
 Metadata from machine learning models and their underlying data is critical to enable reproducibility in ML. Reproducibility is essential for reliable production deployments.
Metadata from machine learning models and their underlying data is critical to enable reproducibility in ML. Reproducibility is essential for reliable production deployments.
To understand, analyze, troubleshoot, and improve a model, data scientists must understand its input data and all data processing steps. The Kubeflow platform helps us do this: It tracks and archieves all data produced during the lifecycle of a model - this is a key feature of Kubeflow Pipelines. However, once the platform is used for real-world use cases with big data, some model lifecycle reproducibility features can become impeding for the user.
In this blog post, we illustrate the reasons and will also give you several possible solutions to efficiently handle Big Data within Kubeflow Pipelines.
Issues related to big data in kfp
A Kubeflow pipeline consists of several orchestrated components (called operations). The outputs of a component can be consumed and further processed by subsequent components.
The "Model Training" component from figure 1 receives the reference to a model from the "Model Creation" step, which is then loaded and trained with the training data preprocessed in another step.
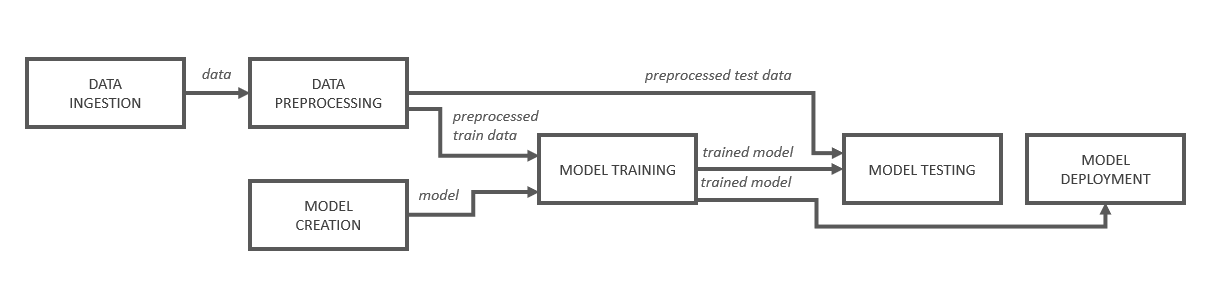
Figure 1: Schematic structure of an ML pipeline
Kubeflow executes each of these pipeline steps in an isolated environment or pod. This has some consequences. The steps do not share a common file system through which files could be shared.It also means that all processed data is lost after the pod is terminated.
To enable further processing of the produced data despite this limitation, Kubeflow provides a mechanism that organizes the data transfer between the components. Developers can request this by using the TypeHint "OutputPath". A file path is then provided where files can be stored.
Kubeflow copies the stored content to either Artifact Storage ( Pipeline Root, MinIO, S3 or GCS ) or to a Persistent Volume Claim (PVC). Subsequent steps can request and use these files with the "InputPath" counterpart. Code section 1 illustrates the use of the Kubeflow paths.
Code section 1: Kubeflow Pipeline using OutputPath and InputPath
Each run of an ML pipeline generates metadata with information about the various pipeline components, their executions (e.g. training runs), and the resulting artifacts (e.g. trained models). The fact that the output of each pipeline component is cached is very good for the traceability, but with large data sets this leads to problems.
If, for example, data sets with thousands of high-resolution images are loaded (and stored) and preprocessed (and stored) for each step in each pipeline run, the memory limit of the Artifact Store is quickly reached. However, in order to reduce the amount of stored data and to speed up serialization and deserialization, reducing the number of components is not a solution either:
You should aim for modularity and keep the tasks of the individual pipeline steps logically separated from each other (according to the design pattern "Separation of Concerns").
How can this be achieved? In this blogpost we tell you how to overcome those obstacles when using common functionalities.
But how can you enable and make efficient the passing and archiving of large amounts of data in ML pipelines?
1. Use of (temporary) Volumes to relieve the artifact storages
Kubeflow allows the use of persistent volumes (PVs) in the pipelines. A Kubernetes volume abstracts the storage layer and is basically a directory whose files can be accessed by pods when they mount it under a specified path. When each component mounts the volume, they can use arbitrary libraries to store data or files on it and load them. Either existing persistent volumes can be used, or ones that are created within the pipeline with a VolumeOp and then automatically managed by Kubeflow. Although persistent volumes generated in the pipeline can be deleted after the pipeline has been run, it makes sense to keep them for caching purposes (more on this later).
2. PASSING REFERENCES INSTEAD OF VERY LARGE AMOUNTS OF DATA
In a project with many GB of images, the memory limits of the Artifact Store did not allow us to serialize the processed data into an OutputPath after each step. So they could not be passed via the OutputPath/InputPath pattern. Merging the functionalities at the expense of modularity and thus avoiding caching was out of the question for us. Instead of passing the actual data, we passed their storage paths as arguments, which refer to a volume accessible for all components. The references can be passed as plain strings (e.g., a folder name); however, if there are a large number of individual file paths, it is still a good idea to store the strings in an OutputPath.
For option 1, the pipeline operations must mount the volume in each case in order to access the data. If we assume we changed the component’s method definition to pass references with string arguments instead of OutputPaths and InputPaths, the pipeline implementation would look like this:
Code section 2: Using volumes for passing references instead of actual data
In this way, exchange of very large data between steps is enabled with minimal overhead (no upload/download of data to/from external object stores) and in a vendor-neutral way. Components can directly access the object store with any load library and their execution becomes faster. No TB of data is cached and when using volumes, the problem of full storages is solved. However, the benefits of archiving are also lost: With the now archived metadata (the file paths) it is only possible to trace what data was processed, but not what its input and output state was at each component.
If you want to ensure persistence of workflow history and reproducibility of the steps, you can create volume snapshots. This point-in-time copy of a volume can be used either to rehydrate a new volume (pre-populated with the snapshot data) or to restore a previous state of the volume represented in the snapshot. Creation is quite efficient, even with multiple GBs, and can be triggered from a Kubeflow pipeline. Before passing the data on to the next task, a snapshot can be created in this way, which can also be mounted by pods.
Caution when writing pipelines: Using a volume for data passing does not tell the pipeline controller in which order the tasks are executed! Usually, the Directed Acyclic Graph (DAG) is derived by Kubeflow by the data flow indicated by Output- and InputPaths. Therefore, it is necessary to concatenate the tasks explicitly with the <task2>.after(<task1>) method, so that each method accesses the stored data at the right time.
3. USE OF KUBEFLOW CACHING
Kubeflow's caching mechanism operates at the component level and is enabled by default. As soon as a task (an instantiated operation) is executed, Kubeflow checks if an execution of the same task interface already exists. An interface consists of the task specification (the Docker base image, the executed command and arguments), and the task inputs (input value or artifact). In case of a match, archiving in the Artifact Store allows the task not to be executed, but to reuse the output of the identical component.
The use of the cache is very useful for time- or computationally-intensive tasks, such as downloading large amounts of data or training with the same data.However, for certain tasks it is undesirable. In this case you can specifically disabled it for the individual steps or even for entire pipelines by setting the cache expiration time to "0 days". If you disable caching for one task, subsequent tasks will not be cached either - unless the interface (inputs, outputs, specification) is the same. Nevertheless, caution is advised, as the next sections will show.
SOURCES OF ERRORS WHEN USING CACHING
Caching despite deactivation
Figure 2 shows the image-processing pipeline mentioned earlier. Here, caching has been explicitly disabled for the "Process data" step, yet the subsequent step is cached. Why?
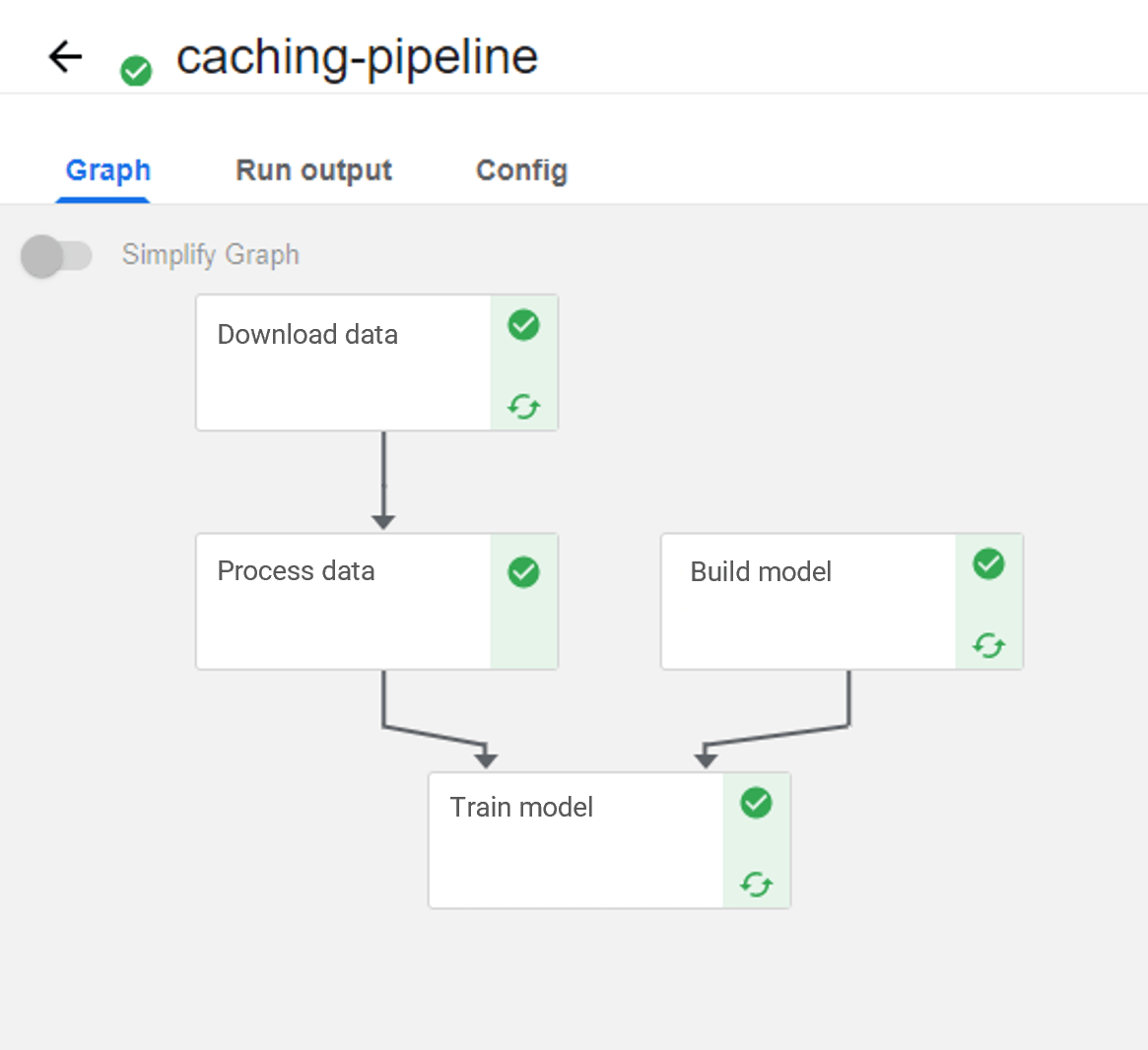
Figure 2: ML pipeline with cache disabled for "Process data"
Instead of writing the images to the OutputPath, the component was just passed a list of their file paths (see option 2) referring to a mounted volume. The problem with this is that the caching takes effect because the inputs (the image paths) have not changed, but the images behind the paths might be different.
By the way, in this respect the Kubeflow Pipelines SKD v1 differs from the second version (or the v2 compatible mode): There, not only the input artifact is considered, but also the input name and ID. In any case, an uncached task produces an artifact with a new ID, which is why the subsequent ones are also re-executed. Unfortunately, in Kubeflow Pipelines SDK v2 DSL, it is currently not possible to set a cache expiration time at task level. Caching can only be specifically disabled for entire pipelines by passing the "enable_caching=False" argument to the run_pipeline (or create_run_from_pipeline_func) function.
Tip: If you want to work around the problem in Figure 2, you can pass an additional parameter (e.g., a hash) to the next component that is different from the input of the cached executions. This triggers a re-execution.
Caching files in other locations
Combining cache usage and passing string references instead of Kubeflow paths also has the potential of causing errors. Suppose files are written to a volume in one step. When a new pipeline execution mounts another persistent volume under the same path, the results of the previous volume are found and "reused". Therefore, they are not written to the volume that is actually mounted! If the subsequent step, which is not supposed to use a cache, then wants to collect them, there may be inconsistencies between the data and the actual result of the previous step, since the result is not necessarily stored in the same location.
Tip: A simple workaround for this is to include the name of the volume (or PVC) used in the volume mount path. For example, in code section 2, "my_mounted_volume" would be replaced with "my_volume". If a different volume is used, the component input changes and the problem does not exist. However, it is still necessary to ensure that the data on the volume is not manipulated/deleted.
4. CHANGING THE DATA PASSING METHOD
By changing the data passing method in the pipeline configuration, we can use a volume without having to include it in every component. All artifacts are thus transferred via the selected volume, which must, however, already exist before the pipeline is started. This transfer method has the advantages that Output- and InputPaths can be used as usual and a manual volume mount to each individual component becomes obsolete.
Code section 3: ML pipeline with a volume-based data passing method
However, all artifacts are lost when the volume is deleted, so care must also be taken to back up the state using a volume snapshot if necessary.
Attention: Currently, caching with the modified data passing method does not work yet. The steps are executed again each time (see the following GitHub issue).
Conclusions and Recommendations
Which data passing method is best suited for a pipeline depends, again, on the use case. One can/should ask the following questions:
How much data is exchanged between how many steps?
Since the pipeline root storage space is used by all components of all pipelines, storing very large amounts of data into the OutputPaths is not recommended. Instead, references to the data sets (e.g. image paths) can be passed via strings or via OutputPaths. OutputPaths, compared to strings, at least provide information about which data was viewed by the steps (not about their state, though). If a detailed versioning of the artifacts is important, then one can reconfigure the data passing method to use volumes. But again, care must be taken not to modify or delete the volume being used.
Care should be taken when using the caching mechanism:
- Have the output artifacts on the volume been modified?
- Do I always use the results of the same volume within a pipeline?
- Do I want to specifically disable caching because some processing steps within a component have changed?
Regardless of the size of the data to be stored, you have to ask yourself how critical the traceability of the pipeline is:
Should all steps and their inputs and outputs be archived and versioned?
This is where reproducibility becomes relevant: End-to-end tracking and versioning of the intermediate and final artifacts of an ML workflow gives ML modelers access to fully reproducible results, speeding up their model iteration and rebuilding. In ML projects, it is not only important to version the code, which is always versioned in an exemplary manner by a software developer, but also the data and models.
Regarding reproducibility and finally the traceability of the data preprocessing: Helpful tips can be found in our bpmn.ai patterns, e.g. the process pattern "Increasing Levels of Deconstruction".
If tracking of the experiments is important and the intermediate results of the pipelines should be preserved and remain visible, then the use of the "normal" InputPath and OutputPath and the resulting storage in the Artifact Storage is recommended, since volumes are bound to Kubeflow Profiles and can theoretically be deleted by any member of the respective Kubernetes namespace. Although artifacts can also theoretically be deleted from the Artifact Storage, in practice users lack the permissions and Kubeflow-specific knowledge to do so.
Upcoming: We would like to contribute a solution to Kubeflow that allows the deletion of artifacts and their caches. Should such a solution find its way into the Kubeflow ecosystem, user would be able to manage their artifacts independently in the Artifact Store and thus prevent storage shortages.
In summary, large amounts of data can be a challenge for MLOps platforms like Kubeflow, but as seen in this article, they are manageable. Certainly, if processing of such data volumnes is necessary, Kubeflow (with its underlying quasi-"inexhaustible" cloud resources), is a good choice. For sure Kubeflow is a good choice when traceable data processing is required.
If we sparked your interest in Kubeflow as an MLOps platform, book an appointment for our Cloud Native AI seminar here to learn more about MLOps with the Kubeflow platform.
Back to blog overview

