
 Wie entwickeln sich im Scrum-Projekt wichtige Kennzahlen langfristig und warum? Diese vermeintlich einfache Frage führt Scrum Master:innen schnell mit einem Fuß in die Data Science-Domäne: Trends, gleitende Durchschnitte, Ausreißer und Korrekturfaktoren für Kapazität stehen auf den Wunschlisten. Dann entstehen in vielen Fällen Excel-Tabellen, die manuell mit Daten aus einem JIRA gefüttert werden — und die immer komplexer werden.
Wie entwickeln sich im Scrum-Projekt wichtige Kennzahlen langfristig und warum? Diese vermeintlich einfache Frage führt Scrum Master:innen schnell mit einem Fuß in die Data Science-Domäne: Trends, gleitende Durchschnitte, Ausreißer und Korrekturfaktoren für Kapazität stehen auf den Wunschlisten. Dann entstehen in vielen Fällen Excel-Tabellen, die manuell mit Daten aus einem JIRA gefüttert werden — und die immer komplexer werden.
Schnell stößt man an die 1.000-Issue-Grenze von JIRA-Datenexporten oder die Grenzen von Excel. Anhand der Kennziffer Velocity zeigen wir auf, wie Data Science Scrum Master:innen bei der Sprint-Analyse unterstützen kann. Teil zwei unserer Blogreihe zu den Möglichkeiten des Jira-Ticket-Mining.
Der Data Science-Werkzeugkasten ist immer leichter zugänglich geworden. Mit Hilfe der JIRA-API können die Daten aus JIRA leicht zugegriffen werden. Dieses Vorgehen bietet unter anderem folgende Vorteile:
- Die JIRA-API bietet mehr Möglichkeiten für Datenexporte als die JIRA-Benutzeroberfläche: Auch Änderungshäufigkeiten und andere Details stehen zur Verfügung.
- Wir können auf beliebig viel Issues blicken, die 1.000'er-Grenze fällt.
- Wir können Abfragen und Teilmengen anschauen, die mit JIRA-Bordmitteln (JQL) nicht selektierbar sind.
- Auf diese Weise entstehen vollautomatische Abläufe, die Zeit sparen und deren Dashboards immer aussagefähig und leicht zu erfassen sind - aber auch anpassbar.
Um zu verdeutlichen, wie die konkreten Ergebnisse dieses Ansatzes aussehen, folgen zwei konkrete Analysen aus der Praxis:
Entwicklung von Sprints und Velocity über die Zeit
Sprints sind das zentrale Element im Scrum Framework. Im Sprint Planning wird ein Plan geschaffen, welche Aufgaben im Zeitrahmen des Sprints umgesetzt werden — idealerweise um ein Sprint-Ziel zu erreichen. Dazu werden die einzelnen Issues oft mit Story Points bewertet. Im Laufe der Zeit entwickelt jedes Team ein Gefühl dafür, wie viele Story Points in einem Sprint üblicherweise abgearbeitet werden können. Diese Zahl wird als Velocity bezeichnet. Ändert das Scrum Team seine Prozesse und Vorgehensweisen, kann sich die Velocity des Sprints über die Zeit ändern.
Dabei ist die Entwicklung der Velocity über die Zeit eine spannende Messgröße, die in Dashboards visualisiert werden kann. Dabei können wir mit Hilfe der API weit über das im JIRA enthaltene Reporting hinausgehen mit folgenden Analysen erstellen:
- Trends und gleitende Durchschnitte
- Abgleich mit Urlaubstagen im Kalender der Team-Mitglieder, um die Veränderungen der Kapazität zu berücksichtigen
- Korrelation der Velocity mit anderen Werten, bspw. der Anzahl von Tickets ("Wie kleinteilig sollten wir arbeiten?")
Oft spielt das Umfeld des Projektes eine wichtige Rolle — durch Support-Anfragen und mehr: Das Scrum Framework setzt sich zum Ziel, dass am Ende eines Sprints ein Sprint-Ziel erreicht wird und alle Issues abgearbeitet sind. Aus diesem Grund sollten während des Sprints keine Issues zum Sprint hinzugefügt werden und keine Issues sollten in den nächsten Sprint gezogen werden. Scrum Master:innen interessieren daher häufig die Fragen:
- Wie viele Issues gibt es, die dennoch von einem Sprint in den nächsten gezogen werden?
- Passiert es häufiger, dass innerhalb des Sprints neue Issues (zum Beispiel Bugs) zum Sprint hinzugefügt oder entfernt werden und beeinflusst das die Velocity?
Hier kann ein PowerBI-Dashboard, dass auf den automatisch extrahierten Daten basiert, schnell die jeweiligen hinzugefügten oder nicht abgeschlossenen Issues darstellen und interaktiv Informationen zu diesen bereitstellen. Außerdem können differenzierte Burndown Charts bzw. Cumulative-Flow-Charts und weitere Analysen gezeigt werden.
Für eines unserer viadee-Entwicklungsteams, das den BPMN-Modeler für Confluence vorantreibt, haben wir das in Bild 1 zu sehende Dashboard entwickelt. Dashboards dieser Art sind schnell erstellt und angepasst, wenn eine solide Datenbasis erst einmal vorliegt. Gegenüber den bestehenden JIRA-Reports und den Excel-Lösungen, die wir gesehen haben, gewinnen wir hier Flexibilität und den interaktiven Umgang mit größeren Datenmengen.
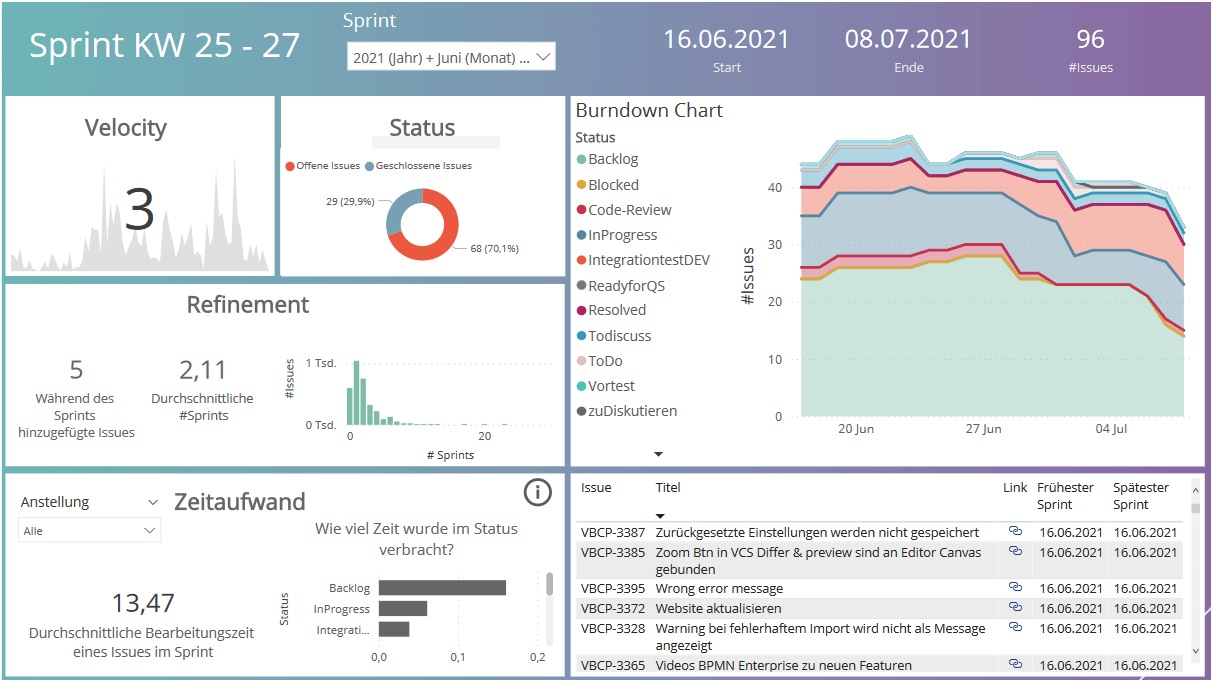
Bild 1: Übersicht des Sprints mit Informationen zu Refinement, Zeitaufwand der Issues und dem Anteil der Issues in einzelnen Status
Wie cross-funktional arbeitet mein Team und gibt es Kopfmonopole?
Mit dem Data-Science-Werkzeugkasten können wir relativ einfach mehr Fragen adressieren, die über das Zählen und Aggregieren von Issues und Storypoints deutlich hinausgehen.
Ein weiterer Punkt, der die Velocity des Sprints beeinflusst, ist die Flexibilität des Teams und die Verteilung von Skills, die zu den Herausforderungen des Teams passen müssen. Der Scrum Guide (TM) hält sich hierzu bedeckt, fordert nur, dass das Team die notwendigen Skills hat. Offensichtlich lohnt es sich aber, diesen Match (oder Mismatch) zu beobachten. Fehlen Skills im Team, werden die Mitarbeiter:innen nicht cross-funktional genug ausgebildet oder hat die Spezialist:in Urlaub, kann das zu einer geringeren Velocity führen - es gibt Engpässe. Vielleicht sucht das Team auch nach Hilfe? Wir interessieren uns also für zwei Fragen:
- Ist das Scrum Team cross-funktional aufgebaut oder entstehen Kopfmonopole in einzelnen Bereichen?
- Gibt es regelmäßig Bearbeiter:innen, die nicht zum betrachteten Scrum Team gehören?
Um diese Fragen zu analysieren, können die Issues anhand ihres Inhalts in einer 2D-Landschaft dargestellt werden. Dazu können beispielsweise Embedding- / Wort-Vektorisierungsverfahren wie sBERT genutzt werden, für die vortrainierte Machine Learning-Modelle frei verfügbar sind. Thematisch ähnliche Issues (auf Basis von Beschreibung, Titel und Kommentaren) liegen in der Grafik nah beieinander - Suchmaschinen wie Google benutzen die gleichen Verfahren, um Webseiten zu sortieren. In Bild 2 ist dies für alle Issues unseres Beispiel-Projektes erfolgt und zusätzlich sind alle Bearbeiter:innen farblich gekennzeichnet.
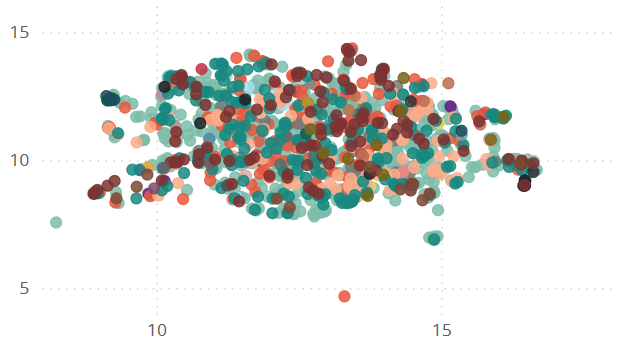
Bild 2: Wie lassen sich die Inhalte unserer Issues clustern und wer arbeitet an welchen Issue-Inhalten?
Wie ist das zu interpretieren? Ballungen einzelner Farbpunkte weisen darauf hin, dass eine Person viele Issues bearbeitet hat, die inhaltlich ähnlich sind - dies könnte auf Präferenzen und Komfortzonen aber auch auf Kopfmonopole hinweisen, die ggf. problematisch sind. Bearbeiter:innen, die nicht zum Scrum Team gehören, stechen bei dieser Analyse ebenfalls farblich ins Auge - auch dies entspricht nicht der Idee von Scrum, da das Scrum Team an dieser Stelle nicht eigenständig agiert.
Im konkreten Beispiel sehen wir eine starke Durchmischung von Themen und Personen, die Themen bearbeiten. Es sind Software-Breitensportler:innen mit 'M-shaped' Skill-Profilen am Werk und das ist erfreulich klar zu sehen.
Fazit
Viele für Scrum Master:innen spannende Fragen zu Sprints und deren Velocity können basiert auf den Daten aus JIRA beantwortet werden. Dabei müssen die JIRA-Daten nicht zwangsweise manuell exportiert und ausgewertet werden, sondern können mit Hilfe von interaktiven Dashboards passend aufbereitete Antworten auf die jeweiligen, individuellen Fragen liefern. Hier können spannende Erkenntnisse über die Sprints aufschlussreiche Inhalte für einen datengetriebenen Blick auf das Projekt liefern, die zum Beispiel in der Retrospektive angesprochen werden können. Danach kann ein individueller Weg innerhalb des Teams geplant und verfolgt werden. Auch hier können die Daten auf dem Dashboard Ihnen ihren Weg erleichtern.
Gerne unterstützen wir Sie bei der Einrichtung des automatischen Datenexports, der Erstellung ihrer ersten Dashboards (z.B. mit PowerBI) und deren Auswertung durch unsere professionellen Scrum Master:innen und Agile Coaches.
Wenn Sie Interesse an dem Thema Agiles Arbeiten und an agilen Methoden haben, dann gucken Sie bei unseren Expert:innen von viadee spark vorbei! viadee spark ist unsere Marke für Organisationsentwicklung, Agiles Arbeiten und Innovationsmanagement.
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



