

Warenbewegungen sind der essentielle Bestandteil logistischer Wertschöpfung. Eine Warenbewegung ist immer eine Prozessinstanz, die mehr oder weniger dem Sollprozess entspricht. Dieses Mehr-oder-Weniger abzubilden und zu verstehen ist der heilige Gral logistischer Optimierung. Für Logistikzentren eines Kunden haben wir die Fragestellung nach dem Mehr-oder-Weniger mittels Process Mining beantwortet. Dieser Beitrag zeigt am Beispiel logistischer Warenbewegungen, wie Process Mining in Apromore funktioniert, warum es für explorative Analysen geeignet ist und wo die Grenzen liegen.
Welche Probleme werden adressiert?
Der Großteil der Prozessinstanzen wird dem geplanten Sollprozess entsprechen, daneben wird es immer Abweichungen geben – das Mehr-oder-Weniger. Wie hoch der Anteil der Sollprozessinstanzen ist, wie viele und vor allem welche Abweichungen vom Sollprozess existieren oder gar gängige Praxis sind, sollte transparent sein. Fehlbedienungen, verstecktes Prozesswissen, Shortcuts und intransparente Prozessschritte bieten Chancen zur Prozessverbesserung und Kostenreduktion. Zudem werden Fehler erkannt.
In einem Logistikzentrum wird Ware angeliefert, bis zum Kundenauftrag zwischengelagert, kommissioniert und verpackt und schlussendlich im Warenausgang versandt. Process Mining auf Basis der in IT-Systemen verbuchten Warenbewegungen wird diesen Prozess finden – und zudem die Abweichungen.
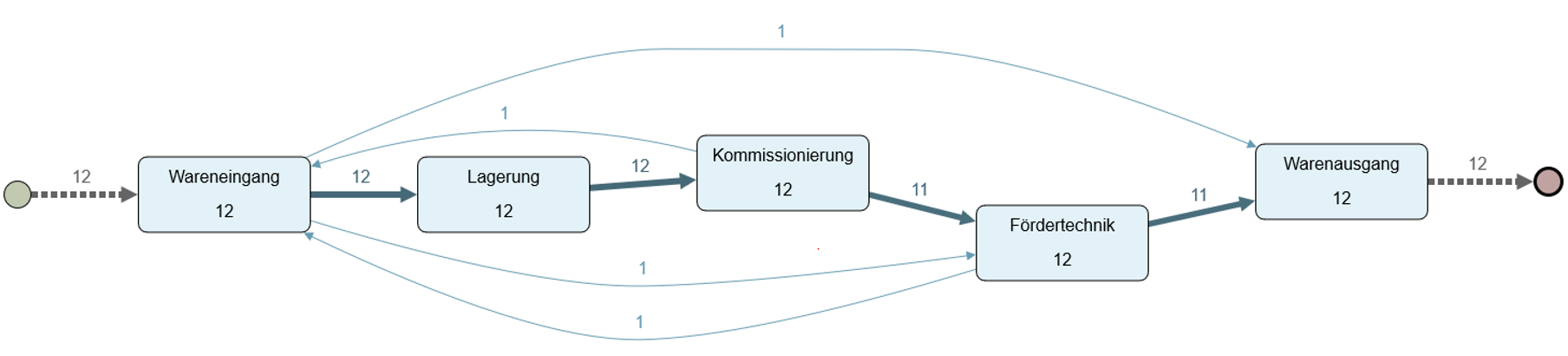
Abbildung 1 zeigt ein Prozessdiagramm aus Apromore. Die Stärke der Sequenzen ist abhängig der Anzahl durchgeführter Warenbewegungen. Der Sollprozess ist auf Basis der 12 Prozessinstanzen deutlich zu sehen. Allerdings sind auch Abweichungen klar identifiziert und visualisiert worden. Die Ursachenanalyse für Abweichungen wird mittels individueller Datenanalyse in den Datenquellen durchgeführt, in diesem Fall dem Lagerverwaltungssystem.
Wofür eignet sich Apromore?
Unsere Analysen verwenden die Community Edition von Apromore. Die Bewegungsdaten wurden vorher mittels individuellem Data Mining als Prozessinstanzen aufbereitet. Apromore zeigt schnell seine Stärken:
- Als Webtool ist es perfekt für kollaboratives Arbeiten im Team. Derselbe Datensatz kann von mehreren Personen betrachtet werden. Ergebnisse sind allen Benutzern zugänglich. Aufgabenteilung und Pairing werden perfekt unterstützt.
- Apromore ist zudem wie gemacht für explorative Analysen. Prozessdaten können als CSV hochgeladen und schnell visualisiert werden. Eine Skalierung der Details zeigt die realen Kernprozesse genauso schnell wie die detaillierten Abweichungen.
- Schieberegler der einfachen Benutzeroberfläche ermöglichen schnell und einfach Standardprozesse und Abweichungen zu finden. Apromore ist ausgesprochen interaktiv.
- Es werden Filter unterstützt, die gezielte Fragestellungen ermöglichen, z. B.: Zeige nur Prozesse mit dem Knoten "Kommissionierung" oder zeige Prozesse nur "von-X-nach-Y".
- Ist ein Detailgrad gefunden, dann zeigt Apromore alle Prozessinstanzen, die diesem Prozessdetail folgen.
Mit zunehmenden Prozesswissen und entsprechenden Fragestellungen werden allerdings auch Grenzen schnell erreicht.
- Prozesse sind grundsätzlich sequentiell. Nebenläufigkeit oder gar Parallelität wird nicht ersichtlich. Eine Schwäche fast aller Tools.
- Innerhalb eines Prozessmodells ist es nicht möglich verschiedene Aggregationslevel, ähnlich der Gruppierungen in SQL, abzubilden.
- Prozessinstanzen können nicht zusammengeführt oder aufgesplittet werden.
- Sehr großen Datenmengen, wie in logistischen Prozessen üblich, führen schnell zu sehr langen Ladezeiten.
- Merkmale der Prozesse können zwar gefiltert, aber nicht visualisiert werden. Ideal wäre eine Funktion wie: Markiere alle Prozessinstanzen mit dem Merkmal "Verspätet = True".
Wie müssen die Daten aufbereitet sein?
In Apromore ist die Datengrundlage eine Tabelle, wobei jede Zeile einen Prozessschritt darstellt. Kernpunkt der aufbereiteten Prozessdaten ist die ProzessID: Jede Warenbewegung von Wareneingang bis Warenausgang bzw. jede Prozessinstanz benötigt eine durchgehende, eindeutige Identifizierung, welche mehrere Zeilen miteinander in Verbindung setzt. Zudem benötigt jede Zeile – also die Aktivität – eine Startzeit und Endzeit. Weitere Spalten können als Merkmale, sogenannte Events, importiert werden und bieten detaillierte Informationen über die fachlichen Fragestellungen.
|
Nr.
|
ProzessID
|
Lagerort
|
Aktivität
|
Start
|
Ende
|
Verspätet
|
Auftragsnummer
|
...
|
|---|---|---|---|---|---|---|---|---|
| 1 | pid-0 | WE | Wareneingang | 10:00 | 10:01 | false | 2021-001 | |
| 2 | pid-0 | L1 | Lagerung | 10:02 | 11:58 | false | 2021-001 | |
| 3 | pid-0 | PP | Kommissionierung | 12:00 | 12:03 | false | 2021-001 | |
| 4 | pid-0 | FT13 | Fördertechnik | 12:04 | 12:06 | false | 2021-001 | |
| 5 | pid-0 | TO3 | Warenausgang | 12:07 | 12:15 | false | 2021-001 | |
| .. | ... | ... | … | ... | ... | ... | ... | … |
| 7 | pid-10 | WE | Wareneingang | 14:20 | 14:35 | true | 2021-001 | |
| 8 | pid-10 | WE | Wareneingang | 14:21 | 14:45 | true | 2021-001 | |
| 9 | pid-10 | L3 | Lagerung | 14:37 | 15:00 | true | 2021-001 | |
| 10 | pid-10 | PP | Kommissionierung | 15:01 | 15:07 | true | 2021-001 | |
| 11 | pid-10 | FT21 | Fördertechnik | 15:08 | 15:13 | true | 2021-001 | |
| 12 | pid-10 | TO4 | Warenausgang | 15:14 | 15:45 | true | 2021-001 |
Eine denormalisierte Tabelle mit einer Warenbewegung pro Zeile: Die Prozessreihenfolge sortiert sich zwingend über Zeiten. Daher werden die Warenbewegungen in den Zeilen 7 und 8 nicht als Vorbewegung von Zeile 9 gewertet, sondern als Sequenz der Prozessreihenfolge 7-8-9 interpretiert. Die Ursachenanalyse in den Datenquellen kann über die Merkmale – Auftragsnummer, etc. – erfolgen.
Wie werden Prozesse erstellt und Erkenntnisse gewonnen?
In nur vier Schritten kann ein Prozess in Apromore erstellt und erste Erkenntnisse gewonnen werden.
- Import: Die Tabelle wird als Text- oder CSV-Datei importiert. Ist die Datei hochgeladen, zeigt Apromore einen Editor, in dem die Spalten als eine ProzessID, Zeitpunkte, eine Aktivität oder Events markiert werden.
- Visualisierung und Skalierung: Ist der Datensatz importiert, werden die gefundenen Prozesse sofort visualisiert. Nach dem visualisierten Prozess widmet sich die Aufmerksamkeit schnell den Schiebereglern am oberen Rand. Arcs steht auf 10% - Es werden nur die 10% am häufigsten genutzten Prozesspfade angezeigt. Ein paar Versuche mit den Schiebereglern vermitteln intuitiv deren Nutzen, der Abstraktionsgrad der Visualisierung schwankt. Mit abnehmender Abstraktion werden Abweichungen vom Sollprozess sichtbar. Ein hoher Abstraktionsgrad zeigt die häufigsten Prozessverläufe, den Sollprozess – hoffentlich.
Anstatt der im Importeditor konfigurierten Aktivitäten sind links im Menü unter "Perspektive" auch Events wählbar. Unterschiedliche Perspektiven ermöglichen schnell ein Prozessverständnis. Unterschiedliche Fragestellungen – Materialfluss durch das Lager, Reihenfolge von ausgeführter Aktivitäten – lassen sich grafisch zügig durchdenken. - Anwenden von Filtern: Abstraktionsgrad und Perspektiven bieten schnell Einblicke in die Regelprozesse und Abweichungen. Allerdings ermöglicht dies bestenfalls begrenzte Erkenntnisse. Filter für gezielte Prozesseigenschaften werden relevant. Diese bietet Apromore im Iconmenü und der Umgang damit erfordert etwas Übung. Filterung auf Prozessinstanzen, die eine bestimmte Aktivität oder Event enthalten, auf Zeiträume oder auf aufeinander folgende Aktivitäten können gewählt werden. Zudem lassen sich Filter kombinieren und exklusiv oder inklusiv anwenden. Grundsätzlich sind die Filteroptionen ausreichend für gezielte Fragestellungen: Wie verlaufen Prozessverläufe ohne Kommissionierung? Allerdings gibt es hier und da kleinere Einschränkungen. So lassen sich "folgt direkt auf" und "folgt irgendwann auf" ausschließlich auf Aktivitäten anwenden. Werden diese Filter für Merkmale bzw. Events benötigt, dann ist ein neuer Import mit anderer Konfiguration nötig.
- Analyse von Prozessinstanzen und Events: Liefert eine Auswahl einer Abstraktion mit oder ohne Filter interessante Prozesse, dann werden die konkreten Prozessinstanzen relevant. Neben den Schiebereglern finden sich diese unter "Cases". Es werden alle Prozessinstanzen als Tabelle gelistet, die zur aktuellen Auswahl führen. Die Selektion einzelner Prozessinstanzen zeigt nun den konkreten Prozessverlauf als Prozessdiagramm.
Wo liegen die Grenzen und welche Lösungen gibt es?
Wie bereits erwähnt, werden Prozessinstanzen zwingend sequentiell interpretiert. Reale Prozessinstanzen bzw. Warenbewegungen eines Auftrags erfolgen dagegen auch mal nebenläufig – zwei Wareneingänge desselben Artikels werden auf dieselbe Palette gepackt. Zudem können die Ladeeinheiten in mehreren Prozessinstanzen beteiligt sein. Apromore – und viele weitere Process Mining Tools – stellen solche Prozesse stets zeitlich sequentiell dar.
Die Prozessinstanz "pid-10" des Prozessbeispiels aus Abbildung 2 besitzt eine solche Konstellation. Die Vereinigungen werden sequentiell nach Zeitpunkten visualisiert. Die Sequenz dazu ist als "instant" ausgewiesen. Das ist zwar nicht zwingend falsch, schließt allerdings einen tatsächlichen sequentiellen Warenfluss nicht aus.

Korrekt wäre eine Visualisierung der folgenden Abbildung.

Technisch werden diese Konstellationen als Merges / Splits bezeichnet. Alternative Tools bieten zwar Lösungsoptionen, jedoch gerieten wir immer wieder schnell an domänenspezifische Fragestellungen, die die Bordmittel von Standard-Tools nicht ohne weiteres beantworten.
Eine Empfehlung für Process Mining
Wurden die Prozessdaten in die benötigte Tabellenstruktur inklusive einer ProzessID transformiert, dann ist die Community Edition von Apromore sehr gut für exploratives Arbeiten geeignet. Die Visualisierung ermöglicht schnell Einblicke in die Prozesse und ob diese korrekt aufbereitet wurden. Erste domänenspezifische Fragestellungen sind zudem schnell beantwortet, etwa wie viele Prozessinstanzen dem Standardprozess folgen, wo Abweichungen zu finden sind und welche ProzessIDs daran beteiligt sind. Mit diesen Informationen kann im Quellsystem die Ursachenforschung beginnen.
Die Datenaufbereitung ist immer domänenspezifisch – hier Logistik – und erfordert eine individuelle Aufbereitung der Daten. In der Regel empfiehlt sich dies mittels Python oder einer Data Science-Sprache der Wahl umzusetzen. So sind individuelle Fragen später schneller analysiert und wichtige weitere Schritte – Prognosen und Anomalieerkennung – bereits vorbereitet.
Interessiert an mehr Methoden? Wir bieten ein Seminar Process Mining für Prozessverantwortliche an.
Ronja Köhling ist als Beraterin bei der viadee IT-Unternehmensberatung tätig. Ihre Schwerpunkte sind Künstliche Intelligenz und Data Mining.
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



