

In nahezu allen größeren Software-Projekten müssen auch problematische Design- und Implementierungsentscheidungen getroffen werden. Diese verzögern und erschweren sowohl die Wartung als auch die Weiterentwicklung und werden daher häufig als technische Schuld bezeichnet (Cunningham, 1992). Auch bei gut geschriebener Software muss Aufwand für Wartung eingeplant werden.
Desirability Score
Um die technischen Schulden zu verringern, müssen diese zunächst identifiziert werden. Das kann für einen Teil der technischen Schulden durch die Identifizierung von Code Smells geschehen: Dies sind Stellen im Quellcode, die offensichtlich problematisch sind. Ein Beispiel hierfür ist ein public static non-final Feld im Java-Code. Dieses kann unkontrolliert von überall modifiziert werden und somit die Threadsicherheit gefährden. Der Zugriff sollte im Allgemeinen gekapselt werden, sodass eine kontrollierte Synchronisierung stattfinden kann.Zur Priorisierung und als Alternative bzw. Ergänzung zur manuellen Auswahl hierzu kann eine automatisch errechenbare Metrik definiert werden, die angibt, wie wünschenswert es ist, dass ein bestimmtes Issue behoben wird: der Desirability Score. Dieser setzt sich zusammen aus verschiedenen unabhängigen Einzelkomponenten, die jeweils die Wichtigkeit eines Issues mit dieser Eigenschaft über einen Issue ohne diese Eigenschaft angeben.
Beispielsweise sind Security-Issues pauschal wichtiger als Nicht-Security-Issues. Eine andere relevante Eigenschaft ist das Alter eines Issues: Neue sollten bevorzugt behoben werden, da somit ein Lerneffekt eintritt und der Code potentiell noch im Gedächtnis ist.

Weiterhin interessant ist auch die Position von Code Smells in der Code-Basis: Wird die beinhaltende Klasse zentral verwendet oder als API bereitgestellt, könnten Programmierer häufiger über das Issue stolpern. Solche Probleme sollten demzufolge eher behoben werden, als Issues in Klassen mit selten verwendeten Spezialfunktionen.
Die letzte hier erwähnte, jedoch potentiell wichtigste, Eigenschaft schlägt in eine ähnliche Bresche: Wie häufig wird die Datei in der Zukunft bearbeitet? Die meisten Issues sind vor allem beim Bearbeiten der Datei problematisch, da hier potenziell neue Missverständnisse entstehen oder Code für Zwecke genutzt wird, auf die er nicht vorbereitet sein könnte. Demzufolge sind inhaltlich stabile Dateien weniger relevant für eine Software-Wartung, als solche, für die sich die nächste Änderung schon abzeichnet. Ist eine Predictive Maintenance für Software möglich?
Da sich das Warten auf einen Zeitreisenden mit ebendieser Information als unzuverlässig herausgestellt hat [Beleg erforderlich], kann alternativ ein Machine-Learning Modell erstellt werden, welches die Commit-Zahl pro Datei vorhersagt. Dies ist im Detail weiter unten beschrieben.
Der Desirability-Score und die Erstellung der Vorhersagemodelle sind als REST-Schnittstelle implementiert, und sollen demnächst in SonarQuest integriert werden.
Vorhersagen von Code-Änderungen
Die Vorhersage der Änderungen in einem Git-Repository ist zunächst auf Java-Dateien zugeschnitten, kann jedoch prinzipiell verallgemeinert werden. Die untenstehende Grafik zeigt die Vorhersagequalität eines derartigen Modells für den H2O-Quellcode.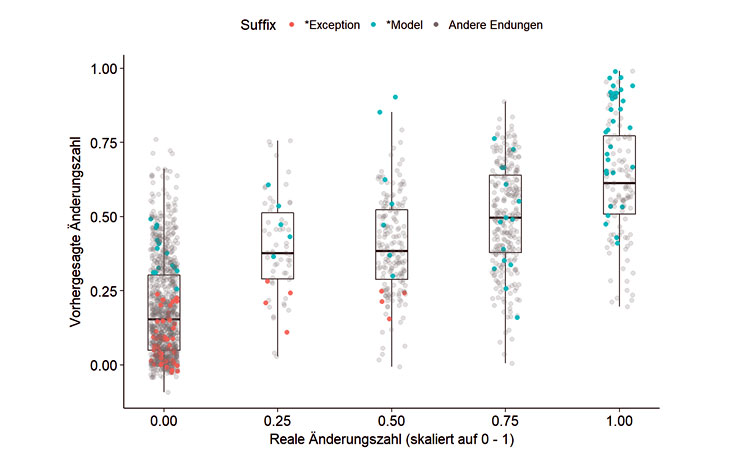
Die meisten Dateien / Klassen werden nicht geändert, und auch klar als solche erkannt (unten links). Mit steigender Änderungszahl in der Realität werden die Klassen dann auch tendenziell als häufiger geändert vorhergesagt.
Der Prozess der Änderungsvorhersage ist für einzelne Git-Repositories ausgelegt, es wird jeweils ein einzelnes Machine-Learning Modell gelernt. Dies ist eine bewusste Entscheidung, denn die Idee, die gleichen Zusammenhänge in vielen Projekten in gleicher Stärke wiederzufinden, mussten wir verwerfen.
In der aktuellen Implementierung erfolgt dies mit H2O, einem Open-Source Machine Learning-Toolkit. Genutzt wird hierbei ein Gradient-Boosting-Verfahren, da es konstant die besten Ergebnisse liefert. Lediglich in seltenen Fällen wird es nach exzessiver Trainingszeit von Deep Learning in den Schatten gestellt.
Für diese Vorhersage werden viele verschiedene Eingabefeatures genutzt, von welchen automatisch die besten für das aktuelle Repository gewählt werden.
Aus einer Stichproben-Analyse von internen viadee-Projekten sowie 116 Java-Projekten auf Github wie beispielsweise Apache Kafka, Selenium oder Spring, zeigen sich einige Features dabei als besonders häufig relevant für eine Vorhersage von Änderungshäufigkeiten:
- Das Package der Klasse ist konstant das wichtigste Feature überhaupt. Es gibt Packages, die häufig geändert werden – viele davon enthalten Geschäftslogik. Im Gegensatz dazu bleiben andere Packages unverändert, weil etwa die Entwicklung abgeschlossen ist.
- Das erste und letzte Wort des Klassennamens hat ähnliche Bedeutung: In der obigen Grafik werden Klassen, welche auf *Model (blau) enden, häufig geändert. Im Gegensatz dazu ist eine *Exception (rot) eher statisch.
- Die Zahl der Änderungen in der Vergangenheit ist auch ein wichtiger Indikator: Häufig geänderte Klassen werden vermutlich wieder geändert. Das gilt insbesondere, wenn dies in der jüngeren Vergangenheit geschah.
- Eine hohe zyklomatische Komplexität der Klasse deutet auch auf häufiger geänderte Klassen hin. Dies könnte damit zu begründen sein, dass Edits an komplexen Klassen mehr Nacharbeit fordern.
- Die Anzahl der Abhängigkeiten ist weiterhin relevant: Klassen, die von vielen anderen Klassen abhängen, werden häufiger geändert. Die Begründung hierfür ist simpel: Jede Änderung an Methodensignaturen oder Verhalten einer Klasse erfordert Änderungen an allen aufrufenden Stellen.
- Die Größe der Klasse – repräsentiert durch die Anzahl der Zeilen und Methoden – hat auch Einfluss: eine zufällige Änderung trifft mit höherer Wahrscheinlichkeit Klassen mit mehr Inhalt.
Hinweis: Der Artikel fasst im Wesentlichen Erkenntnisse aus Literatur-Recherche, eigenen Experimenten und Experten-Interviews aus der Master-Arbeit von Hauke Husstedt an der WWU Münster 2018 zusammen.
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



