen mit Spark.
Beschreibung des Anchors-Algorithmus
Anchors ist ein neues Verfahren des Explainable Machine Learnings und wurde von Marco Tulio Ribeiro, Sameer Singh und Carlos Guestrin entworfen. Es folgt den Algorithmen LIME und aLIME, welche ebenfalls von diesen Autoren entwickelt wurden. Anchors kann als Erweiterung dieser gesehen werden, da seine Funktionsweise ähnlich ist, jedoch im Detail diverse Verbesserungen aufweist.Anchors ist ein Post-hoc-Erklärer und liefert lokale, modell agnostische Erklärungen, genannt anchors. Diese besitzen ein IF-THEN Format und haben eine klar definierte Coverage, was bedeutet, dass ihre Gültigkeit bzw. Bedeutung im Inputbereich deutlich bekannt ist. Dies macht Erklärungen intuitiv und leicht verständlich.
Ein von Anchors produzierter Anchor ist wie folgt definiert:
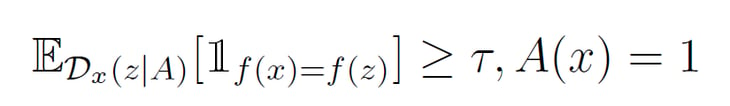
In dieser Definition bezeichnet D den Perturbationsraum, durch den Nachbarn einer zu erklärenden Instanz x (also ähnliche, aber nicht gleiche Instanzen) erzeugt werden können. f bezeichnet die Funktion bzw. die Vorhersage eines Modells bzgl. der Klassifikation einer Instanz. A steht für eine Menge von Prädikaten bzw. einen Anchor, sodass A(x)=1, wenn die Instanz x dem Regelsatz A unterliegt. τ bezeichnet einen Precision-Parameter und die Signifikanz der Erklärung.
Die obenstehende Definition kann wie folgt in Worte gefasst werden:
Für eine gegebene und zu erklärende Instanz x wird ein Regelsatz bzw. Anchor A gesucht, sodass dieser auf die Instanz x zutrifft und zudem mindestens auf einen Anteil τ der davon benachbarten Instanzen, für die das Modell die gleiche Vorhersage trifft.
Die Definition kann mit folgendem Beispiel, im Kontext tabellarischer Daten, veranschaulicht werden:
Wenn von der Instanz x Feature 1 mit Wert 4 und Feature 5 mit Wert -9 vorliegt, dann wird mit einer Präzision von 97,2 % die Klassifikation F eintreten.
Diese Definition wird erweitert um das Konzept der Coverage. Sie wird für eine Instanz x und Regelsatz A durch den Perturbationsraum wie folgt definiert:
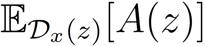
Dieser gibt somit Auskunft darüber, auf wie viele benachbarte Instanzen der Regelsatz zutrifft. Anchors soll einen Regelsatz mit einer möglichst hohen Coverage finden. Da es in den meisten Fällen nicht möglich ist, eine gesamte Nachbarschaft zu untersuchen, wird ein weiterer Parameter δ eingeführt, der eine probabilistische- und Coverage-maximierende Definition erzeugt: 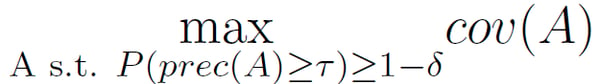
Im Folgenden soll Anchors‘ algorithmisches Vorgehen, mit dem solche Anchors gefunden werden, kurz dargestellt werden. Eine genaue Beschreibung und mathematische Eigenschaften können der originalen Publikation entnommen werden.
Anchors kann in vier Komponenten aufgeteilt werden:
- Candidate Generation: Erstellt neue Regeln bzw. Kandidaten A. Diese erweitern die zuvor identifizierten besten Ergebnisse, indem weitere Prädikate der zu erklärenden Instanz hinzugefügt werden, die bisher nicht enthalten sind.
- Best Candidate Identification: Wertet die erstellten Regeln aus. Dafür werden Perturbationen generiert und anschließend mittels des Models klassifiziert. Auf diese Weise werden möglichst effizient, also mit so wenig Model-Calls wie möglich, die besten Regeln gefunden. Diese Problemformulierung wird angegangen mit Verfahren der Gruppe der Pure-Exploration Multi-Armed Bandits.
- Candidate Precision Validation: Sollte nicht sicher sein, ob ein Kandidat den Threshold τ einhält und somit als Ergebnis in Frage kommt, werden so lange weitere Samples entnommen, bis Sicherheit bzgl. seiner Eignung besteht.
- Modified Beam Search: Setzt alle zuvor erklärten Komponenten zusammen. Diese Komponente operiert in Runden: In jeder Runde wird genau ein Feature der zu erklärenden Instanz betrachtet. Zu jeder Zeit hält der Beam Search Algorithmus B Regeln vor, die als bisher beste Ergebnisse gelten. Damit wird der Suchraum verkleinert. Sollte also B entsprechend hoch gewählt werden, operiert dieser Algorithmus wie ein Breadth First Search. Diese B-Kandidaten werden mittels der Candidate Generation Komponente um das betrachtete Feature erweitert. Anschließend wertet die Best Candidate Identification die Ergebnisse aus. Die neuen besten Anchors werden fortan die von Beam Search vorgehaltenen Regeln. Sollte die Candidate Precision Validation einen Kandidaten validieren, ist dieser ein mögliches Ergebnis und wird zusätzlich vorgehalten. Das Ende des Beam Search Algorithmus markiert die Terminierung von Anchors und liefert das beste gefundene Ergebnis.
Anchors asymptotische Laufzeit bzw. Komplexität weist auf Grundlage der oben dargestellten Komponenten folgendes Verhalten auf:
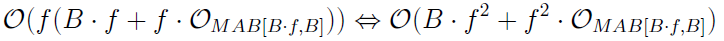
In dieser Grenze wird die Laufzeit des Multi-Armed Bandits ausgelassen. Dies basiert darauf, dass dessen Komplexität nicht klar bestimmt werden kann, da gängige Algorithmen (wie auch der für Anchors vorgeschlagene KL-LUCB) eine Arm-spezifische Laufzeit haben. Diese kann aufgrund von Anchors Modell-Agnostizismus nicht unabhängig definiert werden.
Klar wird jedoch, dass Anchors sensibel auf Instanzen mit einer hohen Feature-Anzahl f reagiert. Sollte ein langsames oder sehr komplexes Modell erklärt werden, muss diese Grenze zuvor in Betracht gezogen werden.
Coverage Pick für globale Erklärungen
Anchors ist lediglich in der Lage, eine einzelne Instanz bzw. ihre Vorhersage zu erklären. Damit lässt sich nur sehr punktuell ein ganzes ML-Modell evaluieren. Es wurden daher Methoden gesucht, die eine Vielzahl von lokalen Erklärungen so aggregieren können, dass eine möglichst relevante und repräsentative Teilmenge davon dem Nutzer zur Validierung gezeigt werden kann.Einen Startpunkt dafür bietet der LIME-Submodular Pick Algorithmus, der genau für diesen Zweck entworfen wurde. Dessen zugrundeliegende Idee ist, dass aus vielen einzelnen Erklärungen ein paar wenige, jedoch repräsentative Regeln abgeleitet bzw. ausgewählt werden können.
Im Kontext von Anchors liefert der Algorithmus jedoch unzureichende Ergebnisse. Auch eine für Anchors angefertigte Weiterentwicklung kann keine zufriedenstellenden Ergebnisse liefern. Grund dafür ist, dass Submodular Pick so geschaffen ist, dass er die Coverage der Ergebnisse nicht optimieren kann. Da jedoch genau diese Eigenschaft ein wichtiges Feature von Anchors ist, werden diese beiden Methoden als keine geeigneten globalen Anchors-Erklärer betrachtet.
Ein neuer Algorithmus wurde entwickelt, genannt Coverage Pick. Dieser maximiert die „wahre“ Coverage der resultierenden Anchors, sodass genau klar ist, wie groß der Bereich ist, den diese abdecken. Coverage Pick konnte in vielen Tests einen hohen Bereich des Modells abdecken und ermöglicht somit eine fast vollständige Validierung eines jeden Modells und schließt die Lücke eines globalen Anchors-Erklärers.

Parallelisierung für bessere Performance
Die erzeugte Java Implementierung erzeugt in Tests im Single-Threaded-Modus circa ein Zehntel des Overheads der Python Referenzimplementierung. Obwohl dies eine beträchtliche Steigerung darstellt, werden weitere Optimierungen in Form von Parallelisierungen gesucht. Grund dafür ist die benötigte Laufzeit der zu erklärenden Modelle: Diese liegen außerhalb des Verantwortungsbereichs der Implementierung und können daher ineffizient und/oder langsam sein. Parallelisierung kann dieses Problem lösen.Da im Fall von Anchors Aufrufe des Modells durch den Multi-Armed Bandit verwaltet werden, muss dieser eine Parallelisierung entsprechend ermöglichen. Leider verfolgen die meisten Algorithmen einen sequenziellen Ansatz (wie auch der vorgeschlagene KL-LUCB), der nur schwierig effizient parallelisiert werden kann. Als nützliche Alternative erwies sich der BatchSAR Multi-Armed Bandit. In Verbindung mit Multithreading konnte dieser die Java Implementierung in Tests um 400 % beschleunigen. Diese Kennzahl hängt natürlich von der eingesetzten Hardware und der Beschaffenheit des Modells ab, jedoch wird deutlich, dass je nach Anwendungsfall enorme Geschwindigkeitszunahmen erzielt werden können.
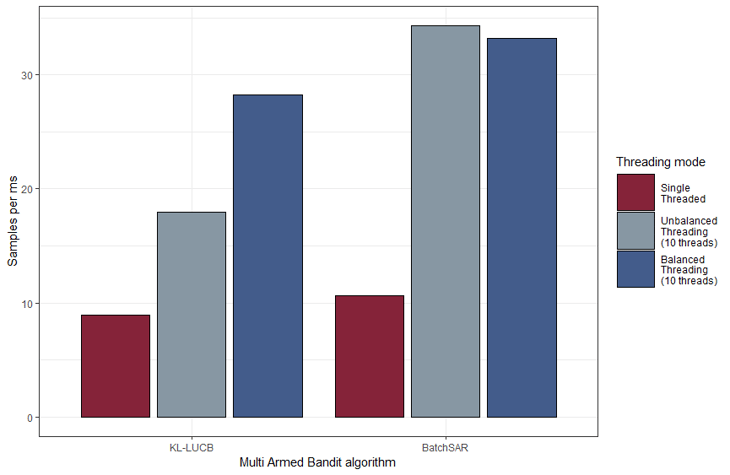
Weitere Parallelisierungsmethoden wurden implementiert, u. a. Message Passing Interfaces und General-Purpose Computing on GPUs. Erstere konnten in der Erstellung einzelner Anchors keine Geschwindigkeitsgewinne verzeichnen, mutmaßlich durch einen hohen Kommunikationsaufwand. Letztere Methodik ist modellspezifisch und kann nicht generisch für jeden Fall angewendet werden, sondern muss vom Klienten direkt für ein bestimmtes Modell implementiert werden. Jedoch können weitere beträchtliche Laufzeitverkürzungen durch GPGPU erreicht werden, weshalb der Einsatz dieser Methodik für jeden Anwendungsfall einzeln evaluiert werden muss.
Verteilung der Ausführung bei globalen Erklärungen
Für die globale Erklärung muss jede Instanz des Datensatzes erklärt werden, bevor die Auswahl der Repräsentanten stattfinden kann. Da dies bei einem Pool von vielen Tausend Datensätzen die Laufzeit um genau diesen Faktor erhöht, wurde es als sinnvoll betrachtet, die Berechnung einer Erklärung pro Datensatz als einen Job anzusehen und diesen an verschiedene Ausführungsorte zu verteilen. Dazu wurde eine Verteilung mittels Apache Spark entwickelt. Dabei werden alle benötigten Bibliotheken in den Spark-Kontext geladen und anschließend alle Instanzen weitergegeben. Spark erstellt zu jeder Instanz einen Job und verteilt diese an die einzelnen Worker-Nodes. Nach Berechnung einer Anchors-Erklärung wird das Ergebnis zurück an den Aufrufer gesendet.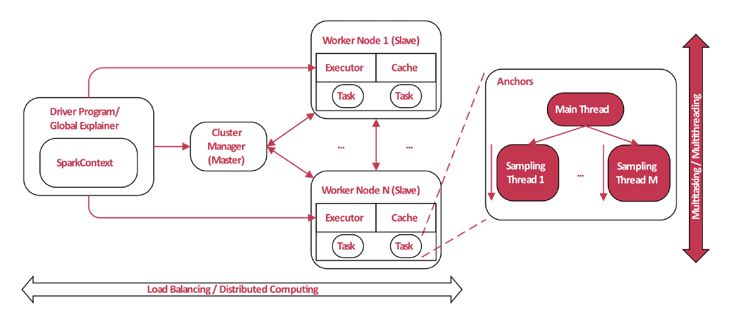
Abbildung 2 Zum Vergrößern klicken
Mit dieser Verteilung ist es möglich, selbst große Datensätze in vergleichsweiser kurzer Zeit global zu erklären.
Und wie „tickt“ mein Modell?
Sie möchten wissen, wie Ihr ML-Modell „tickt“? Wir suchen Test-Nutzer und Kooperationspartner und freuen uns über Feedback, Fragen und Beiträge zum Anchorj-Projekt, das auf Github als OpenSource-Projekt veröffentlicht ist.Hinweis: Dieser Artikel fasst im Wesentlichen Erkenntnisse aus den Abschlussarbeiten von Tobias Goerke (WWU) und Alex Kröker (FH Münster) 2018/2019 zusammen.
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



