

Was bleibt nach den ersten gestarteten Pods auf einem Kubernetes-Cluster? Häufig das Gefühl, dass da viel Magie im Hintergrund unterwegs ist. Mit dieser Blog-Post-Serie wollen wir einen Blick hinter die Kubernetes-API werfen und zeigen, dass die grundlegenden Mechanismen gar nicht so schwer zu durchschauen sind. Dazu werden wir Schritt für Schritt ein eigenes Cluster aus den drei Kern-Komponenten (Kubelet, API-Server und Scheduler) zusammenstecken. Mit den vorbereiteten Code-Snippets können alle Schritte Hands-on nachvollzogen und ein eigenes Cluster aufgebaut werden. Los geht's mit einem Architektur-Überblick und den ersten von Kubelet gestarteten Containern!
Kubernetes (verstehen) lernen
Der Einstieg in das Thema "Kubernetes" ist eigentlich offensichtlich - man muss die Kubernetes-API kennen und bedienen lernen. Aus unserer Projekterfahrung und der Durchführung vieler Kubernetes-Schulungen wissen wir jedoch, dass es sich lohnt, an der einen oder anderen Stelle einen Blick hinter die API zu werfen. Behandelt man Kubernetes nur als "Black Box" mit viel Magie, wird man kaum alle Potenziale nutzen und sich vielleicht sogar über das ein oder andere unerwartete Verhalten wundern.
Wir setzen in dieser Blog-Post-Serie also voraus, dass man schon mal ein Deployment auf einem Kubernetes-Cluster durchgeführt hat und die grundlegenden Konzepte (z. B. Pods) und Werkzeuge (z.B. kubectl) kennt. Aufbauend auf den ersten Erfahrungen als "Anwender" und "Nutzer" von Kubernetes wollen wir in den folgenden Blog-Posts "Kubernetes entmystifizieren" und damit auch die Hürde senken, sich mit dem Technologie-Stack tiefer auseinanderzusetzen.
- Teil 1: Einstieg, Architektur und Kubelet
- Teil 2: API-Server
- Teil 3: Scheduler
Architektur
Ein Kubernetes-Cluster besteht aus Servern mit zwei verschiedenen Rollen. Die Master-Nodes bilden die sog. Control Plane und steuern das gesamte System. Die eigentlichen Applikationen laufen auf Worker-Nodes. Von beiden Rollen werden zur Ausfallsicherheit und Skalierung typischerweise mehrere Instanzen vorgehalten.
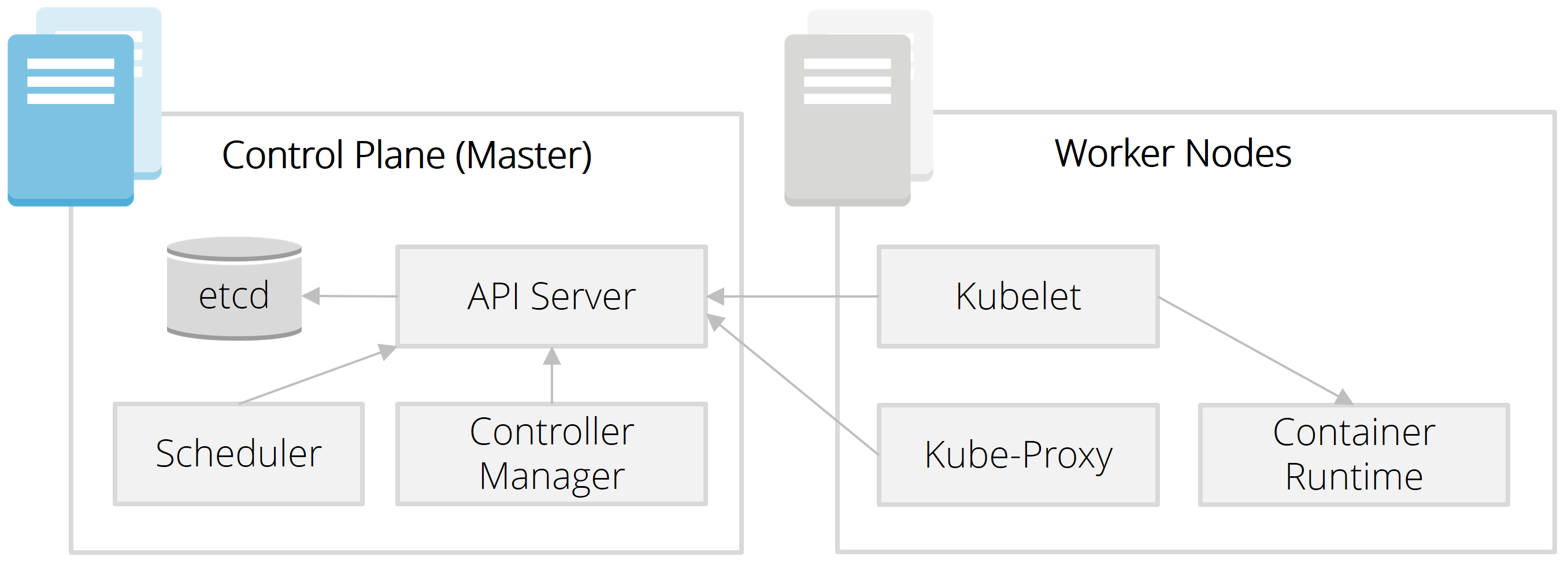
Was passiert nun, wenn man über "kubectl" ein Deployment auslöst? Zunächst landet dieser Request beim API-Server, über den auch die gesamte Kommunikation der anderen Control-Plane-Komponenten läuft. Auf Basis der angefragten und vorhandenen Ressourcen trifft der Scheduler dann die Entscheidung, auf welchen Worker-Nodes die entsprechenden Container zu starten sind.
Auf jedem Worker-Node läuft das sog. Kubelet. Diese dezentrale Komponente ist ausschließlich für die Container auf dem jeweiligen Worker-Node zuständig und stellt sicher, dass der vom API-Server übermittelte Zielzustand erreicht wird. Weist der Scheduler also einem bestimmten Worker-Node zwei Instanzen zu, dann landet dieser neue Zielzustand bei seinem Kubelet. Dieses startet daraufhin über die Container Runtime (z. B. Docker) die zwei angefragten Container bzw. Pods. Durch regelmäßige Health-Checks wird von der Control-Plane sichergestellt, dass dieser Zielzustand dauerhaft erfüllt bleibt - auch beim Absturz von einzelnen Containern oder dem Ausfall ganzer Nodes.
Natürlich müssen Container auch über Worker-Nodes hinweg miteinander kommunizieren können. Kube-Proxy sowie ein darunterliegendes Overlay-Netzwerk (z. B. Calico, Flannel) sorgt dafür, dass dies Cluster-weit möglich ist, ohne dass es eine Rolle spielt, auf welchem Worker-Node ein Container gerade läuft.
Und zu guter Letzt: Der Controller Manager übernimmt übergreifende Koordinationsaufgaben (z. B. beim Ausfall eines Worker-Nodes) und in dem verteilten etcd-Datastore werden alle Zustände und Ressourcen eines Clusters gespeichert.
Ein Cluster für Lernzwecke
Ziel dieser Blog-Post Serie ist es, die verschiedenen Kubernetes-Komponenten "erlebbar" zu machen. Wir werden daher Schritt für Schritt ein kleines Cluster zu Lernzwecken aufsetzen.
Wichtig: Der Fokus liegt dabei auf einem didaktisch einfachen Setup und verzichtet bewusst auf weiterführende Themen wie Security. Dieser Installationsweg wird daher auf keinen Fall für zentrale Test- oder Produktionsumgebungen empfohlen.
Wir verwenden im Folgenden virtuelle Maschinen in der Google Cloud. Alle Schritte können aber auch auf lokalen virtuellen Maschinen nachvollzogen werden (z. B. mit Virtual Box). In der finalen Ausbaustufe zum Ende der Serie werden es zwei Worker-Nodes und ein Master-Node sein:
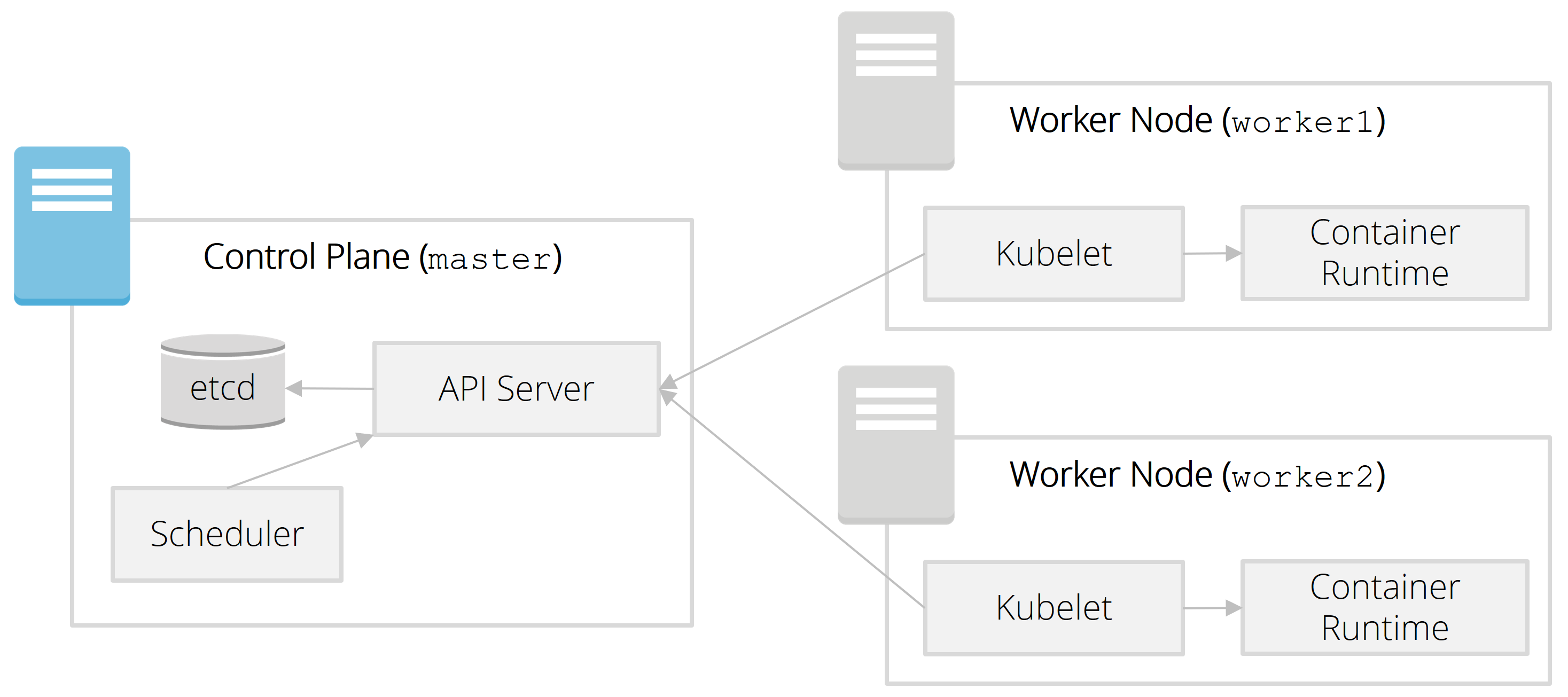
Der erste Worker-Node
Falls Sie gcloud noch nicht installiert haben, können Sie das hier nachholen und sich anschließend mit "gcloud init" gegenüber der Google Cloud authentifizieren.
Im ersten Schritt brauchen wir eine virtuelle Maschine:
PROJECT="k8s-blogpost"
ZONE="europe-west3-c"
gcloud compute instances create worker1 \
--project=$PROJECT \
--zone=$ZONE \
--machine-type=n1-standard-2 \
--scopes=https://www.googleapis.com/auth/devstorage.read_only,https://www.googleapis.com/auth/logging.write,https://www.googleapis.com/auth/monitoring.write,https://www.googleapis.com/auth/servicecontrol,https://www.googleapis.com/auth/service.management.readonly,https://www.googleapis.com/auth/trace.append \
--image=ubuntu-minimal-1804-bionic-v20190403 \
--image-project=ubuntu-os-cloud
Wenn Sie lokal arbeiten, können Sie einfach eine neue virtuelle Maschine anlegen und darauf z. B. Ubuntu installieren.
Auch wenn Kubernetes verschiedene Container-Runtimes unterstützt, ist Docker am weitesten verbreitet und daher auch Grundlage für unser Setup. Im nächsten Schritt verbinden wir uns per SSH mit der virtuellen Maschine und installieren Docker gemäß der offiziellen Anleitung:
# connect via ssh or use web shell gcloud compute --project $PROJECT ssh --zone $ZONE "worker1" # install docker sudo apt-get update sudo apt-get install apt-transport-https ca-certificates curl software-properties-common jq curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add - sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" sudo apt-get update sudo apt install docker-ce=18.06.3~ce~3-0~ubuntu
Damit sind die Voraussetzungen zunächst geschaffen.
Pods
In Kubernetes definiert man nicht Container, sondern Pods. Ein Pod besteht aus 1-n Containern, die sich einige Ressourcen wie Volumes oder Port-Bereiche teilen. In unserem Beispiel kommen wir mit einem Container aus und wollen einen NGINX-Webserver starten. Das folgende Manifest beschreibt den dafür notwendigen Pod:
Die drei relevanten Attribute sind:
- name: Name des Pods
- image: Bezeichnung des Docker-Images, auf dessen Basis der Container instantiiert wird
- containerPort: Gibt an, dass der Webserver auf Port 80 erreichbar ist
Kubelet
Zunächst brauchen wir noch die Kubelet-Binary, welche wir herunterladen und ausführbar machen:
wget https://storage.googleapis.com/kubernetes-release/release/v1.13.5/bin/linux/amd64/kubelet chmod +x kubelet
Kubelet unterstützt vier Wege zur Übermittlung des o. g. Pod-Manifests:
- Ablage der Manifest-Dateien in einem Ordner, der regelmäßig eingelesen wird
- Bereitstellung eines HTTP-Endpunkts, welcher regelmäßig abgefragt wird
- HTTP-Requests an den Kubelet-eigenen Webserver
- Kommunikation mit dem Kubernetes API-Server
Natürlich ist die letzte Option unser Ziel, aber wir starten zunächst mit der Angabe eines Verzeichnisses, aus welchem Kubelet in der Standardkonfiguration alle 20 Sekunden die Pod-Spezifikationen einliest. Der folgende Befehl startet den Kubelet-Dienst:
mkdir kubelet-manifests sudo ./kubelet --pod-manifest-path=$PWD/kubelet-manifests
Kleine Randnotiz: Im Log wird regelmäßig folgende Meldung erscheinen, die wir aber für das Beispiel-Setup hier erstmal ignorieren können:
summary_sys_containers.go:47] Failed to get system container stats for "/user.slice/user-1001.slice/session-1.scope": failed to get cgroup stats for "/user.slice/user-1001.slice/session-1.scope": failed to get container info for "/user.slice/user-1001.slice/session-1.scope": unknown container "/user.slice/user-1001.slice/session-1.scope"
Technischer Hintergrund: Kubelet läuft in der "falschen" cgroup und kann daher keine Metriken für CPU und Memory-Verbrauch bereitstellen. Korrekterweise würde man Kubelet per systemd starten und dort die Parameter MemoryAccounting und CPUAccounting auf true setzen. Um die Dinge hier einfach zu halten, sparen wir uns das für den Moment.
Weiter geht's! Um parallel nun eine YAML-Datei anzulegen und den ersten Container zu starten, am besten ein zweites Shell-Fenster öffnen:
cat << EOF > $PWD/kubelet-manifests/nginx.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
name: http
protocol: TCP
restartPolicy: Always
EOF
Einen Moment warten und das Ergebnis kontrollieren:
$ sudo docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 88a17a1c021e nginx "nginx -g 'daemon of…" 39 seconds ago Up 38 seconds k8s_nginx_nginx-worker1_default_0f29a53c07f00b4de1a22df6d52466f2_0 218c0ca200ce k8s.gcr.io/pause:3.1 "/pause" 45 seconds ago Up 43 seconds k8s_POD_nginx-worker1_default_0f29a53c07f00b4de1a22df6d52466f2_0
Check! Kubelet hat einen Container auf Basis der Pod-Spezifikation erzeugt. Der zweite Container mit dem "/pause" Command ist ein Infrastruktur-Container, in dem Kubelet alle Ressourcen des Pods verwaltet (z.B. die IP-Adresse, die sich potenziell mehrere Container eines Pods teilen). Um zu verifizieren, dass der Webserver auch läuft, ermitteln wir die IP-Adresse des Pods und rufen diese von der Shell des Worker-Nodes aus auf.
$ sudo docker inspect --format '{{ .NetworkSettings.IPAddress }}' 218c0ca200ce
172.17.0.2
$ curl http://172.17.0.2
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title> ...
Was passiert, wenn man den Container löscht?
$ sudo docker kill 88a17a1c021e 88a17a1c021e $ sudo docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES fab787e8a3ea 27a188018e18 "nginx -g 'daemon of…" 5 seconds ago Up 5 seconds k8s_nginx_nginx-worker1_default_0f29a53c07f00b4de1a22df6d52466f2_1 218c0ca200ce k8s.gcr.io/pause:3.1 "/pause" 12 minutes ago Up 12 minutes k8s_POD_nginx-worker1_default_0f29a53c07f00b4de1a22df6d52466f2_0
Ein neuer Container wird von Kubelet erzeugt, damit der Zielzustand wieder erreicht ist.
Kubelet-API
Kubelet bringt übrigens auch selbst eine eigene REST-API mit, auf der man den aktuellen Zustand der durch Kubelet verwalteten Pods abfragen kann (Erinnerung: Kubelet kümmert sich nur um Pods auf der eigenen Maschine!).
$ curl http://localhost:10255/pods | jq .
Wie geht es weiter?
Wie bereits angedeutet, ist das Ablegen von YAML-Dateien nicht unsere anvisierte Ausbaustufe. Deshalb kommt im nächsten Blog-Post der API-Server dazu, welcher die Ressource-Definitionen entgegennimmt und an den Kubelet-Dienst weiterleitet.
Sie sind Software-Entwickler, DevOps-Engineer oder IT-Architekt und möchten Kubernetes Hands-On im Rahmen eines Seminars oder Workshops kennenlernen? Zögern Sie nicht, uns zu kontaktieren.


zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



