

Durch die Einführung der DSGVO und das Blockieren von Third-Party-Cookies aller gängigen Browser wird der Datenschutz beim Besuch einer Webseite in den Vordergrund gestellt. Cookie-Banner, die nicht nur beim alltäglichen Surfen stören, verzerren auch Analysen des Nutzungsverhaltens. Mit gängigen Werkzeugen optimiere ich meine Website auf unvorsichtige Nutzer:innen hin, alle anderen blende ich aus. Serverseitige Log-Dateien hingegen werden für jeden Nutzer erzeugt und brauchen keine Cookies und Javascripts. So steht auch beim Nutzer-Tracking der Datenschutz im Zentrum. Wie lassen sich aus diesen Daten mit modernen Verfahren brauchbare Rückschlüsse ziehen?
Problemstellung
Cookies von Drittanbietern, also solche, die nicht von der eigentlichen Webseite selbst, sondern von auf der Webseite eingebundenen Analysetools wie Google Analytics oder Hubspot stammen, werden zunehmend blockiert. Browser-Erweiterungen, welche nicht nur Werbung, sondern auch gleich ganze Tracking-Tools und die Ausführung von Javascripts blockieren, werden millionenfach installiert. Es stellt sich die Frage, welche Aussagekraft die gängigen Analyseprogramme überhaupt noch liefern können, um sinnvoll begründete Entscheidungen zur Gestaltung von Webseiten zu treffen.
Die DSGVO ist nicht das Ende des Trackings per se. Auch wenn Third-Party-Cookies blockiert bzw. die Laufzeit eingeschränkt wird, so gibt es beispielsweise für den Platzhirsch (Google Analytics) schon heute die Möglichkeit, ein serverseitiges Tracking zu aktivieren. In diesem Fall wird das Cookie dann nicht mehr durch das Google Analytics Script gesetzt, sondern von der Webseite selber. Über eine Subdomain können die Daten so an Google weitergesendet werden, dass ein Blockieren der Cookies bzw. Scripte keinen Effekt auf das Tracking an sich haben wird. Dies ändert jedoch nichts an der Tatsache, dass beim Besuch der Webseite dem Cookie ausdrücklich zugestimmt werden muss, damit beispielsweise Google mir später eine Analyse meiner Webseite anbieten kann und ich daraus Optimierungspotential ziehen kann. Es gibt auch noch weitaus komplexere Ansätze, die versuchen über eine Kohorten-Zuordnung im Browser eine Zielgruppen-Orientierung zu erreichen.
Erkenntnis:
Die Analyse von Nutzungsdaten auf Basis von Browser-Daten ist zu einem technologischen Wettrüsten mit schnellen Zyklen geworden. Als Kollateralschaden wird es für alle Betreiber von Internet-Angeboten schwerer, zu verstehen, was Menschen mit ihren Angeboten tun.
Mit diesem Beitrag möchten wir eine einfach Alternative vorstellen, deren Grundlage etwas in Vergessenheit geraten sein könnte: die Server Logfiles. Wird ein Inhalt ausgeliefert, entsteht dort immer genau ein Protokolleintrag. Diese Protokolle sind ein Single Point of Truth und völlig unabhängig vom o. g. Wettrüsten.
Diese Daten sind ohnehin in der Regel bereits vorhanden. Bekommen wir so die Hoheit über die Nutzungsdaten zurück?
Um dieser Fragestellung auf den Grund zu gehen, haben wir die Server Logs der viadee Webseite betrachtet und versucht, mit modernen Data Science-Werkzeugen und Process Mining-Verfahren Erkenntnisse zu erlangen. An dieser Stelle sei angemerkt, dass die einzelnen Nutzer:innen durch einen nicht invertierbaren Hash identifiziert werden, welcher aus der IP-Adresse ermittelt wird. Somit findet die Verarbeitung der Daten ohne jeden weiteren Personenbezug statt. Die Lösung ist daher minimalinvasiv und sehr datensparsam.
Beispiel: Wie unterscheiden sich Log-basierte Ergebnisse von denen von Google Analytics und Hubspot?
Beispielhaft haben wir für einen kleinen Zeitraum einige der Seiten auf viadee.de und deren Tracking-Tools miteinander verglichen, um Unterschiede aufzeigen zu können.
Die untenstehende Grafik veranschaulicht die jeweiligen Klickzahlen auf einzelnen Seiten pro Tracking-Tool.
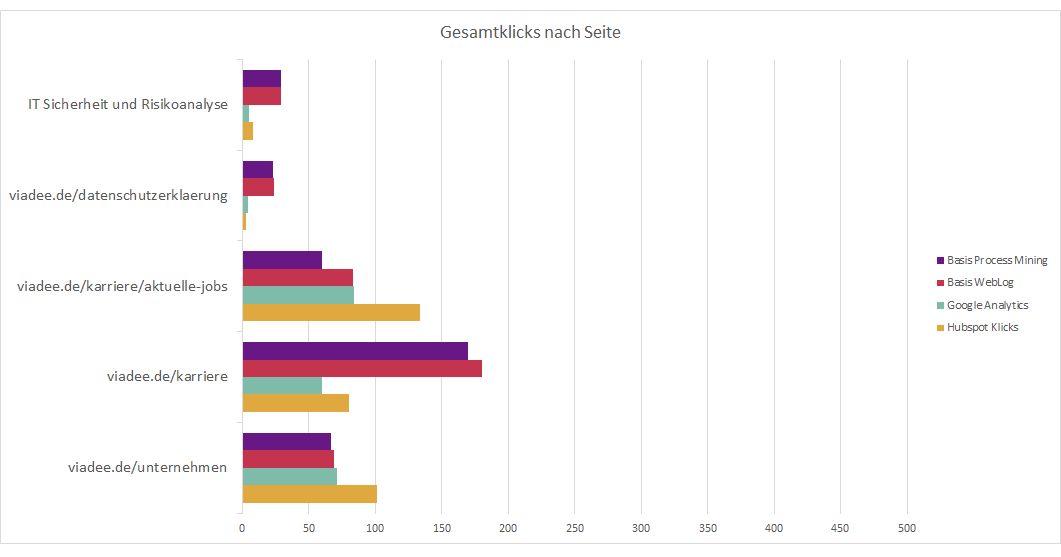
- Die roten Balken haben die grob gefilterten Logs als Basis. Bspw. entfernen wir unsere eigenen IPs und die Zugriffe von Suchmaschinen.
- Die lila Balken haben die für ein Process Mining aufbereiteten Logs als Basis. Dies ist letztlich auch ein Filter: Hier betrachten wir nur Nutzungsprozesse, die mehr als einen Schritt haben, wo Nutzer:innen also mehr als eine URL aufgerufen haben.
- Die orangenen Balken sind die Ergebnisse unseres Marketing-Tools Hubspot. Dies ist ein verbreitetes Werkzeug, das auf ein Cookie- / Javascript-basiertes Tracking setzt.
- Die grünen Balken sind die Ergebnisse von Google Analytics, welches ebenfalls mittels Cookies / Javascript arbeitet.
Wie sind die Zahlen zu interpretieren? In der Tendenz sind die Werte nah beieinander, es gibt aber Differenzen. Den Einzelfall lohnt es sich anzuschauen.
- Die Log-basierten Zahlen sind teilweise deutlich höher als die Zahlen von Hubspot. Finden Sie eine Gemeinsamkeit? Besonders bei Seiten, welche sich mit Datenschutz und IT-Sicherheit beschäftigen, zeigt sich deutlich, dass deutlich mehr Klicks durch die Logfiles registriert werden, als es bei Hubspot der Fall ist. Auch auf unsere Karriere-Seite trifft das zu. Eine plausible Erklärung dafür ist, dass die Nutzer:innen dieser Webseiten tendenziell ein höheres Schutzniveau haben als die durchschnittliche Nutzer:in. Sie lehnen Cookies ggf. automatisch ab oder sogar die Ausführung von Javascripts.
- Eine weitere Möglichkeit ist, dass es einen Bot gibt, der sich zwar nicht als solcher ausgibt, allerdings dennoch regelmäßig unsere Karriere-Seite scannt, um beispielsweise neue Anzeigen zu entdecken und diese auf anderen Plattformen auszuspielen. Bei näherer Betrachtung der Rohdaten konnten wir feststellen, dass die letztere Variante zutrifft.
- Manchmal sind die Hubspot-Zahlen höher. Hier können Caches eine Erklärung sein, die ein erneutes Ansehen einer Seite ohne Protokoll-Eintrag auf dem Server ermöglichen. Gerade für unsere Unternehmensvorstellung ist das plausibel – die Seite ist stabil und gut für Caching geeignet. Aber nicht alle Fälle sind so einfach zu deuten.
Erkenntnis:
Security-Kundige sind unsichtbarer als andere - ansprechen möchten wir sie trotzdem!
Mit systematischen Verzerrungen wie diesen lohnt es sich, detaillierter in die Daten zu schauen.
Beispiel: Eine Prozess-Perspektive auf unsere Stellenanzeigen auf viadee.de
Schauen wir uns das an einem Beispiel an: Nachdem wir die Daten wie oben beschrieben bereinigt und in einem weiteren Schritt grob kategorisiert haben, können wir mithilfe eines geeigneten Process Mining Tools, wie beispielsweise "Apromore", eine Process Discovery durchführen, um über den Tellerrand von einfachen Klick-Zahlen zu schauen.
Ziel ist es dabei aus den vorhandenen Prozessen solche abzuleiten, die besonders häufig auftreten.
Eine Process Map, also die Darstellung der Beziehungen der einzelnen Aktivitäten untereinander, kann schnell unübersichtlich wirken, wenn sie sich auf 100% der Fälle bezieht. Daher ist das unten aufgeführte Beispiel stark gefiltert – auch das ist einfach möglich:
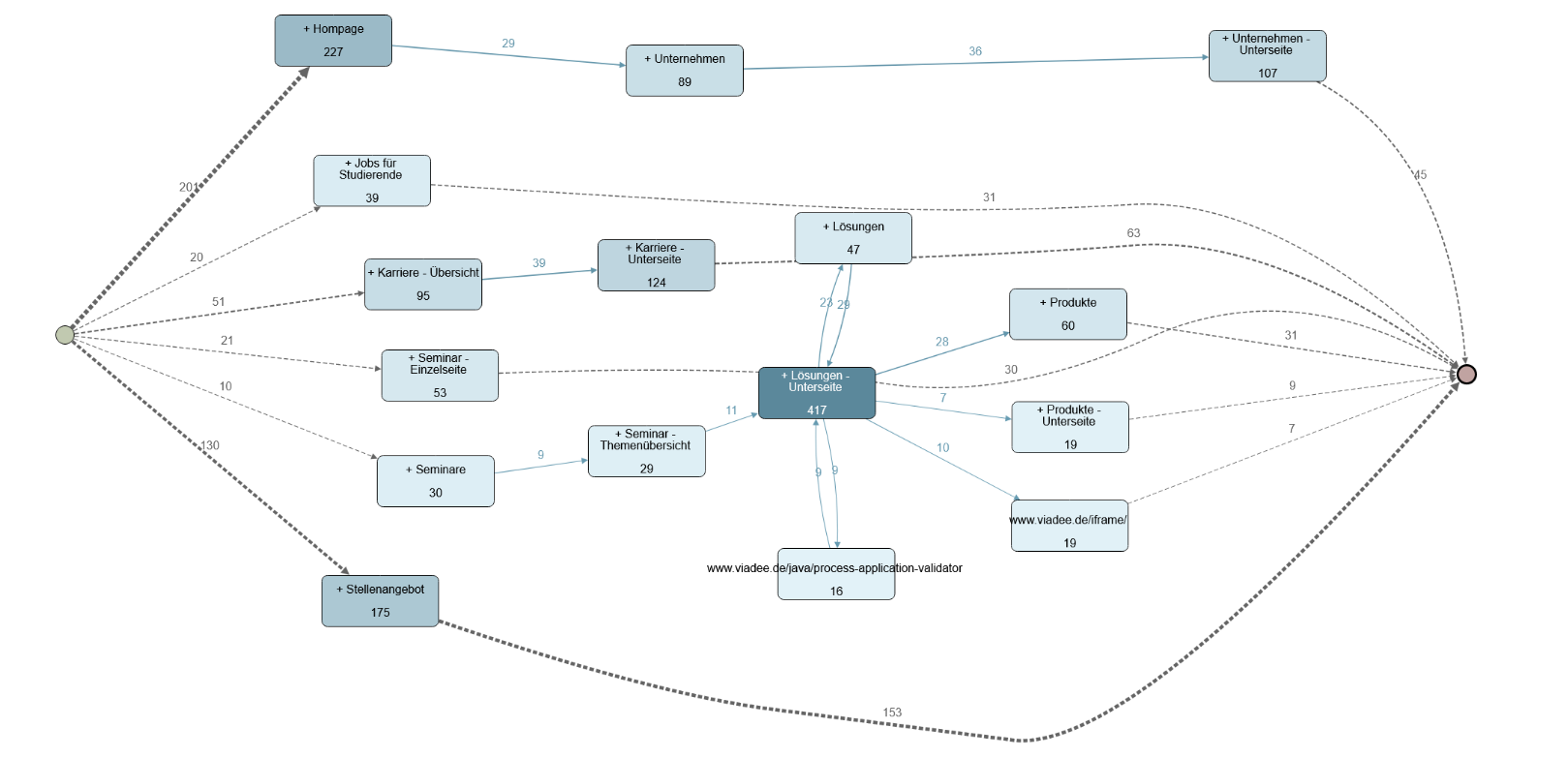
Hier lässt sich direkt auf den ersten Blick erkennen, dass es Seiten mit einem starken Bezug untereinander gibt und solche, die zu keiner anderen Aktivität in einem signifikanten Verhältnis stehen. Wie ist das zu interpretieren?
- Es fällt beispielsweise bei den Stellenangeboten und der Homepage auf, dass ein Großteil der Zugriffe direkt auch den Startpunkt eines Prozesses darstellt. Bei den Stellenangeboten ist von 175 Prozessen nämlich bei 130 unmittelbar die erste Aktivität der Aufruf eines Stellenangebots. Dies lässt sich durch die Verlinkung einer konkreten Stellenanzeige auf Social Media und Job-Portalen erklären. Gleichzeitig stellt diese Stellenanzeige jedoch auch für 153 der 175 Prozesse die letzte Aktivität dar. Hieraus lässt sich schließen, dass die Nutzer:innen keine weiteren Interaktionen auf der Webseite ausüben. Dies kann daran liegen, dass sich die potentiellen Bewerber:innen unmittelbar auf eine Stellenanzeige per Mail bewerben, es kann allerdings auch ein Hinweis auf fehlende Interaktion auf der Webseite sein.
- Bei den einzelnen Unternehmensseiten (Unternehmen, Unternehmen - Unterseite) lässt sich ein starker Bezug erkennen. Bei einer höheren Detailstufe lässt sich wiederum ein Verweis auf die Unterseiten der Lösungen-Kategorie erkennen. Hier scheint also ein starkes Interesse an den einzelnen Teilbereichen der viadee zu bestehen
- Eine weitere Erkenntnis aus unserer Prozess Map ist, dass die Unternehmensseiten und die darauffolgenden Lösungsseiten nur einen schwachen Bezug zu den Karriereseiten zeigen. Man kann also in zwei Kategorien unterscheiden: Diejenigen, die sich für das Unternehmen und die Lösungen interessieren - mutmaßlich Kund:innen und solche, die sich für die viadee als Arbeitgeber interessieren. Es scheint also für potentielle Bewerber:innen zu wenig Pfade zu geben, um sich mit den Lösungen der viadee auseinanderzusetzen. Auch über einen Rückweg könnte man nachdenken: Wer sich für unsere Inhalte interessiert, ist möglicherweise auch als neue:r Kolleg:in interessant. Inwieweit dies gut oder schlecht ist, bleibt zu diskutieren. Die Erkenntnis aus dem Prozessmodell ermöglicht aber jetzt fundierte Diskussionen dieser Art.
Beispiel: Stöbern und filtern im Prozessmodell
Den Punkt der Karriere-Unterseiten können wir noch genauer beleuchten, indem wir speziell nur solche Prozesse selektieren, welche den Besuch dort beinhalten: Wir fokussieren nur noch auf die vermeintlichen Bewerber:innen und deren Nutzungsprozesse. Das macht auch seltenere Verläufe sichtbar. Jetzt sehen wir auch Prozesse, welche nicht direkt enden:
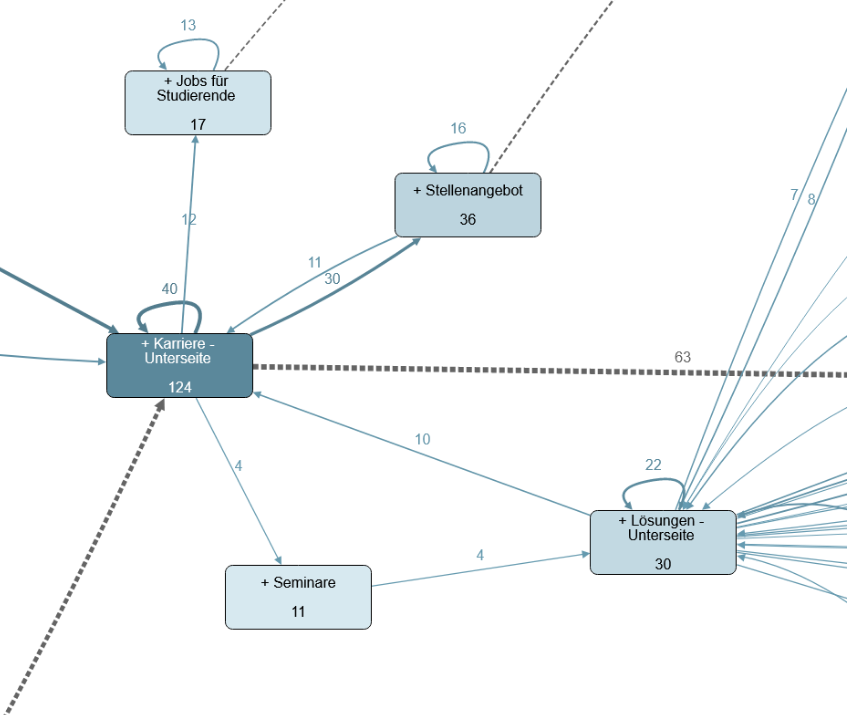
Hier haben wir uns auf einen Bildausschnitt fokussiert, welcher die Karriere Unterseiten in den Fokus stellt. In unserem Fall können wir feststellen, dass neben den 63 Prozessen, in welchen die Unterseite den Ausstiegspunkt des Prozesses darstellt, immerhin auch 30 mal auf ein konkretes Stellenangebot geklickt wird. Ferner ist bei 12 Prozessen eine Navigation auf Jobs für Studierende erfolgt und 16 Personen haben mehr als ein Stellenangebot betrachtet.
Denkbar wären nun auch detailliertere Analysen wie die der Unternehmensseiten untereinander. Welches Thema leitet auf welches andere Thema weiter? Was wird am häufigsten geklickt? Bei welchem Thema springen Nutzer:innen ab? Welches Thema verleitet die Nutzer:innen zu einem längeren Besuch auf der Webseite und die lange sind die durchschnittlichen Verweildauern auf den jeweiligen Seiten?
Fazit
Auf Fragestellungen dieser Art können wir mittels Process Mining leicht Antworten geben und auch Erkenntnisgewinn ohne konkrete Fragestellung ist möglich. Besonders gut geeignet sind Websites oder prozessorientierte Web-Anwendungen mit einem deutlicheren Ziel, wie bspw. einer Bestellung oder einer Terminvereinbarung. In solchen Fällen kann man leicht erfolgreiche und nicht-erfolgreiche Prozess-Varianten vergleichen. viadee.de ist eine vergleichsweise schwer zu analysierende Seite, weil es viele Seiten mit fachlichen Inhalten und viel Flexibilität im Nutzungsprozess gibt.
Detaillierte Einblicke auf die einzelnen Prozesse der Nutzer:innen lassen sich durch die Logfiles des Servers mit den richtigen Mitteln recht leicht erschließen. Gängige Online-Tools stellen nur einzelne Seiten in den Fokus. Zwar ist hier durchaus auch ein Bezug zu den Vorgänger- und Folgeseiten vorhanden, der Gesamtprozess eines Nutzers wird jedoch nicht sichtbar.
Ausnahmen bieten hier Tools wie Hotjar, mit denen sich die Prozesssicht allerdings auf einen einzelnen Nutzer beschränkt, dessen Verhalten sozusagen auf einer Website aufgezeichnet wird. Man kann also herausfinden, wie einzelne Nutzer:innen auf einer Webseite navigieren und auch welche Seiten wie aufgerufen werden (beispielsweise über eine Heatmap). Allerdings findet keine Aggregation der Prozesse statt. Es kann also stets gesehen werden, was ein:e einzelne:r Nutzer:in tut, ohne zu verallgemeinern. Vor dem Hintergrund der Datensparsamkeit sind solche Werkzeuge mindestens fragwürdig.
In der nachfolgenden Übersicht haben wir zusammengetragen, an welchen Stellen wir bei ausgewählte Tools Stärken und Schwächen ausmachen können:
| Hubspot | Google Analytics | Hotjar | Process Mining auf Server Logs | |
|
Eine dritte Partei hat Zugriff auf personenbezogene Rohdaten
|
Bei der serverseitigen Variante können die Daten, welche versendet werden, beeinflusst werden. |
|||
| Analyse auf Prozessebene Kann ich aus der Analyse die Prozesse ableiten, welche auf meiner Webseite stattfinden |
Auf Seitenbasis möglich (Vorgänger / Nachfolger), weder größere Prozesse noch einzelne Besucher:innen sichtbar |
Einzelne Prozesse können betrachtet werden, nicht aber Prozesse in ihrer Gesamtheit |
||
| Abhängigkeit von JavaScript/ Cookies Kann auch ohne aktiviertes JavaScript / Cookie-Zustimmung gearbeitet werden? |
||||
| Ausblenden des eigenen Traffics (z.B. eigene Mitarbeiter:innen) möglich Kann ich die Aufrufe ausblenden, die beispielsweise beim Editieren meiner Webseite anfallen? |
Eigene Nutzer:innen können bedingt (z. B. aufgrund statischer |
|||
| Plattformübergreifend Kann ich die Analyse neben meiner Webseite auch auf meinem Blog ausführen, der über ein anderes System realisiert wird? |
Die Analyse setzt den Zugriff auf die Log-Dateien voraus |
|||
| Caches und CDNs machen Traffic unsichtbar Kann trotz zwischengespeicherter Seiten ein erneutes Laden als Aufruf erfasst werden? |
||||
| Zugriffe auf fehlende Inhalte sichtbar Kann ich analysieren, welche Seiten NICHT gefunden werden? |
||||
| Technische Nutzung der Seite sichtbar (Suchmaschinen-Bots, Angriffe, RSS etc.) Sehe ich, welchen Anteil Bots und vermeintliche Hacking Versuche an meinem Traffic haben? |
||||
| Navigation innerhalb einer Seite sichtbar (Single Page Apps) Können bei einer Single Page App dennoch die einzelnen Unterseiten getracked werden? |
Teilweise - immer dann, wenn Server-Interaktion |
|||
| Zusätzlicher Network Traffic Remote-Tracking verbraucht zusätzliche Ressourcen, insb. auch die Zeit der Nutzer:innen |
(Video-Content = hohes Datenvolumen) |
Gängige Analysen, wie Klickzahlen pro Seite oder häufige Fehlerseiten (beispielsweise, um veraltete Links aufzuspüren), lassen sich mit wenigen Handgriffen ebenfalls auf den korrekt vorbereiteten Prozessdaten anwenden und im Kontext verstehen.
Lust auf eigene Experimente?
Mit Methodenwissen und vorbereitetem Werkzeug sind Analysen dieser Art schnell und einfach möglich. Nach einem Überblick über Ihre Log-Daten schauen wir gern für Sie detailliert dorthin, wo es sich lohnt:
- Menschen und Bots,
- alle Menschen, unabhängig von ihrer Sicherheitskonfiguration, aber immer im Prozessverlauf,
- existierende und fehlende Seiten,
- mit konkreter Fragestellung oder als Entdeckungsreise zur Qualitätssicherung.
Lassen Sie uns darüber reden, was Ihnen bei der Analyse Ihrer Webseite an Informationen wichtig ist und wo Sie sich tiefere Einblicke in die Prozesse Ihrer Nutzer:innen wünschen.

Abgrenzung: Was ist anders als im Web Log Mining vor 20 Jahren?
Warum sollte man überhaupt einen Process Mining Ansatz wählen und Daten individuell betrachten, wenn es doch schon fertige Tools wie Google Analytics gibt? Was ist jetzt anders als damals, als diese Begriffe geprägt wurden?
Quote:
Process hygiene: "Wash your Hands and do Process Mining - Are You Sure You Need a Business Case?"
Wil van der Aalst, Twitter
Auf Datenseite: Zum einen wird durch die oben aufgeführte Tabelle klar, dass dieser Ansatz in Bezug auf den Datenschutz klar punkten kann. Es ist also deutlicher, wer die Daten verarbeitet und es müssen auch keine Daten an Drittanbieter geschickt werden.
Dies führt wiederum dazu, dass die Nutzer:innen den Cookies nicht explizit zustimmen müssen – ein Gewinn für beide Seiten: Als Webseite-Betreiber können wir uns auf eine größere Datenbasis stützen; als Nutzer:in sind meine personenbezogenen Daten sicherer, da wie oben beschrieben nur eine nicht zurückführbare Form der IP-Adresse als eindeutiges Merkmal gespeichert wird (und die Informationen sich weniger verteilen). Darüber hinaus: Wenn ich die Daten selbst verwalte, kann ich sie auch zu anderen Datenquellen in Bezug setzen, wie bspw. Marketing-Aktivitäten, Preisänderungen etc., um eine kausale Analyse von Ursachen und Wirkungen zu betreiben. Das wird mit Standard-Werkzeugen nicht möglich werden.
Auf Methodenseite: Zum anderen wird dieser Ansatz erst durch die Weiterentwicklung diverser Daten- und Process Mining Tools in den letzten Jahren überhaupt skaliert anwendbar.
So war Process Mining vor 20 Jahren noch ein Forschungsthema in seinen Anfängen und entsprechende Verarbeitungsmöglichkeiten haben sich erst in den letzten ca. 10 Jahren aufgetan. Sowohl große Firmen (wie Celonis) sind in dieser Zeit entstanden als auch Open-Source basierte Tools wie das für diesen Blogbeitrag verwendete Apromore. Process Mining und Data Science-Methoden sind "demokratisiert" worden und haben die Ergebnisse leicht herstellbar und zugänglich gemacht: Sie sind jetzt so leicht zugänglich, dass van der Aalst ihre Nutzung als Prozesshygiene einfordert und auf die gleiche Stufe wie das Händewaschen stellt.
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



