
In this Blogpost we tackle the question: Can NLP AIs auto-complete Business Processes? Take a look at our machine learning prototype, which is able to understand half-done BPMN 2.0 business process models and gives recommendations for the label and object type of the next element.
Why Would I Need an AI for Process Modeling?
There are many ways to support business process modelers from modeling guidelines to built-in syntax checkers. So far, there is no such thing as auto-completion like we are used to from smartphones and software development alike. Machine learning has shown outstanding results in prediction tasks, which can also be applied to business process modeling. The aim of the research prototype is to support modelers already during the modeling process and promote semantically and syntactically correct business process models efficiently.
The idea is to provide recommendations on the label and type of the forthcoming process element and it's position in a “half-done” process model that the modeler can easily accept and implement with one click or decline and implement an own idea as usual. The recommendations are created by the Generative Pre-trained Transformer 3 (GPT-3) language models by OpenAI, which are one of the most advanced language models on the market.
How Does the Prototype Work?
The prototype uses the dataset created by the Business Process Management Academic Initiative (BPMAI dataset, ~ 30k models), which includes models in several modeling standards and natural languages in JSON format. The creation of the prototype can be described in four main steps, which will be explained in more detail in the following paragraphs.
- Select useful models from the BPMAI dataset (i.e. English BPMN models with a minimum level of detail and complexity)
- Create a textual representation of those models (using Mermaid syntax)
- Fine-Tune the GPT-3 Babbage Model with those models
- Predict the label and type of the next element on a random sample of BPMN processes (cut half way through to simulate an ongoing modeling session)
The research is limited to English BPMN 2.0 models so far. Furthermore, those models where the longest label is still shorter than 4 characters, and those which do not provide enough context are excluded from the dataset in the first step.
Since GPT-3 models work with textual data, the remaining process models need to be transformed into a computer readable textual format that can represent the label, type and connections of the elements. Mermaid markdown language is chosen for this purpose in the second step as it was developed to describe different diagram types in a compact textual format (i.e. markdown), which GPT-3 is able to handle well. The upper part of Figure 1 shows the first few steps of an exemplary business process model in BPMN 2.0 representation, while the lower part shows the same business process model, but in Mermaid textual representation.
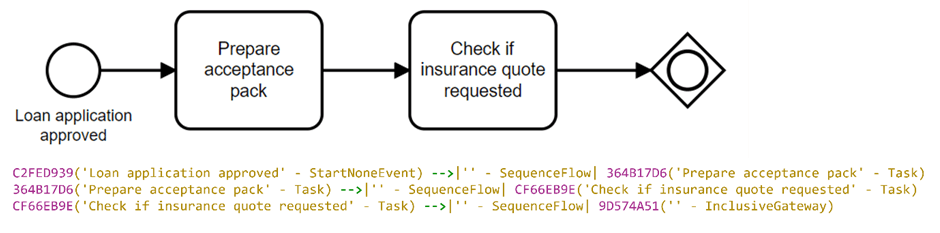
Figure 1: BPMN 2.0 and Mermaid textual representation of the same exemplary business process model.
Although GPT-3 models are pre-trained on an enormously large corpus from the internet and probably have seen examples of the Mermaid syntax, more complex BPMN models represented with this syntax might still be a challenge for GPT-3 models to understand. In the third step, two GPT-3 models are selected for prediction based on their capabilities. The Babbage GPT-3 model has its strengths in pattern recognition and completion, while davinci is the most capable model from the GPT-3 model family across different tasks. However, we only fine-tuned the babbage model for BPMN processes, because it is 50 times more cost effective than the davinci model.
Last but not least, next element labels and types are predicted with the davinci base model and the fine-tuned babbage model. The input is a “half-done” English BPMN 2.0 model from the BPMAI dataset, while the output is the input model and an additional model element with label and object type, connected to one or some of the previous model elements.
How Good Are the Predictions?
This is a difficult question, since many different predictions are potentially good ideas. We came up with a two step evaluation:
The predictions are satisfactory, if they meet certain semantic and syntactic criteria and can be mistaken by human work, so it seems like they were created by a human modeler. Predictions by both the base davinci and fine-tuned babbage model pass the following criteria:
- The predicted label is syntactically correct, if available.
- The predicted label is written using the same natural language as previous model elements, if available.
- The predicted label is part of the same domain as the previous elements in the input business process model, if available.
- The predicted label is semantically correct considering previous process elements, if available.
- The predicted element is connected to one or some of the previous model element(s) and does not stand "alone" in the canvas OR the predicted connection connects two already existing process elements.
- The output of the prototype is syntactically correct.
To evaluate “human-likeness”, a questionnaire is created, which has three main parts. First, participants are shown BPMN 2.0 process models and are asked to guess if the last step was created by a human or by a GPT-3 model. An examplary question is shown in Figure 2. Then, the personal BPMN expertise, confidence level and ease of decision-making of the participants are assessed. Finally, participants have the option to reflect on their experience with the questionnaire in more detail in form of an open-ended question.
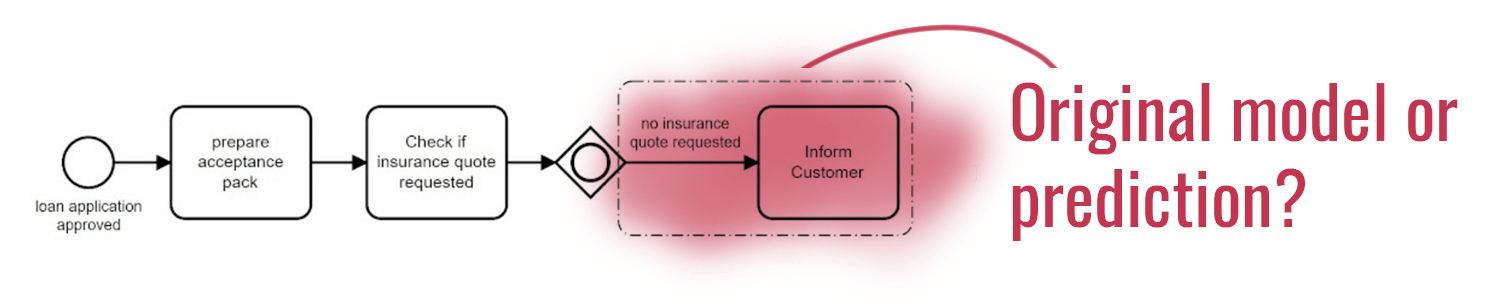
Figure 2: Exemplary question from the questionnaire where the aim is to decide if the last step (highlighted with red color) was created by a human, or a GPT-3 model.
60 people participated in the questionnaire with various BPMN backgrounds. The overall picture is clear: Participants could not correctly and confidently choose the creator of the last step, since only 58% of the answers are correct. According to Figure 3 and the answers to the open-ended question, participants found it hard to decide whether the last step was created by a human or a GPT-3 model. They were also not too confident whether they guessed correctly.
Not to our surprise, participants found it the most challenging to select the creator of the last element in those cases where it was created by the fine-tuned babbage model. Furthermore, the decision process of participants was sometimes contradicting. Some thought if the label of the predicted last step is syntactically incorrect, it must have been created by a machine learning model. However, some assumed the opposite and reasoned that prediction models were probably created the way they would not provide syntactically incorrect predictions. Thus, syntax errors in labels must be human errors. The scores on the correct answers, ease of decision and confidence levels of participants show that it was difficult to select the creator of the process and that participants were rather unsure about the correctness of their decisions. This indicates that the predictions can be mistaken for human work, which is a strong sign of the viability of the prototype.
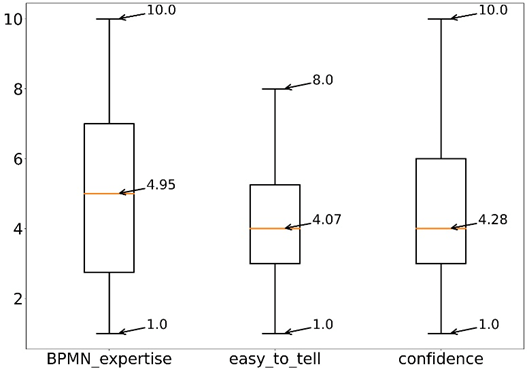
Figure 3: Univariate analysis of the self-assessment variables.
As it can be seen in Figure 3. the participants had a broad range of BPMN expertise, ranging from viadee's BPM experts to students with hardly any BPM experience. Statistically speaking, BPM expertise does not help to identify our auto-generated model elements significantly.
What Are the Limitations?
There are a few limitations of the prototype due to time and budget constraints so far: BPMN 2.0 has an extensive number of objects that are not easy to be represented only with the toolset of the Mermaid markdown language. Thus, this prototype only considers flow objects and the sequence flow connecting object from the BPMN 2.0 standard. Furthermore, GPT-3 models can only be used with a commercial licence. Finally, the babbage model was fine-tuned on a limited dataset to keep the costs low. However, the results of the questionnaire showed that the fine-tuned babbage model provided more “human-like” predictions than the base davinci model. Thus, the prediction quality has the potential to be improved by using a bigger dataset and more refined fine-tuning parameters.
What's Next?
The prototype proved the viability of the concept of next element prediction, but the prediction quality can be improved. Moreover, the prototype does not provide a user interface yet, nor is it refined enough to be integrated into already existing modeling tools such as the viadee BPMN Modeler for Confluence: Predictions will need to be both of consistently good quality and fast enough to speed up a modeling session, in order to be accepted by the user base while keeping prediction costs low enough.
However, speeding up the BPMN modeling experience is not the only benefit we hope for. Predictions could foster the consistent use of glossary define terms. Process modeling also is a creative challenge of changing perspectives and envisioning edge cases. If AI-generated art can win art prices in Colorado, we hope that a model element generator can help business analysts to come up with additional ideas and create more complete business processes (or test data). Finding a missing edge case early could be exceptionally useful.
Please get in touch if you want to see functionality like this in the BPMN Modeler for Confluence!
--
This blogpost is based on the Master's Thesis of Viktória Farkas (2022), in cooperation with the Information Systems Department / ERCIS, WWU Münster.
--
The article picture was generated via Stable Diffusion under creativ commons license.
Back to blog overview

