
In einer Welt, in der intelligente Chat-Tools über umfangreiche Wissensdatenbanken verfügen, verbleibt oft eine entscheidende Lücke: die effektive Nutzung eigener, unternehmensspezifischer Daten. Denn während die Tools meist über genügend Allgemeinwissen verfügen, müssen bisher unbekannte und interne Daten zunächst zugänglich gemacht werden. Wird diese Chance von Unternehmen genutzt, kann der Wert der eigenen Daten erheblich gesteigert werden. Denn nicht nur werden die eigenen Daten aus verschiedensten Quellen (bspw. aus relationalen Datenbanken) so besser zugänglich und leichter zu finden, sondern sie werden durch die Interaktion mit Chat-Tools auch leichter zu verstehen.
In diesem Blogbeitrag zeigen wir, wie verschiedene Datenprodukte miteinander verknüpft und nahtlos in Chat-Tools integriert werden können, damit die leistungsstarke KI von ihnen Gebrauch machen kann.
Dieser Beitrag, Ergebnisse und der entstandene Data-Copliot entstammen der Bachelorarbeit und Praxisphase von Alexander Schellenberg, in Zusammenarbeit mit viadee und FH Münster.
Warum ist die Integration eigener Daten sinnvoll?
Im Alltag sind KI-Tools eine enorme Erleichterung. Allerdings stoßen sie oft an ihre Grenzen, wenn es um spezifische Fragen zu dem eigenen Unternehmen oder seinen eigenen Daten geht. Ein Large Language Model (LLM) kann in diesen Fällen keine korrekten Antworten liefern, es sei denn, es wurde zuvor gezielt mit den relevanten, unternehmensspezifischen Informationen trainiert.

Ein solches Fine-Tuning ist kostspielig und unflexibel. Im Gegensatz dazu bietet der Einsatz der RAG-Technologie eine kostengünstigere, skalierbare und zuverlässigere Lösung. Denn sie ermöglicht einem LLM Zugang zu aktuellen und vertrauenswürdigen Informationen, die das Modell in Antworten und Überlegungen einfließen lassen kann - ganz ohne KI-Training.
Agentenbasierter Microservice
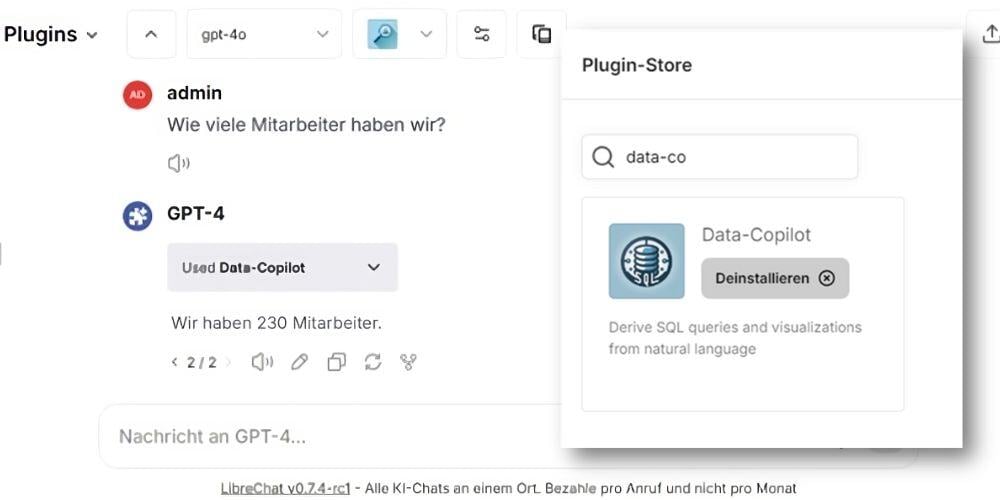
Um unsere interne AI-Chat-Plattform viadeeGPT um Datenbankabfragen zu erweitern, haben wir den Data-Copilot entwickelt und als ein Plattform-Plugin bereitgestellt. Dieses kann durch die viadeeGPT-User jederzeit aktiviert werden, um so Chats zu erweitern. Sollte das LLM den Data-Copilot für die Antwort der Anfrage hinzuziehen wollen, wird automatisch der dafür bereitgestellte FastAPI-Microservice angesprochen.
Im Zentrum dieses Microservices steht ein LLM-Agent, der die auf Azure OpenAI gehosteten Modelle nutzen kann, unterstützt durch das LangChain-Framework. Dieser Agent hat Zugriff auf LangChains SQLDatabaseToolkit, um:
-
Abfragen zu erstellen und auszuführen
-
Abfragesyntax prüfen
-
Tabellenbeschreibungen abzurufen
-
Und viel mehr …
Die Orchestrierung und der Ablauf der verschiedenen, sogenannten Tools liegen in der Verantwortung des Agenten, der durch seinen ReAct (Reasoning & Action)-Charakter in der Lage ist, spezifische Arbeitsaufträge iterativ zu bearbeiten. Er hat dabei die Autonomie, die geeigneten Tools auszuwählen und optimal zu nutzen. So kann er gezielt SQL-Befehle generieren und auf verbundenen Datenbanken ausführen, um präzise Ergebnisse zu liefern.
Agent einarbeiten durch fachlichen Kontext
Die bisherige Funktionalität des SQLDatabaseToolkits ermöglicht dem Agenten, die Namen der Tabellen über die „list tables“-Funktion abzurufen. Dieser Ansatz bietet jedoch nur begrenzte Informationen und erschwert es dem Agenten, die geeignete Tabelle für spezifische SQL-Abfragen zu identifizieren. Ohne zusätzlichen Kontext ist es für den Agenten schwierig zu erkennen, welche Tabelle für eine bestimmte Anfrage relevant ist. Letztendlich kann man den Agenten mit einem sehr schnellen neuen Mitarbeiter vergleichen. Hat dieser jedoch keinen fachlichen Bezug oder Kontext, fehlt ihm das notwendige Wissen, um die richtigen Entscheidungen zu treffen und letztendlich den passenden SQL-Befehl zu generieren.

Um diese Lücke zu schließen, haben wir die „list tables“-Funktion so angepasst, dass neben den Tabellennamen auch Metadaten, wie beispielsweise Beschreibungen, bereitgestellt werden. Diese Metadaten werden aus dem zentral verwalteten Datenkatalog DataHub abgerufen. Darüber hinaus werden annotierte SQL-Beispiele aus dem DataHub dynamisch hinzugezogen. Die Auswahl der Beispiele erfolgt basierend auf der Benutzereingabe, sodass relevante Beispiele als Referenz (Dynamic Few-Shot) dienen.
Sicherheit und Datenschutz
Der Schutz sensibler Daten ist unerlässlich, insbesondere, wenn Unternehmen auf KI-Lösungen setzen. Der Azure OpenAI Service bietet robuste Datenschutzmechanismen, die garantieren, dass die Prompts (Eingaben) und Completions (Outputs) weder für andere Kunden noch zur Verbesserung von OpenAI-Modellen verwendet werden. Der Azure OpenAI Service wird ausschließlich durch Microsoft betrieben.
Die Ausführung von KI generierten SQL-Abfragen birgt ebenfalls Risiken. Um diese Risiken zu minimieren, ist es wichtig, das Rollenkonzept streng zu gestalten. Dies bedeutet, dass die Berechtigungen für die Datenbankverbindung so eng wie möglich auf die Bedürfnisse des jeweiligen Agenten oder Chains beschränkt werden sollten. Dadurch werden die Risiken eines modellgetriebenen Systems verringert, auch wenn sie nicht vollständig eliminiert werden können.
Flexibilität und Anpassungsfähigkeit
Wenn der Agent mit den notwendigen und effektiven Tools ausgestattet ist, können komplexe Arbeitsabläufe wie die SQL-Generierung effizient in Angriff genommen werden. Durch die Kombination von leistungsstarken Modellen und einem durchdachten Toolset wird es möglich, spezifische Anforderungen schnell und präzise zu erfüllen. Dies fördert nicht nur die Produktivität, sondern auch die Agilität in der Datenverarbeitung.

Ein herausragendes Beispiel dafür ist die Fähigkeit des Agents, bestimmte SQL- und Metadaten zu visualisieren, indem er mithilfe selbst generierten Python-Codes eigene Diagramme und Charts erstellt. Obwohl diese Funktion derzeit experimentell ist, verdeutlicht sie das Potenzial für zukünftige Entwicklungen. Dieses Beispiel zeigt, wie der Self-Service-Charakter durch die Anbindung zusätzlicher Funktionen weiter gestärkt werden kann.
Mit dem Data-Copilot wird der Zugang zu unternehmensspezifischen Daten nicht nur einfacher, sondern auch intuitiver. So wird eine Kultur der Selbstständigkeit gefördert, in der jeder Mitarbeiter die Möglichkeit hat, wertvolle Insights aus den Daten zu gewinnen und diese für strategische Entscheidungen zu nutzen.
Wenn Sie sich fragen, wie auch Sie ein agentenbasiertes System in Ihrem Unternehmen implementieren können, schreiben Sie mir gerne eine Mail und ich freue mich auf ein gemeinsames Gespräch. Wir unterstützen Sie gerne von Idee bis Umsetzung.
Haben wir Ihr Interesse geweckt? Melden Sie sich gerne bei uns.

zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



