

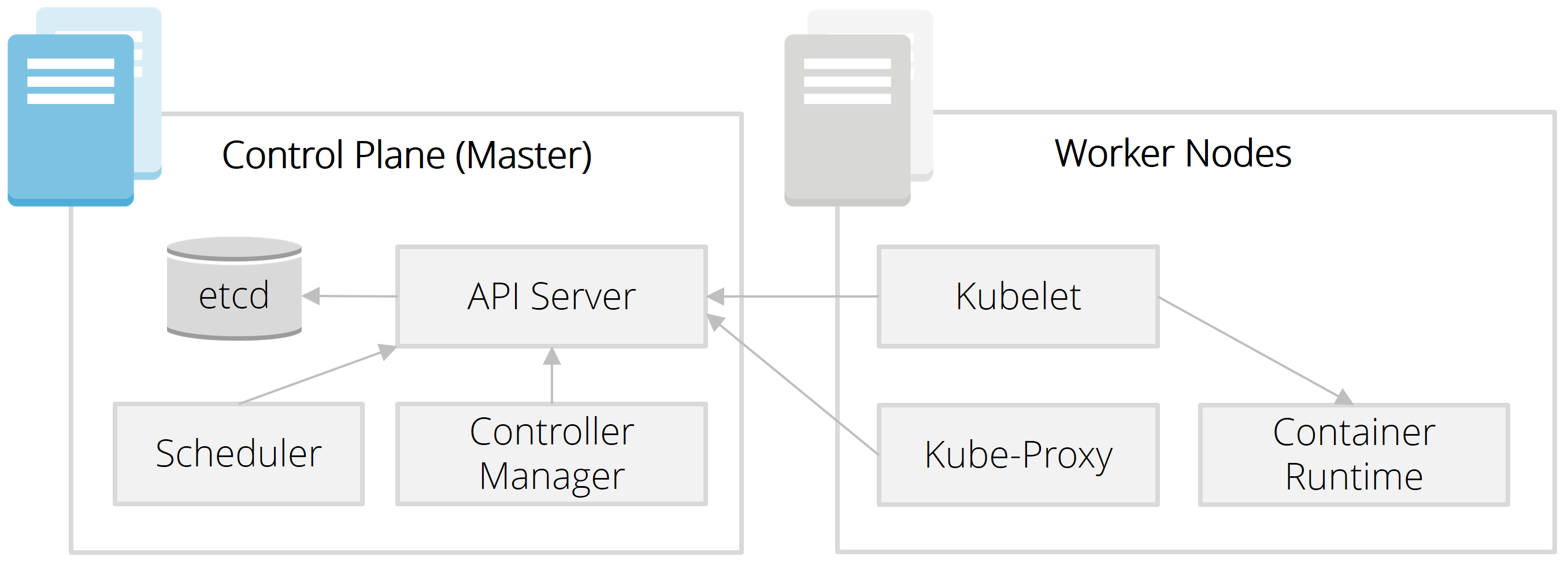
In diesem Blog-Post geht es um den Kubernetes-Scheduler, welcher je nach aktueller Ressourcen-Auslastung neue Pods einem passenden Worker-Node zuordnet. Dafür erweitern wir unser Cluster aus den ersten beiden Blog-Posts (Teil 1, Teil 2), welches aus zwei Worker-Nodes (mit Kubelet) und einem Master-Node (mit API-Server) besteht.
Einordnung in die Architektur
Ein zentrales Feature von Kubernetes ist die Lösung des mathematischen "Bin Packing"-Problems. Dahinter steht die Frage, wie zu startende Pods am besten auf die Server verteilt werden, sodass die Ressourcen ausreichen und weitere Restriktionen (z. B. Node-Redundanz) gegeben sind.
Wenn wir also folgende Pod-Spezifikation (ohne das Attribut "nodeName") an den API-Server schicken, trifft der Scheduler die Entscheidung, ob alle Rahmenbedingungen erfüllt werden können und welchem Node der Pod zugewiesen wird.
Installation des Schedulers auf dem Master-Node
Der Scheduler ist schnell heruntergeladen und auf dem Master-Node gestartet - unter Angabe der IP-Adresse des API-Servers (also dem Master-Node):
wget https://storage.googleapis.com/kubernetes-release/release/v1.13.5/bin/linux/amd64/kube-scheduler chmod +x kube-scheduler
MASTER_IP=$(hostname -i) ./kube-scheduler --master=http://$MASTER_IP:8080
Deployment des Pods
Nun schicken wir die Pod-Spezifikation (ohne Angabe eines Worker-Nodes) an den API-Server.
cat << EOF > $PWD/nginx.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
name: http
protocol: TCP
restartPolicy: Always
EOF
$ kubectl delete -f nginx.yaml --kubeconfig master-kubeconfig.yaml
pod "nginx" deleted
$ kubectl apply -f nginx.yaml --kubeconfig master-kubeconfig.yaml
pod/nginx created
Der Scheduler hat den Pod einem Worker-Node zugeordnet und die entsprechende Kubelet-Komponente auf dem Node hat den dazugehörigen Container gestartet:
$ kubectl get pods --kubeconfig master-kubeconfig.yaml -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx 1/1 Running 0 109s 172.17.0.2 worker2
Dieser Ablauf ist auch in Form von Events nachvollziehbar (erste Zeile):
$ kubectl describe pod nginx --kubeconfig master-kubeconfig.yaml
Name: nginx
Namespace: default
Node: worker2/10.156.0.5
Start Time: Sun, 21 Apr 2019 18:56:21 +0000
Labels: app=nginx
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","kind":"Pod","metadata":{"annotations":{},"labels":{"app":"nginx"},"name":"nginx"
,"namespace":"default"},"spec":{"conta...
Status: Running
IP: 172.17.0.2
...
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 91s default-scheduler Successfully assigned default/nginx to worker2
Normal Pulled 91s kubelet, worker2 Container image "nginx:latest" already present on machine
Normal Created 91s kubelet, worker2 Created container
Normal Started 91s kubelet, worker2 Started container
Deployed man den Pod ein zweites und drittes Mal, wird man sehen, dass die Pods auf beide Worker-Nodes verteilt werden.
Netzwerk
Der NGINX-Webserver ist von der Kommandozeile des eigenen Nodes unter der IP-Adresse des Pods (siehe vorheriges describe-Kommando) aufrufbar:
$ curl http://172.17.0.2/ <html> <head> <title>Welcome to nginx!</title>
Von einem anderen Node aus funktioniert dies jedoch noch nicht. Was in unserem Beispiel-Setup noch fehlt, ist die kube-proxy-Komponente sowie ein Overlay-Netzwerk über alle Nodes hinweg (z.B. Calico, Fannel), sodass eine Cluster-weite Kommunikation zwischen Pods möglich ist.
Ausblick
Auch wenn man als Entwickler häufig nur "Nutzer" der Kubernetes-API ist, so hilft ein Blick hinter die Kulissen, die zugrunde liegenden Mechanismen besser zu verstehen. Wie bereits angedeutet, ist das hier beschriebene Setup lediglich für Lernzwecke gedacht. Für die lokale Entwicklung gibt es Lösungen wie Minikube, die ohne manuellen Aufwand eine lokale Kubernetes-Instanz bereitstellen. Für Test- oder Produktiv-Umgebungen gibt es eine Fülle von Installern, die beim Setup und Update unterstützen. Interessante Randnotiz: Getreu dem Motto "alles ist ein Container" verpacken einige Distributionen (z.B. Rancher RKE) auch alle Kubernetes-Komponenten (API-Server, Scheduler, Kubelet, Kube-Proxy) in Container.
Sie sind Software-Entwickler, DevOps-Engineer oder IT-Architekt und möchten Kubernetes Hands-on im Rahmen eines Seminars oder Workshops kennenlernen? Zögern Sie nicht, uns zu kontaktieren. Mehr zum Thema Cloud.

zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



