
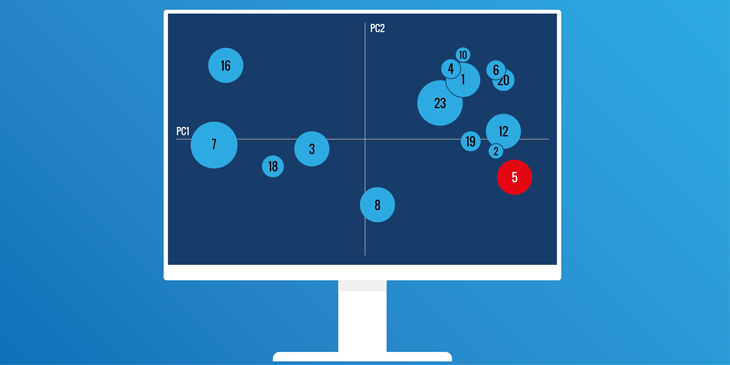
Quellcode wird erstaunlich oft gelesen – meist zur Orientierung. Eine technische Orientierung ist dabei gut durch IDEs unterstützt. Kann Machine Learning fachliche Orientierung geben?
Die Einarbeitung in neue Softwareprojekte ist aufwendig. Entwickler und Architekten sind gefordert, sich regelmäßig in neue – ggf. unübersichtliche – Projekte einzuarbeiten: Um Änderungen zu machen und deren Effekte abzuschätzen oder die Gesamtarchitektur zu prüfen. Dokumentation hilft dabei erfahrungsgemäß nur begrenzt. Am Ende zählt der Code.
Idealerweise gibt das Domänenwissen die Struktur von Softwareprojekten wieder oder lässt sich darin leicht erkennen – Domain Driven Design (DDD) erhebt das zum Grundprinzip. Machine Learning-Verfahren der Kategorie Topic Modeling lassen sich nutzen, um fachliche Modularisierung zu prüfen und navigierbar zu machen. Auch wenn ein Projekt jegliche Paket-Struktur vermissen lässt, werden vermutlich die Begriffe und Kommentare im Quellcode erkennbare Domänen bilden. Der Fachbegriff dafür ist Topic.
Ein Topic besteht dabei aus einem Mix von charakteristischen Wörtern und deren Häufigkeitsverteilung. Ein Dokument wird potenziell aber durch mehrere Topics beschrieben. So lassen sich bspw. auch die Themen von Tweets oder Zeitungsartikeln maschinell auswerten, um einen Überblick über mehr Artikel zu bekommen, als man selbst zu lesen bereit ist. Versuchen wir es mit dem Java-Quellcode eines bekannten Projektes: Spring Boot.
Für unsere Zwecke bilden alle Java-Dateien eines Git-Repositories den Textkorpus. Zunächst ist etwas Vorverarbeitung notwendig: Sonderzeichen und Wörter, die in jeder Datei vorkommen (public, class), sind bspw. uninteressant. Sie werden nicht relevant dazu beitragen können, fachliche Domänen aufzuzeigen.
Für unser Experiment führen wir die folgenden Vorverarbeitungsschritte aus:
- Tokenization der Dokumente, also ein Auftrennen in einzelne „Wörter“
- Eliminierung von Sonderzeichen, Operatoren und Schlüsselwörtern
- Aufteilen von CamelCase-Wörtern
- Eliminierung von Wörtern, die aus weniger als vier Buchstaben bestehen
- Verkleinerung von Großbuchstaben
- Lemmatisierung: Dabei handelt es sich um das Zurückführen von Wortvarianten auf den Wortstamm (z. B. ‚am’, ‚are’, ‚is’ → ‚be’)
- Eliminierung von Stoppwörtern, die keine relevante semantische Information tragen
- Eliminierung von Wörtern, die in weniger als drei Dokumenten und in mehr als 80 % der Dokumente vorkommen
Das Ziel bei der Datenvorverarbeitung ist immer, die Menge an Wörtern zu verdichten, so dass Wörter, die sich Domänen zuordnen lassen, den Textkorpus dominieren. So wird das Erstellen von Topics wahrscheinlicher, die sich interpretieren lassen.
Das Endprodukt, genannt Bag-of-Words (BoW) wird mit dem Algorithmus Latent Dirichlet Allocation (LDA) untersucht. Das ist das aktuell populärste Topic-Modeling-Verfahren, als OpenSource-Bibliothek (Python) verfügbar und relativ leicht einzusetzen.
Aus den vorverarbeiteten Wörtern wird an dieser Stelle eine Dokumenten-Term-Matrix erstellt. Jedes Wort (Term) hat eine eigene Spalte und jedes Dokument seine Zeile. In den Zellen steht die absolute Häufigkeit, wie oft das Wort in dem Dokument vorkommt.
|
helloworld |
hello |
world |
args |
... |
|
|
Dok. 0 |
2 |
3 |
3 |
1 |
|
|
Dok. 1 … |
... |
LDA besitzt verschiedene Parameter, insb. um eher trennscharfe oder breite Topics zu erzeugen. Der Parameter mit dem höchsten Einfluss auf das Ergebnis ist die Anzahl der Topics, die erstellt werden sollen. Eine Herausforderung bei der Anwendung von Topic Modeling liegt darin, eine optimale Anzahl von Topics festzulegen. Die Literatur zeigt, dass bisherige Kohärenzmaße, die versuchen, die Güte von Topic Models zu messen, nicht gut mit der manuellen Beurteilung der Anwender korrelieren. Das bedeutet, dass der Anwender selbst beurteilen muss, ob Topics gut interpretierbar sind und sich z. B. eindeutig einer Domäne zuordnen lassen.
Je mehr Topics berechnet werden, desto spezifischer sind sie und desto höher ist der zeitliche Aufwand, um sie zu interpretieren. Es ist nicht sicher, dass sich immer alle Topics interpretieren lassen. 25 erscheint hier eine gute Größenordnung zu sein.
Nach kurzer Rechenpause werden wir mit folgender Karte des Spring-Boot-Projekts belohnt. Dort sind viele Topics interpretierbar.
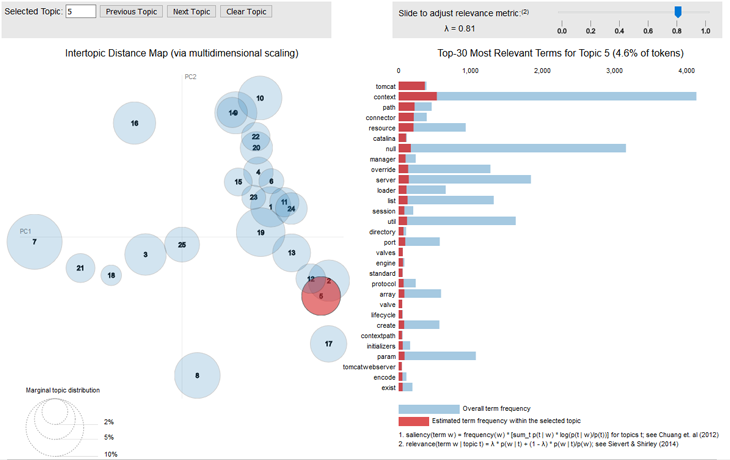
Links sehen wir die Struktur der Topics untereinander. Topic Nr. 5 ist hier selektiert und die Wortverteilung auf der rechten Seite bezieht sich nur auf das Topic. Hier ist schnell zu erkennen, dass der Apache Tomcat das Topic charakterisiert. Der Begriff Tomcat kommt nahezu trennscharf nur innerhalb des Topics vor und nicht außerhalb davon (der Balken ist fast vollständig rot gefärbt). Weitere Begriffe passen in den Tomcat-Zusammenhang, sind aber weniger „definierend“ (wie zum Beispiel „path“) oder weniger häufig („catalina“). Das Topic ist schlüssig interpretiert.
Jetzt bietet sich eine kleine Quiz-Frage an: Was könnte sich hinter Topic 2 verstecken, das auf der latent-semantischen Topic-Karte dicht am Tomcat-Topic sitzt, folglich Überschneidungen haben wird und dabei ähnlich groß ausgeprägt ist? Richtig: Jetty, der zweite eingebettete Servlet-Container im Spring-Boot-Projekt.
Spring Boot enthält zwei (wählbare) Technologien, die fachlich sehr ähnliche Dinge tun. Als Infrastrukturprojekt kann man so etwas anbieten. In einem fachlich getriebenen Projekt wäre eine solche Überschneidung bzw. Dopplung etwas, über das sich als Architekt sicher zu reden lohnt.
Während für natürliche Texte kaum weitere Strukturdaten existieren, die man mit in die Analyse geben könnte, gibt es für alle Java-Quellcodes noch eine weitere Option: Wir können die Topics mit der Paketstruktur vergleichen und so erkennen, wie sinnvoll diese gewählt ist, um Topics abzugrenzen bzw. wie konsequent das tatsächlich erfolgt ist.
Für die Visualisierung der Paket-Hierarchie bietet sich eine navigierbare TreeMap an. So kann die Verteilung eines Topics (bestenfalls einer fachlichen Domäne) analysiert werden. Je dunkler ein Rechteck ist, desto stärker ist das gewählte Topic „Tomcat“ in dem Paket enthalten.
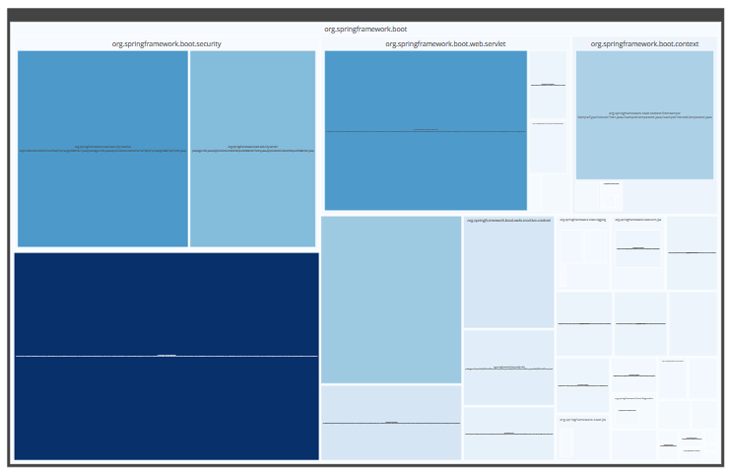
Das Topic „Tomcat“ ist stark konzentriert in einem Paket links unten. Dass weitere Pakete wie org.springframework.boot.security oder org.springframework.boot.web.servlet sich auf gleicher Paketierungsebene auch mit diesem Topic beschäftigen, erscheint nachvollziehbar und sinnvoll. Gäbe es nur einen Servlet-Container im Framework, wäre vielleicht noch eine konsequenter abgegrenzte Paketstruktur möglich?
In Summe sind wir mit unserem Experiment zufrieden und haben es noch mit zwei viadee-Projekten erfolgreich wiederholt. Topic Modeling kann ein nützliches Architekten-Werkzeug sein – gerade in großen Code-Basen.
Als nächsten Schritt könnte ich mir gut vorstellen, das Vorgehen mit größeren Legacy-Projekten zu erproben. Vielleicht auch mit COBOL-Code? Sprechen wir darüber!
Die Ergebnisse stammen aus der Bachelor-Thesis von Kilian Arnsmeyer in Zusammenarbeit mit Prof. Thöne an der FH Münster.
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



