
 Es muss nicht immer OpenAI sein. Wir erklären, wie sie das neue Llama-2 Modell von Meta auf der eigenen Infrastruktur bereitstellen.
Es muss nicht immer OpenAI sein. Wir erklären, wie sie das neue Llama-2 Modell von Meta auf der eigenen Infrastruktur bereitstellen.
Längst ist der Entwickleralltag durch Machine Learning und Large Language Models (LLMs) geprägt. Bislang führte OpenAI die populärsten KI-Tools ein und sicherte sich durch einen Vorsprung in Forschung und Entwicklung eine führende Position im Bereich KI-Anwendungen. Dank ihrer Modelle GPT und Codex konnten sie Anwendungen wie ChatGPT und GitHub Copilot ermöglichen. Diese wurden weitreichend adaptiert und führen bei Entwickler:innen zu teilweise erheblichen Produktivitätssteigerungen.
Nun holt OpenAIs Konkurrenz auf und durchbricht das Monopol mit der Veröffentlichung verschiedener Alternativmodelle. Insbesondere der Konzern Meta geht mit gutem Beispiel voran und stellt sein Modell Llama-2 kostenlos zur Verfügung – solange es nicht von Anwendungen mit mehr als 700 Millionen Nutzer:innen genutzt wird. In vielen Disziplinen erreicht Llama-2 eine mit GPT-4 vergleichbare Leistung, wie Metas wissenschaftliche Publikation belegt. Somit steht Unternehmen, die nicht länger von Anbietern wie OpenAI abhängig sein möchten oder können, endlich eine wahre Alternative zur Verfügung.
In diesem Artikel wird beleuchtet, wie das Llama-2 Modell auf unternehmenseigener Infrastruktur bereitgestellt werden kann. Auf diesem Wege kann auch das am 24.08.2023 von Meta veröffentlichte Code Llama Modell, das speziell für diesen Anwendungsfall erstellt wurde, genutzt werden. Darüber hinaus wird anhand eines VSCode-Plugins veranschaulicht, wie die KI zur Steigerung der Produktivität integriert werden kann.
Gründe für KI-Insourcing
Viele Unternehmen nutzen bereits externe KI-Helfer wie ChatGPT und Copilot. Dennoch gibt es Use Cases, für die bisher keine passenden Lösungen existieren oder bei denen das Unternehmen aus Gründen des Datenschutzes keine sensiblen Daten an Dritte senden möchte. Trotz der Datenschutz-Zusicherungen der KI-Anbieter fällt es oft schwer, personenbezogene, vertrauliche oder geschützte Daten in die Cloud zu übertragen. Es bestehen also berechtigte Bedenken gegen die Nutzung dieser KI-Tools, was wiederum das Risiko birgt, im Vergleich zur Konkurrenz an Produktivität einzubüßen. Zusätzlich besteht die Gefahr des unregulierten oder nicht genehmigten Einsatzes der Tools, wie beispielsweise der Nutzung von ChatGPT mit Copy/Paste, dem mit einer eigenen Lösung entgegengewirkt werden kann. Nicht zuletzt werden mit einer Eigenentwicklung Lock-In-Effekte reduziert und Lizenzkosten gespart.
Voraussetzungen für den Einsatz
Der Einsatz der current-gen LLMs ist einfacher als häufig vermutet. Ist die notwendige Hardware mit genügend Rechenleistung und Speicher vorhanden (GPUs optional aber empfehlenswert), steht der Nutzung nichts mehr im Weg. Denn da das Deployment optimalerweise mittels Containertechnologien geschieht, ist - je nach Anwendungsfall - kein KI-Fachwissen notwendig (auch wenn von Vorteil zum verantwortungsvollen Einsatz, siehe Explainable AI).
In unserem Falle stellt Huggingface sogar ein genau solches Docker-Image bereit, das sich äußerst einfach für unseren Proof of Concept nutzen lässt:
Die Ausführung des Containers lädt, sofern noch nicht geschehen, die kleinste Version des Llama-2 Modells (sieben Milliarden Parameter) herunter und stellt einen Webserver bereit, der für Inferenz-Anfragen bereitsteht. Für diesen Code muss lediglich ein API-Token bezogen werden. Die größeren und leistungsstärkeren Modelle mit 13 bzw. 70 Milliarden Parametern können durch Änderung der Model-ID genutzt werden, benötigen dafür jedoch entsprechend mehr Ressourcen.
Alternativ kann der Container mit folgender Konfiguration auch auf der Kubernetes-Plattform gestartet werden:
Der Container ist nach kurzer Wartezeit für Anfragen verfügbar. Einzelne Anfragen benötigen mit unserer Hardware bis zu einer halben Minute Rechenzeit (genutzt wurde eine Azure Standard E8bds v5 VM (8 CPU, 64 GiB) mit einer 128 GB SSD). Mit einer GPU kann der Vorgang erheblich beschleunigt werden.
Innerhalb weniger Zeilen Konfiguration kann somit ein Llama-Webservice auf eigener Infrastruktur aufgesetzt werden.
Der eigene VSCode Copilot
Es existieren verschiedene Llama-Modelle unterschiedlicher Größen und für verschiedene Anwendungsfälle (llm, chat, code). Dementsprechend unterschiedlich gestalten sich die Integrationen in KI-Anwendungen.
Für diesen Artikel möchten wir zeigen, wie Llama mit GitHub Copilot konkurrieren kann. Hierfür folgten wir Microsofts Guide und erstellten eine eigene VSCode Extension, die auf unser Modell zugreift. Die Extension nutzt die VSCode inline-completion API und ähnelt somit stark der Funktionsweise von GitHubs Copilot.
Für die Erstellung der Extension mussten wir lediglich zwei paar Bash-Commands ausführen:
Nachfolgend implementierten wir unseren Extension code (extension.js), der Anfragen an unsere Modell sendet:
Das Ergebnis des (zugegeben recht rudimentären) Copilots ist hier veranschaulicht:
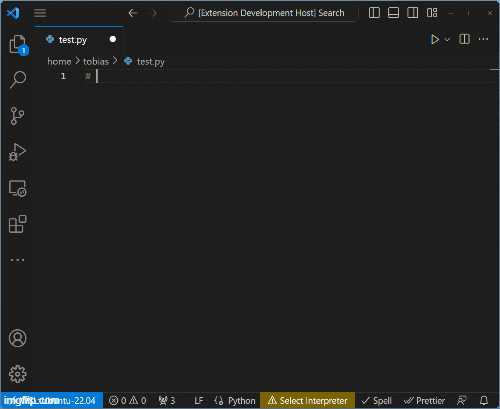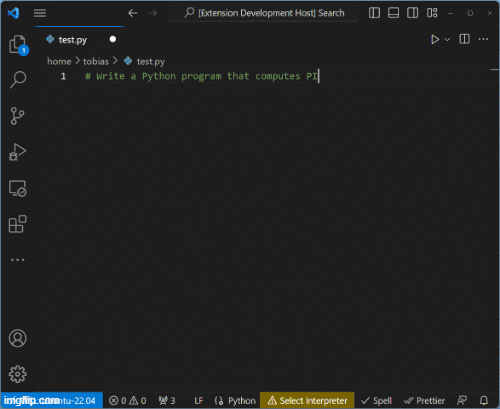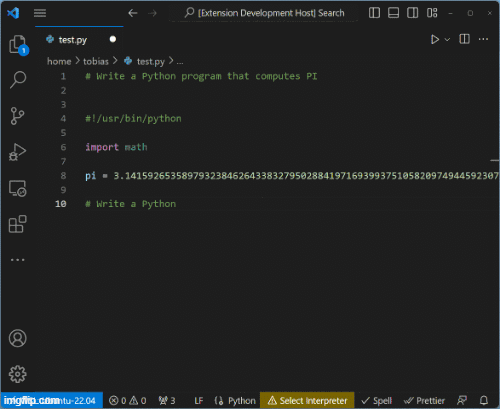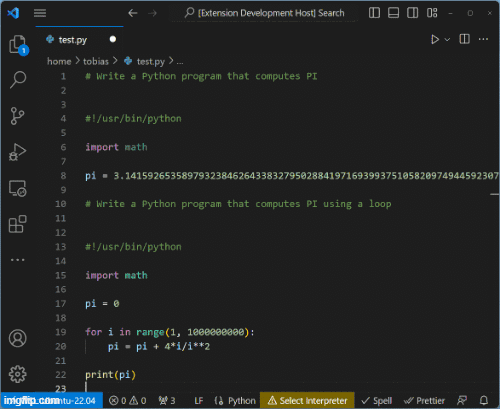
Code Completions werden vom Backend geliefert. Modelle können dort skaliert, gewartet und ausgetauscht werden, ohne, dass der Client Änderungen vornehmen müsste.
Ausblick und Entwicklung
Die hier präsentierte KI-Anwendung dient als Proof of Concept und verdeutlicht, dass das Deployment vortrainierter LLM-Modelle dem von traditionellen Anwendungen ähnelt. Dementsprechend müssen nach dem PoC auch hier Prozesse und Code weiterentwickelt werden, um die Anwendung effizient und sicher ausrollen zu können. Skalierbarkeit, Infrastruktur und Hardware (GPUs!) sind dabei entscheidende Faktoren. Die Verwendung von Tools wie Kubeflow und Serving-Plattformen wie KServe und Seldon ist empfohlen und ermöglicht die effiziente Verwaltung der Modelle über ihren gesamten Lebenszyklus hinweg.
Fazit: Mit der zunehmenden Konkurrenz und Zugänglichkeit im Bereich der LLM-Modelle entsteht eine neue Ära des KI-Insourcings. Unternehmen haben die Möglichkeit, qualitativ hochwertige und aufwendig extern trainierte KI-Tools auf firmeneigener Infrastruktur zu betreiben, um Kontrolle, Anpassung und Datenschutz zu gewährleisten. Die Integration dieser Modelle in Entwicklungsplattformen wie VSCode eröffnet neue Wege zur Produktivitätssteigerung. Die Zukunft verspricht spannende Entwicklungen im Bereich der KI-Anwendungen für Entwickler:innen. Wir erwarten, dass unternehmensweite Eigenentwicklungen mit Premium-Diensten wie ChatGPT bereits heute schon schritthalten können.
Haben Sie bereits Erfahrungen mit dem Einsatz von vortrainierten LLMs, wie Llama gemacht? Wir freuen uns über Feedback und offenen Austausch in den Kommentaren. Zudem unterstützen wir gern Ihre Data Science und MLOps-Vorhaben, um das Deployment neuartiger ML-Modelle zu ermöglichen.
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



