
Von September 2019 bis Februar 2020 hatte ich Gelegenheit, eine Gruppe von Studierenden der TH Köln, Campus Gummersbach in ihrem Business-Intelligence-Praxisprojekt zu unterstützen. Die Studierenden nutzten das am Lehrstuhl von Prof. Hartmut Westenberger entwickelte BI-Testlabor, um eine prototypische Streaming-Anwendung zur Auswertung von Echtzeitdaten zu erstellen. Die Anwendung kann als Bestandteil einer Lambda-Architektur verstanden werden und basiert auf Kafka, dem verteilten OpenSource-Messaging-Werkzeug von Apache.
In einem Praxisprojekt an der TH Köln, Campus Gummersbach in Zusammenarbeit mit Prof. Hartmut Westenberger wurden Einsatzmöglichkeiten von Apache Kafka im Speed Layer einer Lambda-Architektur untersucht. Ein klassisches Data Warehouse wurde damit um Echtzeit-Auswertungen ergänzt. Als Vertreter der viadee konnte ich den Studierenden einige praktisch relevante Fragestellungen und Ideen für Use Cases mitgeben und im Gegenzug einiges über Kafka lernen, was viel Spaß gemacht hat. Im Folgenden möchte ich die entstandene Architektur im Überblick vorstellen.

Datenquellen
Das BI-Testlabor stellt simulierte Daten eines Call-Centers bereit. Dazu wird die Tecnomatix Plant Simulation Software von Siemens genutzt, mit der einige typische Prozesse in einem Call-Center modelliert und simuliert werden. Dabei entstehen beispielsweise Daten, die je Anruf im Call-Center angeben, wie lange er gedauert hat, welcher Mitarbeiter des Call-Centers den Anruf entgegengenommen bzw. an jemanden weitergegeben hat, welches Thema (Sparten einer fiktiven Versicherung) behandelt wurde, ob der Anruf abgebrochen wurde oder welche Kundenzufriedenheit bei einer Rückfrage am Ende des Anrufs angegeben wurde.
Anwendungsfall
In der Gruppe wurden verschiedene Anwendungsfälle für Echtzeit-Auswertungen auf Call-Center-Daten diskutiert. Schließlich wurde beschlossen, KPIs (Key Performance Indicators) zu entwickeln, die über Folgendes Auskunft geben:
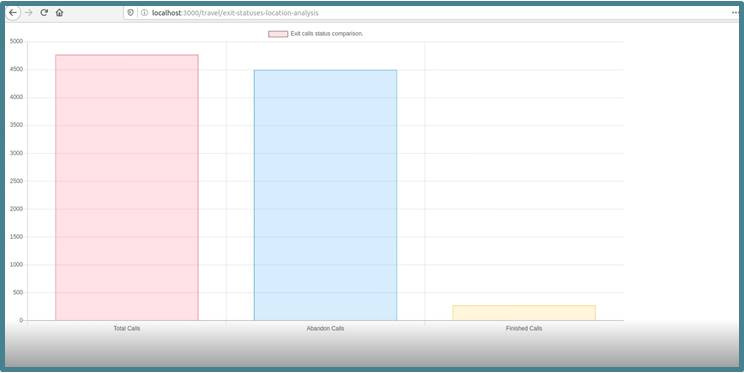
- Wie viele Abbrüche von Anrufen gab es in der letzten halben Stunde? Ist diese Zahl zu hoch, könnte dies auf eine technische Störung hindeuten, die umgehend repariert werden sollte.
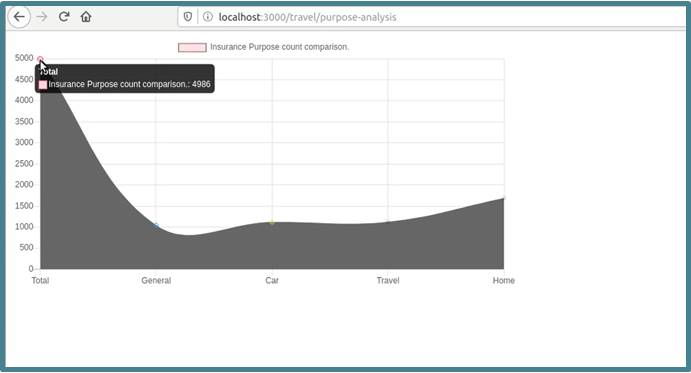
- Wie verteilen sich die Anrufe der letzten halben Stunde auf die Themen? Falls ein Thema stark frequentiert wird, kann es notwendig werden, dass der Call-Center-Betreiber kurzfristig zusätzliche Mitarbeiter einsetzt, die sich mit dem Thema auskennen, um das Anrufaufkommen zu bewältigen.
Neben Reports zur Visualisierung dieser Kennzahlen (siehe Bilder unten) wurde auch ein Alarmierungs-Mechanismus geschaffen, der den Call-Center-Betreiber per E-Mail informiert, wenn eine dieser KPIs einen bestimmten Schwellwert überschreitet.
Bestehende DWH-Architektur
In vorigen Praxisgruppen am Lehrstuhl von Prof. Westenberger wurde auf Basis der o. g. Datenquellen ein SAS-basiertes Data Warehouse mit jeweils einer Sternschema- und einer Data Vault-Architektur erstellt. Diese beruhen auf batch-basierten ETL-Verarbeitungen, die beispielsweise täglich ablaufen und das DWH aktualisieren.
Erweiterung um Echtzeit-Analysen
In diesem Projekt ging es darum, das bestehende DWH um eine Echtzeit-Komponente zu ergänzen. Dazu wurde je Datenquelle ein "Producer" implementiert, der die Daten an das Messaging-System Kafka schickt. Kafka dient als verteilter, hoch skalierbarer Puffer, um große Datenmengen in kurzer Zeit speichern zu können, auch wenn die weitere Verarbeitung der Daten (entweder aufgrund von Störungen oder aus Performance-Gründen) langsamer erfolgt als die Datenerzeugung.
In Kafka werden Daten in Topics organisiert. In diesem Fall wurde ein Topic je Datenquelle gewählt, denn innerhalb eines Topics verwendet man möglichst einheitliche Datenstrukturen. Zur Skalierung kann ein Topic in Partitionen unterteilt werden, sodass jede Partition einen Teil der Daten aufnimmt. Zur Partitionierung können etwa bestimmte Key-Attribute der Daten verwendet werden, sodass je Ausprägung der Attribute eine Partition entsteht. In diesem Prototypen wurde jedoch nur eine Partition je Topic benötigt.
Zur Auswertung wurde ein Consumer implementiert, der in bestimmten (konfigurierbaren) Intervallen, etwa jede Minute, Daten aus den Topics abfragt und sie in einer lokalen Datenbank zwischenspeichert. Diese Datenbank enthält immer nur die Daten der letzten x Zeitintervalle, um klein und schnell auswertbar zu bleiben. Auf dieser Datenbank wurde ein einfaches Reporting umgesetzt, um die fachlichen Auswertungen in Quasi-Echtzeit anzuzeigen. Bei jedem Refresh auf einem Report werden die neuesten Daten integriert (siehe Bilder). Die Reports enthalten die o. g. KPIs.
Fazit
Nachdem in vorigen Praxisgruppen der Batch Layer einer Lambda-Architektur erstellt wurde, kann sich das BI-Testlabor von Prof. Westenberger nun auch mit einer Echtzeit-Komponente rühmen, also mit dem Speed Layer der Lambda-Architektur. Vielleicht schafft es die nächste Praxisgruppe, beide Komponenten im Serving Layer zu verbinden und die Architektur somit zu vervollständigen!
Die Studierenden haben mit viel Elan und technischem Sachverstand einen funktionierenden Prototypen geschaffen, der Kafka zur Entkopplung von Datenproduzenten und -konsumenten nutzt und Echtzeitauswertungen ermöglicht. Es hat viel Spaß gemacht, dabei mitzuwirken und die eine oder andere Idee aus der Praxis einzubringen!
Autor
 Dr. Timm Euler war bis September 2020 Senior-Berater bei der viadee IT-Unternehmensberatung und Leiter des F&E-Bereichs Business Intelligence.
Dr. Timm Euler war bis September 2020 Senior-Berater bei der viadee IT-Unternehmensberatung und Leiter des F&E-Bereichs Business Intelligence.
Er interessiert sich für alles rund um Big Data, Data Warehousing und Data Mining.
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



