

eXplainable Artificial Intelligence (XAI) hat das Ziel, Machine Learning-Modelle zu erklären. Damit die XAI-Algorithmen die Modelle effizient und akkurat erklären können, ist eine Einteilung der kontinuierlichen Werte in Abschnitte sinnvoll: zum Beispiel von einer Temperatur zu zwei Abschnitten warm und kalt. Ohne diese Diskretisierung ist es für XAI schwierig, Modelle zu beschreiben, die während des Lernens dynamisch diskretisieren.
Diskretisierung kontinuierlicher Daten
Eine Vielzahl an Machine Learning-Algorithmen arbeiten ausschließlich mit nominalen Werten oder lernen mit kontinuierlichen Werten langsamer als mit nominalen Werten. Durch sinnvolle Diskretisierung kontinuierlicher Werte entstehen kürzere und kompaktere Ergebnisse mit geringerer Lernzeit, jedoch führt Diskretisierung gleichzeitig auch zu Informationsverlust.
Das Ziel ist es also, einen Diskretisierungs-Algorithmus auszuwählen, der mit möglichst wenig Verlust an Informationen zu optimalen Ergebnissen führt – und das gerne schnell. Welche Algorithmen stehen zur Wahl?
Taxonomie der Diskretisierungs-Algorithmen
Es existieren etwa 100 Algorithmen für die Diskretisierung kontinuierlicher Werte. Diese können unter anderem anhand folgender Kriterien kategorisiert werden:
- Statische Verfahren diskretisieren unabhängig vom Lernverfahren, während dynamische Verfahren erst während des Modell-Lernens diskretisieren. Dynamische Verfahren sind folglich für Black-Box-XAI wie bspw. Anchors eher unbrauchbar.
- Überwachte (supervised) Verfahren beziehen ein Klassifizierungsergebnis in ihren Algorithmus mit ein und versuchen, Grenzen für das Ergebnis passend zu setzen.
- Multivariate Diskretisierung bezieht alle Features und deren Interaktionen mit ein – Ergebnisse sind tendenziell gut, aber aufwendiger zu errechnen und zu interpretieren.
- Beim Splitting werden die Schnittpunkte der Intervalle hinzugefügt, Merging startet mit einer Anzahl an Schnittpunkten und überprüft, ob das Entfernen eines Schnittpunkts die Diskretisierung verbessert.
- Eine Diskretisierung ist direkt, wenn die Werte direkt in die finalen Intervalle eingeteilt werden, eine inkrementelle Diskretisierung fügt Intervalle schrittweise hinzu oder zusammen.
Auf dieser Seite sind die meisten Diskretisierungs-Algorithmen kategorisiert worden.
Beispiele von Diskretisierung
Im Rahmen einer Bachelorarbeit ist das discretizer4j Package entstanden. Hierin wurden verschiedene Diskretisierungen implementiert. Wie verschieden die einzelnen Algorithmen diskretisieren, wird im Folgenden gezeigt. Die Beispiele sind Integerwerte von 1 bis 50 und es kann doppelte Werte geben. Jeder Wert hat eine Klassifizierung von x oder o.
Gewählt wurde eine breite Auswahl von Verfahren mit möglichst verschiedenen, aber nachvollziehbaren Ansätzen und guten Kritiken in der wissenschaftlichen Literatur.

Bewertung verschiedener Algorithmen
Die Bearbeitungszeit der implementierten Diskretisierungen wurde mit zufälligen Werten getestet:
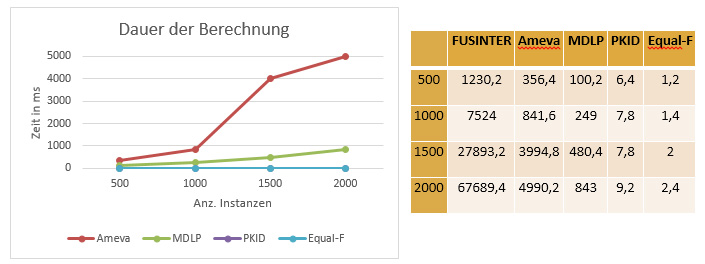
Die unsupervised Diskretiserungen werden im Gegensatz zu den supervised Diskretisierungen nicht inkrementell durchgeführt und haben kein aufwendig zu errechnendes Evaluationskriterium, sondern teilen das Feature direkt in Teilbereiche ein. Hierdurch entsteht eine geringere programmatische Komplexität. Sie können jedoch durch das Nichtbeachten der Zielklassifizierung einen höheren Informationsverlust erzeugen, da bedeutende Entscheidungsgrenzen übersehen werden.
Bewertung im allgemeinen Machine Learning-Kontext
Es muss fallbezogen analysiert werden, ob Diskretisierung sinnvoll ist und ob der Mehraufwand durch die Wahl einer supervised Diskretisierung für den Anwendungsfall begründbar ist. Hierzu wurden bereits einige Studien durchgeführt:
- Doughtery et al. zeigten, dass auch einfache Diskretisierungen die Accuracy verschiedener Verfahren in den meisten Fällen erhöhen.
- Garcia et al. zeigten weiterhin, dass die optimale Wahl der Diskretisierung je nach Anwendungsfall stark variiert – je nach Machine Learning-Verfahren und Datensatz. Es war also nicht möglich, die beste Diskretisierung herauszufinden.
Bewertung im Explainable AI-Kontext
Der XAI-Algorithmus Anchors bildet Wenn-Dann Regeln, um einzelne Instanzen zu erklären. Eine Regel beschreibt beispielsweise, dass wenn eine Instanz im Feature a den Wert x und Feature b den Wert y hat, die Vorhersage z getroffen wird. Die Regeln werden mit Precision und Coverage bewertet. Hierbei versucht Anchors, Precision und Coverage zu maximieren, um Regeln zu finden, die einen großen Anteil der Instanzen (Coverage) mit einer hohen Genauigkeit (Precision) beschreiben.
Ein kontinuierlicher Wert würde in diesem Algorithmus oft zu Regeln mit hoher Precision und sehr geringer Coverage führen, da nur wenige Instanzen den gleichen kontinuierlichen Wert besitzen. Somit würden die Regeln im Anchors-Algorithmus meistens von Regeln mit ausschließlich nominalen Werten dominiert werden. Da kontinuierliche Werte für die Entscheidungsfindung genauso von Bedeutung sein können, sollten sie vorab diskretisiert werden. Hierdurch hat jede Regel nun eine höhere Coverage, jedoch wird aufgrund des Informationsverlustes der Diskretisierung eventuell Präzision verloren gehen.
In der folgenden Abbildung sind die bisher im discretizer4j-Projekt implementierten Diskretisierungen auf den bekannten Titanic-Datensatz angewandt worden. Hier ist bspw. das Alter der Passagiere bekannt und auch ein guter Predictor. Hier wäre die ideale Erklärung eigentlich schon vorab bekannt: „Frauen und Kinder zuerst“.
Die maschinell entstehenden Anchor-Regeln lassen sich in Bezug auf Precision und Coverage vergleichen. Durch die Zufalls-Aspekte der Algorithmen entstehen dazu Punktwolken, für die sich auch je eine Regressionsgerade lohnt.
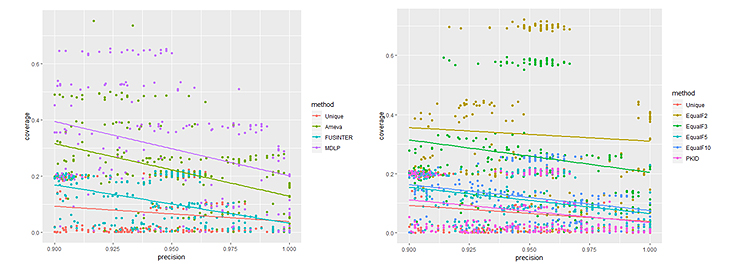
Wie man auf den Abbildungen sieht, ist der Coverage-Unterschied aller Verfahren zum Nicht-Diskretisieren (Unique) erwartungskonform hoch. Ohne Verlust von Precision vervielfacht sich die Coverage der Regeln in einem Großteil der Fälle.
Der hier beste Diskretisierungs-Algorithmus (aus dem discretizer4j-Projekt) für den Titanic-Datensatz scheint MDLP zu sein – ein Klassiker. Dies ist jedoch, wie oben beschrieben, immer datenspezifisch und nicht verallgemeinerbar.
Fazit
Aufgrund der Anwendungs- und Datenspezifität der Diskretisierungs-Algorithmen haben wir uns entschlossen, für XAI- und Machine Learning-Anwender ein Repository mit einer Auswahl an in Java-implementierten Algorithmen bereitzustellen, sodass die Anwender in der Lage sind, den für Ihren Fall optimalen Algorithmus auszuwählen. Das Open-Source Repository discretizer4j ist mit sieben verschiedenen Diskretisierungs-Algorithmen aufgesetzt.
Sie möchten Ihre Daten diskretisieren oder einen Algorithmus hinzufügen? Wir freuen uns über Ihr Feedback, Fragen und Ergänzungen zum discretizer4j-Projekt.
Hinweis: Dieser Artikel fasst im Wesentlichen Erkenntnisse aus der Abschlussarbeit von Marvin Gronhorst (FH Münster) 2019 zusammen.
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



