
Spring Batch-Prozesse fallen in die Kategorie der Dunkelverarbeitung. Durch automatische Ausführung und fehlende Benutzerinteraktion ist der interne Prozessablauf dabei schwer nachvollziehbar. Eine Nachvollziehbarkeit ist jedoch wichtige Voraussetzung, um Fehler bzw. Anomalien zu beheben oder Performance-Optimierungen vorzunehmen. Aus diesem Grund werden Monitoring-Tools wie das Spring Batch Performance Monitoring Tool eingesetzt. Diese vereinfachen die Analyse bis auf Datensatzebene erheblich.
Anomalie-Erkennung
Im Rahmen einer Abschlussarbeit wird diese automatisierte Anomalie-Erkennung analysiert und umgesetzt. Ein Bestandteil davon ist es, häufig auftretende Anomalien zu identifizieren. So können etwa verschiedene Konstellationen der Datensätze dafür sorgen, dass Prozesse zu Langläufern werden. Das Identifizieren solcher Konstellationen ist hilfreich, um anomale Datensätze zu finden.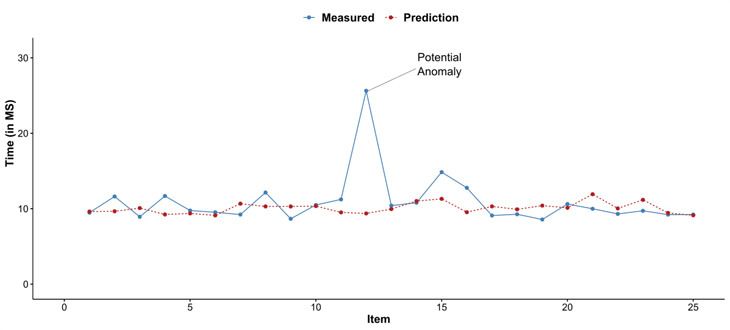
Des Weiteren ist es sinnvoll, die Gesamtlaufzeit einzelner Prozesse im operativen Betrieb zu überwachen, um Veränderungen im Lastprofil in Abhängigkeit des Durchführungszeitpunkts zu ermitteln. Das Spring Batch Performance Monitoring (SBPM) Tool wird dazu mit neuen Funktionen erweitert, die es einem ermöglichen, die Laufzeit des gesamten Prozesses im Betrieb ohne zusätzliche Software zu überwachen und langfristig zu speichern. Die so aufgezeichneten Messungen des Tools dienen als Datenbasis für eine automatisierte Anomalie-Erkennung.
Analyse der Laufzeit
Als Grundlage für die Betrachtung der Laufzeit eines Batch-Prozesses wird eine Regressionsanalyse verwendet. Mit dieser wird versucht, die Laufzeit einzelner Items oder ganzer Ausführungen auf Basis des gelernten Verhaltens vorherzusagen. Im Gegensatz zu einem Klassifikationsverfahren ist bei diesem Ansatz ein zusätzliches Kennzeichnen von Datensätzen obsolet. Nach dem Durchlauf des Batch-Prozesses wird mithilfe einer Machine Learning-Plattform einmalig ein Modell erstellt, welches für nachfolgende Durchläufe desselben Prozesses verwendet werden kann. Die Abbildung veranschaulicht die Laufzeit zwischen dem gemessenen Wert des Monitoring-Tools und dem vorhergesagten Wert des Modells.Durch eine Quantifizierung der Abweichung der beiden Werte können anomale Datensätze identifiziert werden. Bei einem relativ hohen Wert kann es sich bei diesem Datensatz um eine mögliche Anomalie handeln. Der Anwender kann daraufhin benachrichtigt und so in die Lage versetzt werden, die mögliche Anomalie weiter zu analysieren.
Zusammenfassung
Die Möglichkeiten, die sich durch den Einsatz von Data Mining ergeben, sind vielzählig und können stets erweitert werden. Neben der hervorgehobenen Laufzeit-Analyse bietet die vorhandene Datenbasis das Potenzial, weitere Aspekte zu betrachten. Durch den Einsatz von Natural Language Processing kann beispielsweise die Semantik der ausgegebenen Log-Nachrichten analysiert werden, um so weitere Zusammenhänge und Muster zu offenbaren.Die hier verwendeten Informationen können über die Erweiterungen des Spring Batch Performance Monitoring Tools bereits überwacht werden. Um die bisherige Kompatibilität sicherzustellen, kann dies durch eine Parametrisierung des Tools über die vorhandene Konfigurationsdatei aktiviert werden. Erste Analysen mit den neuen Informationen finden über separate Skripte und eine Machine Learning-Plattform statt. Weitere Integrationen mit dem SBPM sind in der Vorbereitung. Wir freuen uns über weitere Fragen und Anregungen jeglicher Art zu diesem Thema.
Hinweis: Dieser Artikel fasst im Wesentlichen Erkenntnisse aus Literatur-Recherche, eigenen Experimenten und Experten-Interviews aus der Master-Arbeit von Alexander Schultenkämper an der FH Münster 2018 zusammen.
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



