
.jpg?width=8334&name=Process%20Mining%20in%20Power%20BI_Zeichenfl%C3%A4che%201%20(1).jpg)
Process Mining macht gelebte Standardprozesse sichtbar und ermöglicht die Identifikation von Prozessabweichungen. Self-Service BI mit Tools, wie Microsoft Power BI, ermöglicht die interaktive Analyse von Geschäftskennzahlen. Warum also die Erkenntnisse nicht in einem Tool integrieren und das Bild vervollständigen? Konkret haben wir uns gefragt: Wie können Prozessauffälligkeiten automatisch erkannt und mit Power BI aufbereitet werden? Welche Erkenntnisse werden dabei gewonnen? An einem Use Case zeigen wir die Integration in vorhandene BI Anwendungen mit Power BI.
Reporting verschafft Transparenz über die Geschäftsentwicklung und KPIs im Unternehmen. Durch Self-Service BI können Stakeholder interaktiv individuelle Fragestellungen beantworten, beispielsweise durch Filterung und Drill Down. Während der Blick auf die KPIs die Auswirkungen abbildet, liegt die Ursache oft in den dahinterliegenden Prozessen. Eine hohe Anzahl an Verspätungen in einem Logistikzentrum hat beispielsweise ihre Ursache höchstwahrscheinlich in Prozessverzögerungen, Fehlern oder Bottlenecks. Process Mining ist ein Verfahren, um solche gelebten Prozesse zu visualisieren und transparent zu machen (“Process Discovery”). Diese Erkenntnisse können genutzt werden, um die Prozesse zu optimieren.
Process Mining wird häufig als alleinstehende Lösung betrachtet, doch wenn Erkenntnisse über Prozesse in einen Zusammenhang mit KPIs gebracht werden, entsteht ein signifikanter Mehrwert bei Analyse und Interpretation dieser. Viel mehr werden Ursachen der KPIs deutlich, wodurch eine ganzheitliche Perspektive bei der Optimierung des Unternehmens eingenommen werden kann. Self-Service BI Tools, wie Power BI, unterstützen dabei, indem die Erkenntnisse des Process Minings zentral bereitgestellt und in Verbindung mit den KPIs gebracht werden. In diesem Blogbeitrag stellen wir die Möglichkeiten der Integration von Process Mining in Self-Service Dashboards am Beispiel Power BI und mögliche Erkenntnisse anhand eines Use Cases der Lagerlogistik vor. Dabei gehen wir über Process Discovery hinaus und präsentieren eine Anomalieerkennung, die auffällige Prozessabläufe automatisch identifiziert.
Anwendungsfall: Ursachenforschung und Prozessoptimierung in der Lagerlogistik
Optimierte Prozesse in Logistikzentren sind erfolgsentscheidend, denn Fehler in den Prozessen wirken sich auf die gesamte Supply-Chain aus. Entsprechend spielen Root Cause Analyse und Prozessoptimierung eine zentrale Rolle und können durch Datenanalyse unterstützt werden. Häufig existieren bereits ein Data Warehouse (DWH) und ein Reporting Tool, welche Daten aus verschiedenen Informationssystemen zusammentragen und relevante KPIs zusammenstellen bzw. visualisieren. Zentrale Fragestellungen im Use Case der Lagerlogistik sind unter anderem: Wie viele Aufträge sind verspätet oder wie ist die Auslastung einzelner Lagerbereiche?
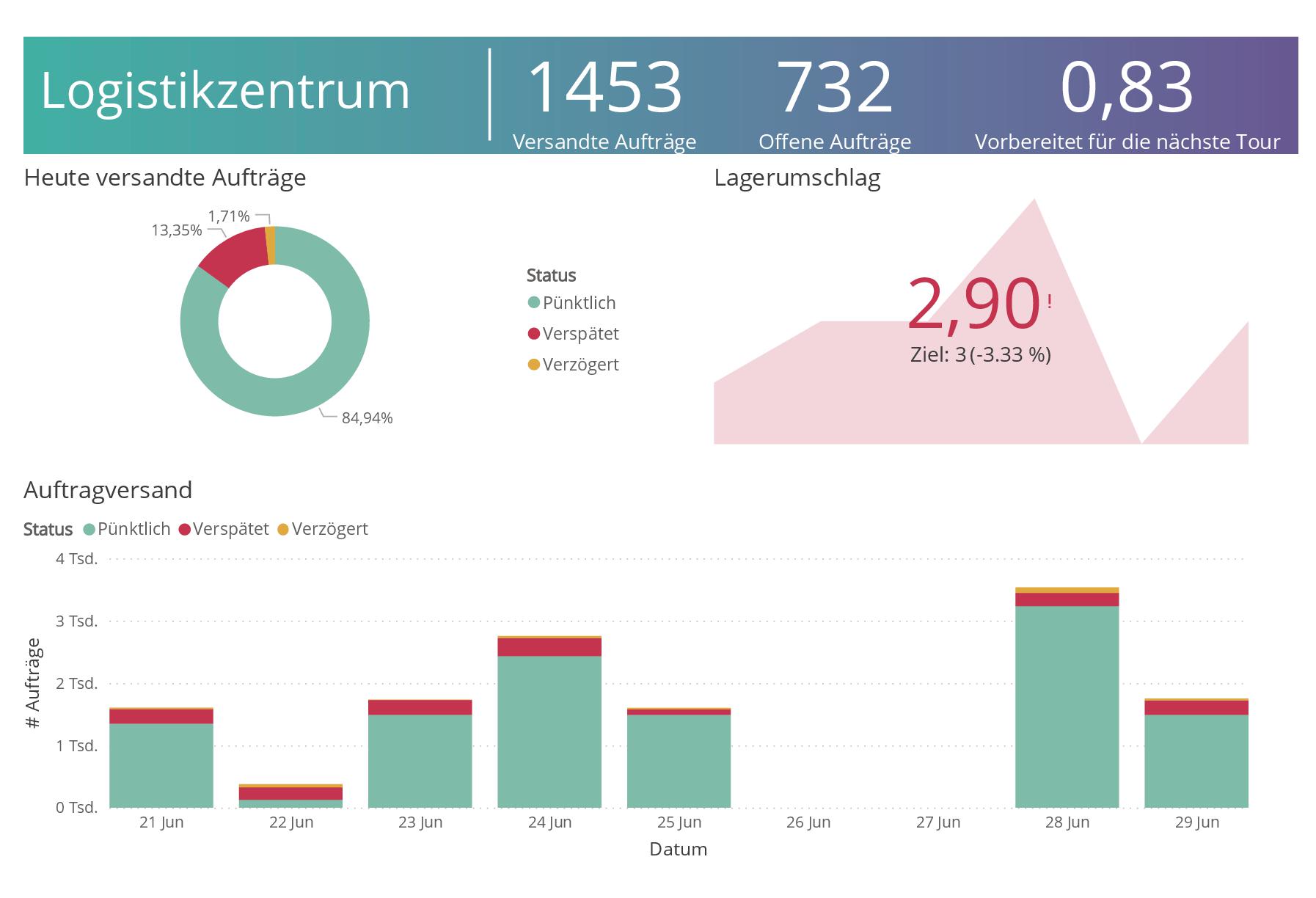
Das beispielhafte Dashboard zeigt einen Auszug der täglichen Analyse eines Logistikzentrums. Es wird deutlich, dass konstant ein hoher Anteil der Aufträge verspätet ausgeliefert wird. Das Reporting spiegelt die aktuelle Situation wider und weist auf Probleme in der Lieferpünktlichkeit hin. Die Frage, was die Ursache für diese Verspätungen ist, bleibt offen. Denkbar sind interne Systemausfälle, technische Probleme oder Prozess Bottlenecks - eventuell sogar Deadlocks. Während Sollprozesse oft detailliert geplant und umgesetzt werden, werden diese in der Realität häufig anders gelebt. Ungeplante Sonderfälle, Ausnahmesituationen oder Prozessschwächen führen zu Workarounds und Abweichungen vom Standardprozess.
Daten, die real gelebte Prozesse aufzeichnen, sind ein wahrer Datenschatz, denn Prozesse sowie ihre Abweichungen, Fehler und Optimierungspotentiale werden sichtbar. Glücklicherweise hinterlassen Geschäftsprozesse, unabhängig von Branche oder Unternehmensgröße, systemübergreifend Spuren, bspw. in Informationssystemen, Logdateien oder über Schnittstellen. So sind Daten über Prozessausführungen in unterschiedlichsten Quellen zu finden. Im Fall der Lagerlogistik sind dies unter anderem Auftragsbuchungen im ERP, Warenbewegungen im Warehouse Management System oder Verladungen im Touren Management System. Process Mining ermöglicht die Nutzung dieser Daten, um Prozesse sichtbar zu machen und Optimierungspotentiale aufzuzeigen.
Process Discovery in Power BI
Betrachten wir ein Logistikzentrum mit den vereinfachten Aktivitäten Warenanlieferung, Einlagerung, Kommissionierung und Warenausgang. Das Ergebnis der Process Discovery ist eine Prozessvisualisierung, die eine Grundlage für Diskussionen mit dem Fachbereich und eine manuelle Ursachenforschung und Anomalieerkennung bietet. Zentrale Fragestellungen für den Einstieg sind:
- Wie sieht der Standardprozess aus? Entspricht dieser dem erwarteten Sollprozess?
- Wie viele Prozessvarianten und Abweichungen existieren?
- Wie lange dauern Prozessabläufe?
Daneben existieren Fragestellungen, die auf die Interpretation der KPIs abzielen und hier einen Einstiegspukt bieten: Wie sehen Prozessabläufe von verspäteten Instanzen aus? Welche Prozessabweichungen sind auffällig?
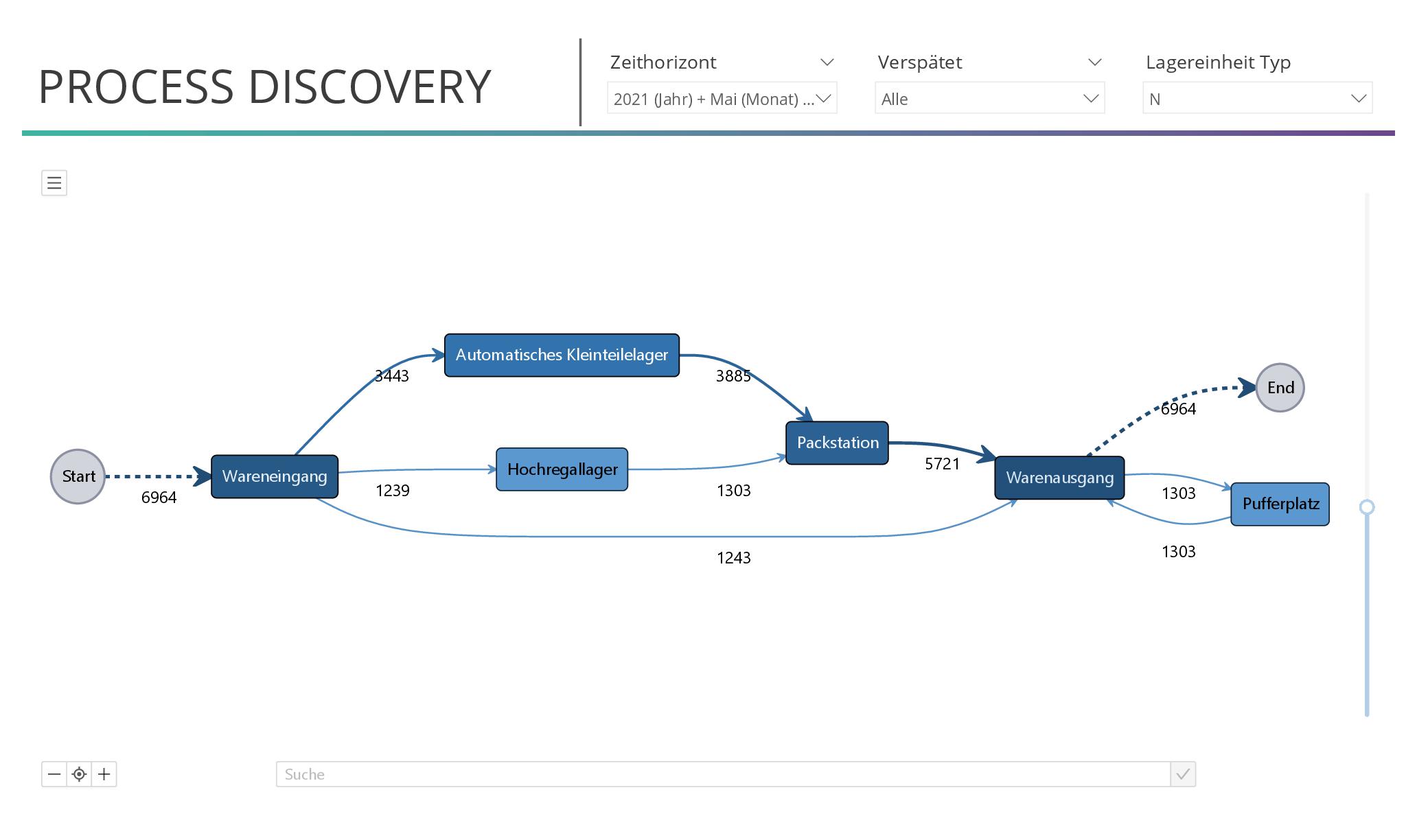
Das Dashboard zeigt die Prozessvisualisierung der Prozessdaten in Power BI. In diesem Beispiel wurde die Visualisierung von process.science verwendet. Mit diesem Dashboard können bereits die ersten Erkenntnisse gewonnen und Prozessabweichungen erkannt werden. Durch interaktive Reaktion des Dashboards und Setzen individueller Filter im oberen Bereich können spezielle Fragen des Fachbereichs beantwortet werden. Die Regulierung des Abstraktionslevels anhand des Schiebereglers auf der rechten Seite ermöglicht zudem sowohl einen Überblick des Standardprozesses als auch die Analyse detaillierter und seltener Prozessabläufe. Daneben kann statt der Häufigkeit die Durchschnittsdauer auf den Kanten angezeigt werden, um beispielsweise potentielle Bottlenecks sichtbar zu machen. Das Wissen des Fachbereichs ist bei der Bewertung erfolgsentscheidend – manche Abweichungen sind wünschenswert, andere weisen auf Fehler hin.
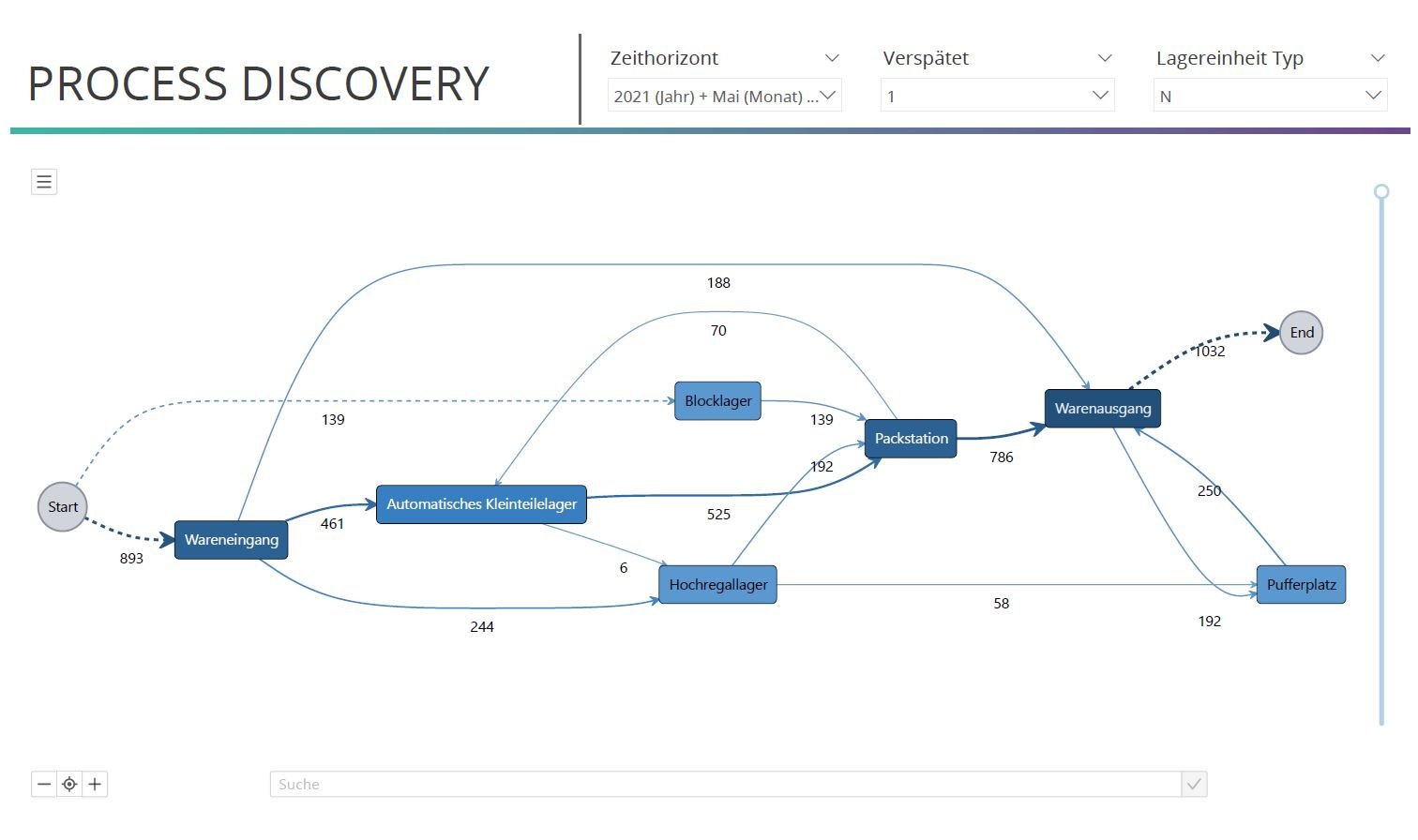
Das Reporting Dashboard des Logistikzentrums hat auf eine hohe Anzahl an Verspätungen hingewiesen. Durch Filterung nach verspäteten Instanzen werden relevante Prozessauffälligkeiten sichtbar. In diesem Fall ist ein hoher Detailgrad gewünscht, um auch seltene Prozessabweichungen zu erkennen. Das wird durch Regulierung des Abstraktionslevels erreicht. Nachfolgend ist ein gefiltertes Dashboard abgebildet, das alle verspäteten Prozessinstanzen beinhaltet. Auffällig ist unter anderem der Prozessfluss vom automatischen Kleinteilelager in das Hochregallager. Dieser Prozessfluss tritt bei verspäteten Prozessinstanzen auf, entspricht aber nicht dem erwarteten Prozess und findet sich nicht bei pünktlichen Instanzen. Ein Blick auf die Lagerzeiten pro Lager im Dashboard zeigt auch, dass hier lange Liegezeiten bei verspäteten Fällen entstehen. Hier ist die Ursache für diese Umlagerung und der Prozess zu hinterfragen.
Automatisierte Anomalieerkennung in Power BI
Während Process Discovery schnell einen Überblick über Standardprozesse, schnell identifizierbare Auffälligkeiten und Prozesszeiten bietet, ist eine detaillierte Anomalieerkennung mit einem hohen manuellen Aufwand verbunden. Künstliche Intelligenz ermöglicht es, automatisch auffällige Prozessinstanzen zu kennzeichnen. Auf diese Weise wird der Fachbereich auf besonders auffällige Prozessinstanzen hingewiesen und kann diese genauer untersuchen. Ein weiterer Vorteil einer automatisierten Anomalieerkennung ist, dass nicht nur manuell erfassbare Informationen des Prozessablaufs integriert werden. Vielmehr ist es möglich, verschiedenste Daten des DWHs zu betrachten, wie Auftragsdetails, Priorisierung oder Artikel, die in dem Prozess bewegt werden. Zudem werden auch Fragestellungen und Prozessauffälligkeiten beleuchtet, mit denen sich zuvor niemand beschäftigt hat oder die nicht durch explizite Filterung deutlich wurden. So werden auch verborgene Fehler und Optimierungspotentiale aufgedeckt.
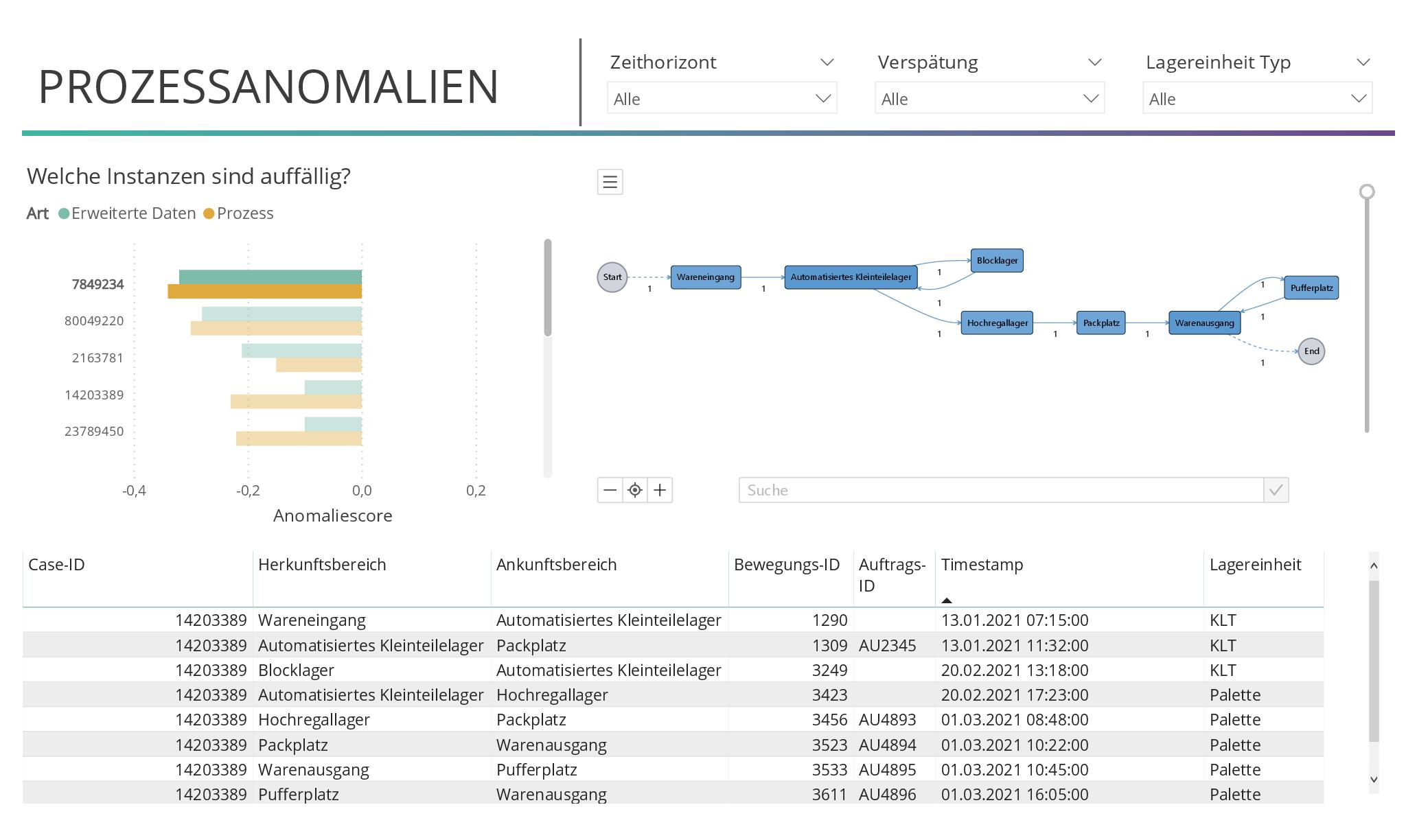
Für die automatische Erkennung von Anomalien wenden wir Verfahren der Künstlichen Intelligenz (hier: mithilfe von Python) an. Im betrachteten Anwendungsfall wurden Anomaliescores mit einem Isolation Forest erzeugt. Negative Scores weisen auf eine Anomalie hin. Je kleiner der Anomaliescore, desto auffälliger ist die Prozessinstanz. Ein mögliches Ergebnis zeigt das abgebildete Dashboard. Die auffälligen Prozessinstanzen werden links angezeigt, sortiert nach ihrem Score. Für jede Prozessinstanz existieren zwei Scores. Der erste bezieht den Prozessfluss ein, wie beispielsweise aufeinander folgende Events oder die Bearbeitungszeit. Der andere Anomaliescore erweitert die Datenbasis um alle im DWH verfügbaren Daten. Diese umfassen unter anderem die Auslastung in Lagerbereichen, die Artikel auf der Lagereinheit sowie Gewicht und Größe dieser oder die Art der Lagereinheit. Während der Anomaliescore des Prozessverlaufs auf auffällige Abläufe hinweist, bietet der erweiterte Anomaliescore eine umfassendere Perspektive. Nach Auswahl einer Prozessinstanz auf dem Dashboard wird der entsprechende Prozessfluss mit seiner Dauer und die einzelnen Prozessschritte mit relevanten Eigenschaften angezeigt. Alle im DWH verfügbaren Daten, die in einen Zusammenhang mit der Prozessinstanz gebracht werden können, stehen hier zur Verfügung und sind integrierbar. Zudem kann hier dann natürlich auch schon nach interessanten Prozessgruppen, wie zum Beispiel verspäteten Prozessen, vorselektiert werden.
Was macht also die hier ausgewählte Anomalie auffällig? Sowohl der Prozessanomaliescore als auch der erweiterte Anomaliescore der Prozessinstanz weisen stark auf eine Anomalie hin. Der rechts abgebildete Prozessgraph der Instanz zeigt, dass die Instanz mehr als 5 Stunden im Pufferbereich gelagert wurde. Einerseits kann dies ein gewünschter Kundenservice sein, da die Ware im gesamten Zeitraum zur Abholung bereitsteht. Andererseits hätten im Batching andere Aufträge höher priorisiert werden können, um Verspätungen dieser Art zu vermeiden. Ein Detailblick auf den Prozessablauf macht deutlich, dass die Instanz aus dem Blocklager gebucht wurde, aber es keine entsprechende Einlagerungsbewegung gibt. Dies weist auf einen Bedien- oder Prozessfehler hin.
Regelmäßiges Prüfen der Anomalien durch den Fachbereich ermöglicht es, Fehler und Probleme schnell zu erkennen und auf diese zu reagieren. Hieraus ergeben sich Prozessoptimierungspotentiale des gesamten Logistikzentrums.
Welche Daten werden für Process Mining und Anomalieerkennung verwendet?
Prozesse hinterlassen in verschiedensten Systemen Spuren. Wenn ein Workflow-Management-System genutzt wird, können Prozessdaten häufig direkt exportiert werden. Ansonsten bieten Informationssysteme, ERP-Systeme, Schnittstellen zu externen Systemen oder Archivsysteme eine hohe Datenmenge, die zu Prozessdaten aufbereitet werden kann (wie Daten für Process Mining aufbereitet werden können, haben wir in diesem Artikel detailliert beschrieben).
Für Process Mining wird ein Event Log mit mindestens einer eindeutigen Case-ID, der Activity und einem Timestamp vorausgesetzt. Bereits für Process Discovery können weitere Informationen relevant sein, wie beispielsweise ein Start- und End-Timestamp, um die Dauer der Prozessschritte einzuschätzen, oder domänenspezifische Prozessmerkmale. Im Use Case der Lagerlogistik wird ein Lagerverwaltungssystem (bspw. Körber/inconso WMS) genutzt. Hieraus können Warenbewegungen und Aufträge exportiert werden. Nachfolgend ist ein Beispiel für ein aufbereitetes Event Log gegeben.
| Case ID | Lagerort | Aktivität | Zeitpunkt Start | Zeitpunkt Ende | Ver-spätung | Auftrags-nummer | Platz |
| 2565869 | Waren-eingang | Waren vereinnahmen | 2021-02-12 08:12 | 2021-02-12 08:25 | 1 | 256589 | Waren-eingang 02 |
| 2565869 | Hochregal-lager | Waren lagern | 2021-02-12 08:38 | 2021-03-02 13:32 | 1 | 256589 | Lagerplatz 32 |
| 2565869 | Kommis-sionierung | Waren kommis-sionieren | 2021-03-02 15:51 | 2021-03-02 14:03 | 1 | 256589 | Packplatz 03 |
| ... |
Im Gegensatz zum Event Log, in dem jede Activity eines Prozesses aufgezeichnet wird, verwendet die Anomalieerkennung eine Zusammenfassung der Prozessinstanz. Welche Informationen wichtig sind, um eine Anomalie zu erkennen, ist domänenspezifisch und wird in Zusammenarbeit mit dem Fachbereich spezifiziert. Eine Perspektive ist die Prozesssicht, d. h. welche Prozessschritte wurden ausgeführt? Aus welchem Lagerbereich stammt die Ware oder wie lange haben Prozessaktivitäten benötigt? Daneben werden domänenspezifische Informationen integriert. Nachfolgend ist beispielhaft ein Datensatz für die Anomalieerkennung gegeben. Als Ergebnis der Anomalieerkennung wird jede Case ID des Datensatzes mit einem Anomaliescore bewertet.
| Case ID | Ursprung | Prozessablauf | Prozessdauer | Anzahl Warenstücke |
| 2565443 | Blocklager | 1 | 14.2 | 5 |
| 2565869 | Automatisches Kleinteilelager | 5 | 1.2 | 3 |
| 3490593 | Automatisches Kleinteilelager | 1 | 2.2 | 1 |
| ... |
Sowohl das Event Log als auch die mit einem Anomaliescore bewerteten Prozessinstanzen müssen an zentraler Stelle gespeichert und mit Power BI verbunden werden. Hierdurch ist eine Integration in existierende und neu Power BI Dashboards möglich.
Fazit: Process Mining in Power BI
Die Visualisierung der Prozesse und der Prozessanomalien in einem Self-Service BI Tool wie Power BI bietet folgende Vorteile:
- Integration in bereits existierende BI Anwendungslandschaft
- Globale Perspektive durch Anbindung an die im DWH aufbereiteten Daten
- Interaktion und Filterung der Daten für Process Mining
- Self-Service und Interaktion mit existierenden Reports, Visualisierungen und Filtern
- Erweiterung existierender Reports um Ergebnisse aus Data Science Projekten (bspw. Anomaliescores)
- Zentrale Bereitstellung von Analyseergebnissen für Stakeholder
- Unabhängiger Technologiestack bei Datenanalysen, da nur der Ergebnisdatensatz integriert wird
In Form eines interaktiven Power BI Dashboards wird ein Überblick über Prozesse, Abweichungen und Details der Prozessinstanzen gegeben. Dem Nutzer stehen so alle Informationen an einem Punkt zur Verfügung – welche Prozessinstanz ist auffällig? Wie sehen Prozessvisualisierung und Prozessdetails hierzu aus? Die durch Power BI ermöglichte globale Sicht auf Prozesse und Anomalien sowie allgemeine Statistiken zu dem Projekt sind der ausschlaggebende Vorteil. Auf diese Weise ist es möglich, Fehler schnell zu erkennen, zu lösen und die Ursachen zu beheben, sodass Prozesse optimiert und Kosten reduziert werden. Wichtig hierbei ist es, die Betrachtung der Prozessanomalien fest in den regelmäßigen Austausch zu integrieren und die Datenbasis regelmäßig zu aktualisieren, bspw. bei einem wöchentlichen Jour Fixe. So werden Auffälligkeiten zeitnah erkannt und die Prozesse fortlaufend optimiert.
Process Mining bietet neben Process Discovery und Anomalieerkennung, noch mehr Potential. Eine mögliche Ergänzung ist Predictive Analytics, um Prozessinstanzen frühzeitig zu bewerten – beispielsweise können so verspätete Aufträge rechtzeitig erkannt und geeignete Mittel ausgelöst werden. Eine Architektur, die eine unabhängige Speicherung der Daten und Anbindung an Power BI ermöglicht, legt hierfür den Grundstein. Hierdurch ist auch bei weitergehenden Analysen der Technologiestack unabhängig und die Dashboards erweiterbar. Die Optimierung von Logistikprozessen ist nur ein Use Case von Process Mining, verschiedenste Branchen und Anwendungsfälle können von Process Mining profitieren.
Haben wir Ihr Interesse geweckt? Im Rahmen eines Proof-Of-Concept zu Process Mining versprechen wir mindestens eine automatisierte Anomalieerkennung zu liefern. Sprechen Sie uns an!

zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



