

In Deutschland werden mehr als 12% aller im Lebensmitteleinzelhandel verkauften Produkte im Rahmen einer Werbekampagne verkauft. Die Wirksamkeit einer Werbekampagne zu bewerten erweist sich jedoch als Herausforderung: Was wäre ohne Werbung gewesen? Wir erläutern einen Lösungsansatz.
Werbewirksamkeit bewerten
Bevor die Frage beantwortet werden kann, sollte man sich zunächst Gedanken machen, welche Faktoren Einfluss auf die Werbewirksamkeit haben und was die zu erwartenden Störfaktoren sind:
- Wie viel hätte man verkauft, wenn es keine Werbung gegeben hätte?
- Werden die zusätzlichen Produkte, die während einer Promotion verkauft wurden, in späteren Perioden fehlen?
- Wie beeinflussen cross-selling Effekte die Werbewirksamkeit?
- Gibt es Kannibalisierungseffekte, welche die Werbewirksamkeit negativ beeinflussen?
Kümmern wir uns zunächst um die ersten beiden Fragestellungen. Für Supermärkte kann so eine Prognose dabei helfen, strategische Entscheidungen zu treffen. Weiß ein Supermarkt zum Beispiel wie hoch die Absatzsteigerung einer bestimmten Werbeaktion ist, kann dieser eine gewinnmaximierende Preissenkung dazu berechnen – oder eine Werbeaktion in Frage stellen.
Unser Lösungsansatz ist, die Basisverkäufe (baseline sales) innerhalb eines mit Hilfe von Machine Learning-Algorithmen vorherzusagen und diesen Wert von der tatsächlich während der Promotion verkauften Menge abzuziehen. Das Vorgehen entspricht einer Counterfactual Explanation, aus dem Bereich Explainable AI.
Rechenweg mit alternativer Realität
Der Begriff baseline sale wird verwendet, um die Menge eines verkauften Produkts zu beschreiben, wenn es keine Werbeaktion gegeben hätte. Die durch eine Werbeaktion gesteigerte Absatzmenge wird in der Literatur auch als promotion bump bezeichnet. Ermittelt man die baseline sales während des Werbezeitraums und subtrahiert diese vom promotion bump, erhält man die durch die Promotion zusätzlich verkauften Produkte.
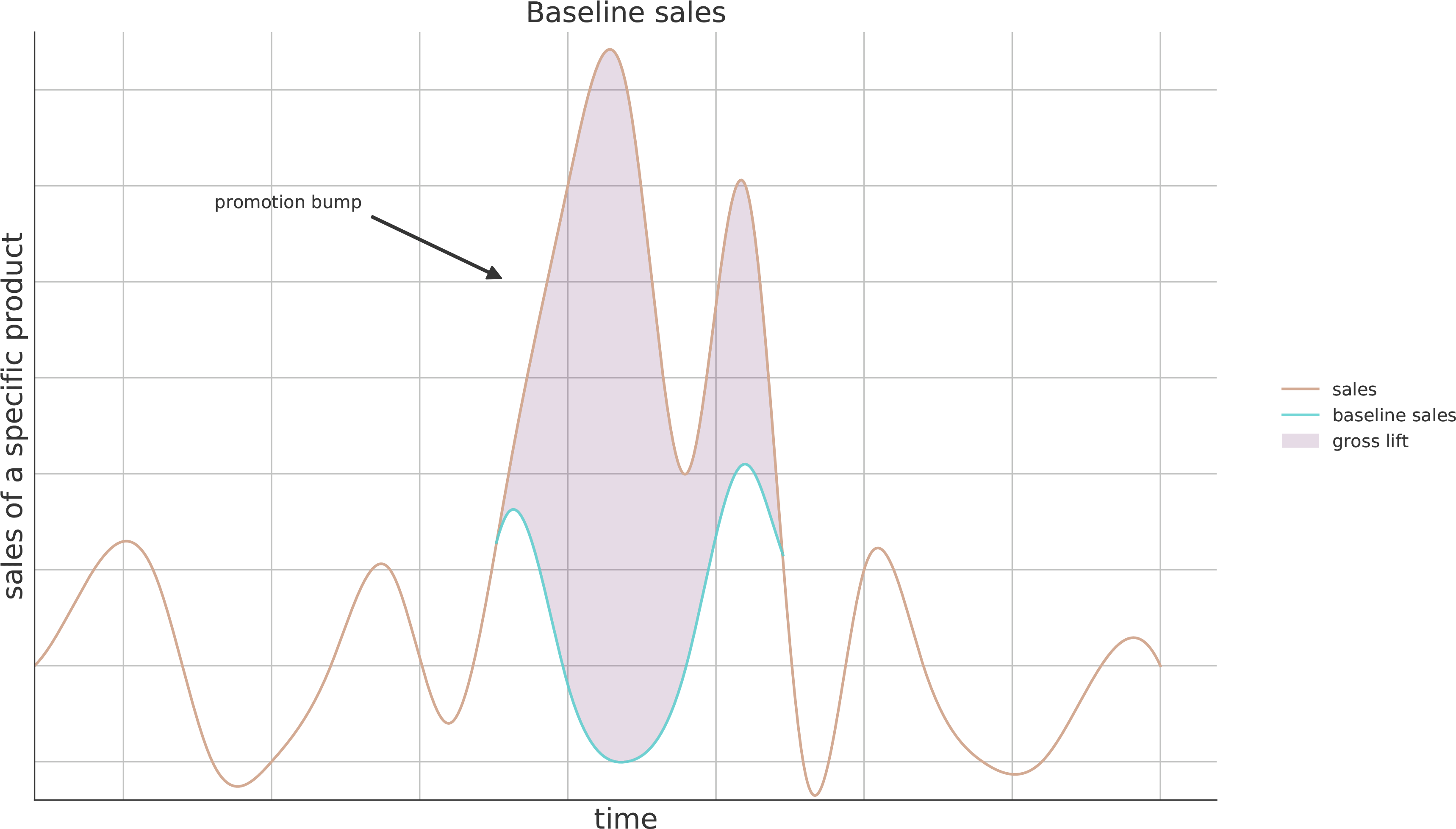
Voraussetzung dafür ist ein Machine Learning-Modell mit allen verfügbaren Absatzzahlen, die außerhalb eines Werbezeitraums liegen, zu trainieren. Wenn ein Machine Learning Algorithmus ausschließlich Datensätze außerhalb von Werbekampagnen kennt, wird die Vorhersage des trainierten Modells ebenfalls in der gleichen, realistischen Größenordnung liegen. Die Vorhersage der Absatzmenge hat also den Charakter von baseline sales.
Stockpiling berücksichtigen
Hat man den Mehrverkauf bedingt durch eine Werbeaktion berechnet, muss berücksichtigt werden, ob die zusätzlichen verkauften Produkte in späteren Perioden vielleicht fehlen. Der beschriebene Effekt wird in der Theorie Bevorratungseffekt genannt (engl. Stockpiling) und wird durch Kund:innen ausgelöst, die im Rahmen einer Werbekampagne eine besonders große Menge eines Produkts kaufen, nur um einen Großteil der gekauften Produkte zu lagern.
Man kann davon ausgehen, dass der Bevorratungseffekt nicht bei jedem Produkt gleich lang ist. Lebensmittel mit einem Haltbarkeitsdatum werden sicherlich einen kürzeren Bevorratungseffekt vorweisen als Konserven. Eine Möglichkeit, um den durchschnittlichen Zeitraum der Bevorratung abzuschätzen, ist das explizite Betrachten von bspw. über Payback-Karten identifizierbare Kunden und Kundinnen: Hier gibt es den Vorteil, dass deren (hoffentlich) regelmäßige Einkäufe über eine eindeutige Kundenummer verfolgt werden können. Es bietet sich daher an zu überprüfen, wie lange sie nach einer Werbekampagne die (möglicherweise bevorratete) Produktkategorie nicht einkaufen. Dieser Zeitraum kann als der Bevorratungszeitraum angesehen werden. Im Nachfolgenden kann gemessen werden, inwiefern der durchschnittliche Absatz während des Bevorratungszeitraums vom Durchschnitt abweicht.
Experiment mit echten Abverkaufsdaten
Anhand eines mehrjährigen Abverkaufs-Datensatzes eines großen Deutschen Supermarktes und mit Produkten aus mehreren Kategorien haben wir diese Ideen erprobt. Die Ergebnisse sind grob zusammengefasst wie folgt:
- Der Ansatz funktioniert für Schnelldreher-Artikel sehr gut. Hier können auch Tage mit der Absatzmenge Null zuverlässig genug interpretiert werden, während bei langsam drehenden Artikeln das Fehlen von Nachfrage und eine out-of-stock-Situation nicht unterscheidbar sind.
- Überraschend war, wie gut auch einfache Zeitreihenverfahren hier in einem Benchmark mit verschiedenen Machine-Learning-Verfahren abschneiden. Sie können eine gute Grundlage bilden. Einfache Machine-Learning-Verfahren erklären dann die Residuen, die sich nicht durch schlichte Saisonalität erklären lassen. Das hat zwei Vorteile: Wir erhalten uns die Nachvollziehbarkeit und erreichen eine angemessene Skalierbarkeit für Big-Data-Anwendungsfälle wie diesen.
- Es zeigt sich auch sehr überraschend, dass die Bevorratungseffekte entweder so gering sind, dass sie nicht zuverlässig messbar sind oder unsere Methodik dafür nicht sensitiv genug ist.
Haben Sie vergleichbare Fragen zur Wirksamkeit von Maßnahmen? Wir machen uns gern mit Ihnen zusammen auf die Suche nach den KI-Potenzialen.
Dieser Beitrag basiert auf der Bachelor-Thesis von Lutz S. (2020), betreut durch Prof. Michael Bücker an der FH-Münster.
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



