
 MLOps platforms such as Kubeflow promise many benefits to data scientists. However, once you get past the tutorials and sample pipelines, you run into some problems when breaking down the workflow into independent components. We want to share our experiences with corresponding Kubeflow pipelines.
MLOps platforms such as Kubeflow promise many benefits to data scientists. However, once you get past the tutorials and sample pipelines, you run into some problems when breaking down the workflow into independent components. We want to share our experiences with corresponding Kubeflow pipelines.
The goals of Kubeflow and similar platforms are appealing: We want to easily orchestrate machine learning (ML) model lifecycles in automated, scalable, and reproducible pipelines, and thus hope to successfully bring ML systems into production. By scalability, we mean both handling large amounts of data and working meaningfully in large teams on multiple questions.
In this blog post, we will share our experiences with the Kubeflow Pipelines (KFP) MLOps platform, the problems encountered, and respective approaches to solving them.
Modular components in ml - what do we want to achieve?
To create an end-to-end pipeline, an ML workflow is divided into individual components and according to the “Separation of Concerns” design pattern, the steps are logically separated from each other. This modular design makes pipelines highly flexible and components, once written, can be reused in other contexts if desired.
What at first sounds like superficial buzzwords for the first time seems realistically achievable with the Kubeflow platform: Each work step is encapsulated in a container and therefore isolated and its results are reproducible.
In this way, entire ML ecosystems are emerging, such as Google's AI Hub, intending to promote collaboration and the reusability of applications and resources in the ML environment. Modularity improves pipeline transparency through traceability of automatically archived component results (good for debugging). Furthermore, it should generally facilitate writing component-based unit tests (good for quality assurance).
Google addresses the questions of what and how intensively should be tested in ML systems to achieve production readiness and reduce technical debt ("technical debt") in a paper. Since technical debts tend to proliferate, attention should be paid to the testing of training data, the model development, and monitoring during deployment, as well as testing the infrastructure. Among other things, the latter refers to the determinism of pipeline steps (e.g., training, where the same data should produce the same models), and unit testing of the model specification, i.e. API usages and algorithmic correctness.
Even with Google's recommended ML-centric testing, deterministic steps with encapsulated logic should always be strived for so that your ML model or ML pipeline is ready for production. The considerations in this research paper ultimately led to the development of TFX and Kubeflow. The task now is to deliver on these goals.
Problems with modular components in kubeflow pipelines
A Kubeflow pipeline consists of several orchestrated components (called operations). The outputs of a component can be consumed and further processed by subsequent components.
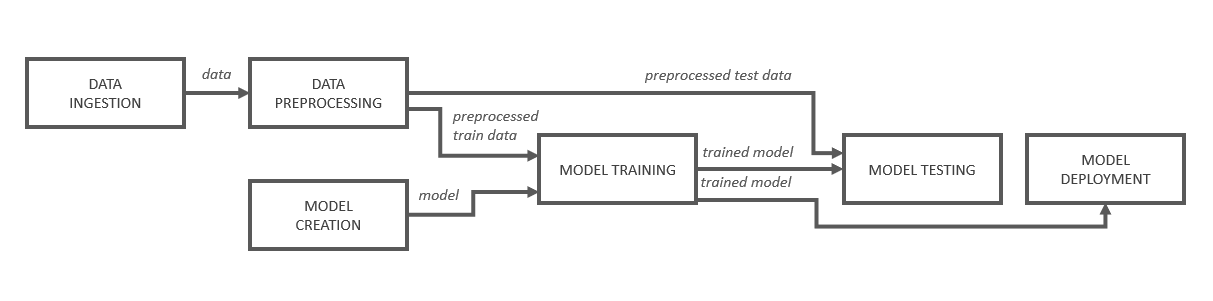
Figure 1: Schematic structure of an ML pipeline
The "Model Training" component from figure 1 receives the reference to a model from the "Model Creation" step, which is then loaded and trained with the training data preprocessed in another step. Through the data flow, Kubeflow automatically derives a Directed Acyclic Graph (DAG).
Each containerized component is started in its own Kubernetes pod when executed in a pipeline. This brings maximum flexibility: Programming languages and versions of frameworks can be mixed and matched.
In the simple ideal case, a project consists of only one piece of Python code, and the DAG is also declared in Python. The concept of modularity means that modules cannot resolve any dependencies "upwards" (i.e. to executing code). For this reason, the code must be self-contained, i.e. all the functionality required for execution must be defined directly in the module method itself. Also, all required libraries have to be imported locally.
Therefore, reuse of centrally provided functionalities (e.g. from helper modules) is quite difficult, although in many cases it’s very useful and desired. Of course the necessary functions can be packed into sub-methods of the components, but the components then become unnecessarily large and the boilerplate code written in several places is difficult to maintain and can easily become inconsistent. In addition, sub-methods are not good to test in Python: Unit tests apply to whole operation since it's one method. It is questionable whether a complex process with multiple processing steps can or should still be considered a single unit. Normally, unit tests should examine the smallest testable part of a process individually and independently.
The Kubeflow components run in separate pods, which is why they do not share a common file system and all processed data is lost after the pod is terminated. To enable further processing of the produced data, the transfer between the components is usually done using explicitly agreed transfer paths called "OutputPaths" and "InputPaths". Components can save and load files to these file paths provided by Kubeflow, which point to either a Persistent Volume Claim (PVC) or a cloud storage service. Because the result artifacts from each component of all pipeline runs are reliably archived by Kubeflow, problems can arise when e.g. a dataset with thousands of high-resolution images is processed and must always be cached. In this blog post, we go into some of the problems that arise in this process, as well as suggested solutions. But back to the topic: Outsourcing the helper functions to their own components is also undesirable - to prevent multiple caches of data, but also to maintain the logical structure of the pipeline and not make it unnecessarily confusing.
Solution approaches: How can code reusability be implemented within kubeflow components?
As mentioned earlier, it makes sense to keep a component as lean as possible to enable maintainability and testability of both the component and the helper functions used within it. From a technical point of view, it’s also very important that these helper functions are implemented identically everywhere and can be further developed at a central point if required. Common visualizations, data quality checks, and preprocessing steps such as contrast enhancement or feature imputation must therefore be outsourced.
But How is this outsourced code then accessed in a meaningful way from a Kubeflow pipeline?
In our projects, we had to deal with this question and in the following, we will go into several possibilities and workarounds that are more or less suitable - depending on the maturity of the helper functions. Here, we focus on a component creation within a Jupyter Notebook using func_to_container_op, which is quite very data-scientist and user-friendly. This feature of the Kubeflow Python domain-specific language (DSL) allows you to build Kubeflow components directly from Python functions given a specific Docker image.
MAke the code available as a package
In case the development of the reusable helper functions has already been completed, they can be made available within a package in a public (e.g. Python Package Index (PyPI)) or private repository. This code sharing is very useful for making tested code available across teams or even organizations.
To be able to import and use them within the operation, one has two options to choose from:
- A custom Docker image with the pre-installed package is built and used as the base image in func_to_container_op.
- The packages to install are passed to func_to_container_op as "packages_to_install" argument. This passed string list of (versioned) packages will be automatically installed by Kubeflow using "pip install" before executing the component function.
However, both options require that the code provided in the package has a certain level of maturity, as each iteration of further development is quite time-consuming. Changes should be documented, tested, and the code tagged with a version control system (e.g. git) before the package can be rebuilt and published to the repository.
For development-stage code that changes frequently, this approach is too arduous.
using an accessible volume for the code
Another option is to store the code on a Kubernetes Persistent Volume (PV). A PV abstracts the storage layer and is a directory whose files can be accessed by pods when they mount it under a specified path, so they can be loaded or imported. The persistence of the helper code is not tied to the lifecycle of the pods.
Let's try this out on an example component that calls the test function from the helper module. To make the Python interpreter find the required reusable modules, you must add the parent directory and the volume path to the system path within the component method.
In this pipeline, the helper module is located on the volume with the PVC "sharedcode" so we mount it to the task “test” under the path "/sharedcode":
This approach works well if you’re still in the development phase, and you mount the volume to both the Jupyter notebooks and the pipeline steps: Changes in the code can be made directly in the UI and its functionality is automatically updated when the pipeline is restarted.
However, attention must be paid to the versioning of the files if the workspace managed by git is not the same as the volume. To always use the latest version and avoid inconsistencies, it is recommended to check or copy the required files before each pipeline execution. Also, make sure that the selected volume is available and has the accessMode "ReadWriteMany" so that it can be mounted by multiple pods (simultaneously).
This solution makes collaboration easy, but also potentially risky: There could be changes from other team members at any time - even while a pipeline is running.
Using a ConfigMap
ConfigMaps are Kubernetes objects used to store non-confidential data in key-value pairs. They are available within a Kubernetes namespace and can also be used in Kubeflow pipelines (in the respective namespace). Usually, they are used to store environment-specific configurations, however individual files or entire folders can also be converted to a YAML format using Python code. The ConfigMaps can be mounted to the pods in the form of volumes. The keys are used as file names unless a specific mapping from key to file path is specified.
With the following commands, a ConfigMap "helpercm" is created and described, containing the reusable code of the file "helper.py".
Inside the pipeline, the volume is then created from the configmap and mounted to the pod in the same way as the pipeline "pipeline_volume" code. The test_func listed above remains unchanged.
The ConfigMaps workaround is more lightweight and secure compared to the volumes alternative since the volume exists only at pipeline runtime.
Injecting the code with modules_to_Capture
In a final proposed solution, we demonstrate the "modules_to_capture" argument of the func_to_container_op. Figuring out exactly how to use the argument took some effort. However, if you follow the steps listed below, it is easy to use and very convenient compared to the variants above.
- Similar to the "packages_to_install" the name of the module is passed as a string.
- It must be loaded globally before that, which means outside the component function that requires it (e.g. in Jupyter Notebook).
- The code is serialized by code-pickling and injected into the component. For this, "cloudpickle" is used in the background, which is why it must also be installed as a package (packages_to_install=['cloudpickle']). Because the dependencies in the module are also serialized, the helper module can also make use of additional packages.
- Within the component, the passed modules are deserialized and can then be used normally without further imports.
A big advantage is that the helper modules can also be in the current workspace, which makes it easy to manage the module with git. Since serialization happens when the component is created, code changes to the helper functions are applied immediately to newly generated components.
Conclusion
Even though Kubeflow strongly encourages the reuse of entire components (in the form of YAMLs), it lacks support for the reuse of smaller functionalities (e.g. from helper modules). Therefore, this blog post listed four solution approaches that allow reusing functionalities in Kubeflow components despite their strong encapsulation.
An optimal solution does not (yet) exist and depends on the project as well as the development stage of the reusable code. In summary, when using already released (versioned) packages, installing via pip (argument "packages_to_install"), or specifying a custom Docker image is very suitable.
When working in a (Jupyter) notebook, you can put shared code on a volume that is mounted by both the notebook and pip. Changes to the code via the notebook are directly mirrored, so this mode is good if the code is still in the development stage. Alternatively, it can be written to a ConfigMap, which is then added by each component. Care must be taken to ensure that the code is always up-to-date and similar to that in the workspace. It might be useful to execute an intermediate copy step before the use of a volume and to update the ConfigMap through "kubectl apply".
An intermediate step is omitted with the last variant with "modules_to_capture" since changes are taken over directly and further, in it used modules, likewise loaded.
Even if these alternatives seem arduous at first sight, their use is worthwhile: To avoid boilerplate code, to keep the components small, and to make both the components and the helper methods better testable and maintainable. By reuse, you provide consistently interpretable results and less technical debt.
Kubeflow and BIg Data Handling
Also read our blog post on Kubeflow Big Data Handling, where we explain different approaches (and their difficulties) for combining big data and Kubeflow pipelines.
Deepen your knowledge with our Kubeflow seminar
Have we sparked your interest? Book an appointment for our Cloud Native AI seminar here to learn more about MLOps with the Kubeflow platform.
Back to blog overview

