
Operator in Kubernetes sind allgegenwärtig und unverzichtbar. Doch was sind Operator und wie können wir sie nutzen, um das eigene Cluster um Funktionalität zu erweitern? Wie nutzt Kubernetes dieses Pattern, um z.B. Pods aus Jobs zu erzeugen? Wir führen durch die Begrifflichkeiten und erklären, wie Operator, Controller und Custom Resources zusammenspielen. Zudem stellen wir verschiedene Frameworks vor, mit denen eigene Controller entwickelt werden können, wodurch sich das Management des Clusters vereinfacht.
Einführung
Kubernetes bietet eine leistungsstarke API für das Management des Clusters, die unter anderem Pods, Jobs und Deployments zum Bereitstellen von Anwendungen umfasst. In vielen Fällen reicht die Standard-API jedoch nicht aus und es werden weitere Abstraktionsstufen oder zusätzliche Funktionalitäten benötigt. Das Kubernetes Operator Pattern schafft Abhilfe, indem es die Definition und Verwaltung von Anwendungen und Services als eigenständige Objekte (Custom Resources) in Kubernetes ermöglicht. Hierdurch wird Wiederverwendbarkeit und eine Verringerung der Gesamtkomplexität erreicht.
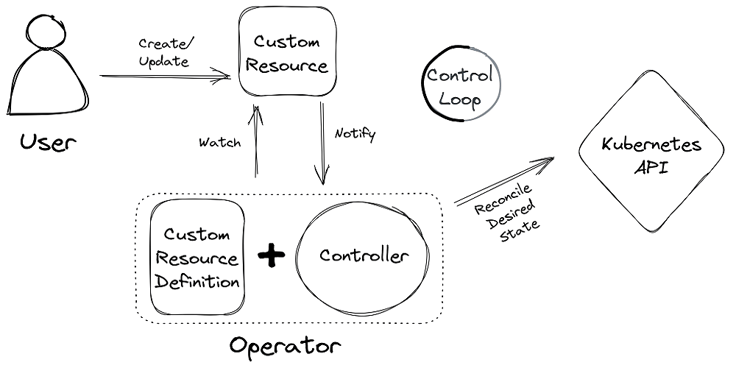
Die Umsetzung des Operator Patterns wird durch domänenspezifische Controller realisiert, die den Lebenszyklus einer Custom Resource überwachen. Ein solcher Controller gleicht stetig den aktuellen mit dem gewünschten Zustand des Clusters ab, um notwendige Veränderungen am Cluster vorzunehmen. Dieses Konzept wird als Control Loop oder Reconciliation Loop bezeichnet. Das Konzept ist in der untenstehenden Grafik verdeutlicht.
Kubernetes selbst nutzt dieses Pattern für seine Core APIs: wird bspw. die Ressource vom Typ Job erstellt, sorgt der Job-Controller des kube-controller-managers für die Erstellung entsprechender Pods. Wie Kubernetes auch können wir Custom Resources definieren und eigene Controller schreiben, die deklarative Resources übersetzen. In diesem Blogbeitrag werden wir uns detaillierter mit dem Operator Pattern und seinen Bestandteilen, der Definition von Custom Resources und Controllern sowie unterstützenden Frameworks beschäftigen.
Anwendungsfälle und Vorteile
Typischerweise findet das Operator Pattern Einsatz in der Verwaltung komplexer Anwendungen, die viele weitere Ressourcen ableiten oder bei spezialisierten, wiederverwendbaren und konfigurierbaren Services, wie ArgoCD, Istio oder KNative. Als Beispiel für die Erstellung und Einsatz eines Operators in Kubernetes könnte so ein Datenbank-Operator genannt werden, der die Bereitstellung, Verwaltung und Wartung einer Datenbank automatisiert. Dieser könnte selbstständig eine neue Datenbank-Instanz bereitstellen, wenn eine Custom Resource vom Typ "Database" erstellt wird. Die Eigenschaften der Datenbank, wie die Größe des Speichers oder die Anzahl der Replikate, würden in der Custom Resource definiert werden. Mittels weiterer Custom Resources könnten dann weitere Features implementiert werden, wie bspw. die Erstellung eines Backups bei Anlage einer Custom Resource vom Typ "Backup", dem Wiederherstellen der Datenbank, bei Anlage eines "Restores", usw.
Die Vorteile im Management des Clusters durch die Nutzung des Operator Patterns werden anhand des Beispiels deutlich: wir erreichen Wiederverwendbarkeit und Automatisierung. So können wir, je nach Anwendungsfall, die wiederholte Definition von mehreren Objekten durch eine einzige Custom Resource ablösen. Diese wird dann durch den Controller automatisiert verarbeitet, was widerrum die Geschwindigkeit des Entwicklung erhöht und die Fehleranfälligkeit unseres Clusters minimiert. Zudem bietet uns dieses Pattern die Möglichkeit der standardisierten Erweiterbarkeit der Kubernetes-API, die kompatibel in allen Kubernetes Clustern einsetzbar ist. Wir erweitern also nicht nur unser bzw. ein Cluster, sondern sind in der Lage dasselbe Operator Pattern in beliebigen Clustern einzusetzen. Zuletzt können wir durch das Pattern die Sicherheit unseres Clusters erhöhen. Anwendungen und Nutzer:innen benötigen fortan keine direkten Berechtigungen mehr (müssen in unserem Beispiel also keinen Zugriff auf die Datenbank besitzen), sondern müssen lediglich berechtigt sein, unsere Custom Resource zu erstellen. Der Controller besitzt nun alleinig alle notwendigen Berechtigungen.
Jedoch sollte vor der Erstellung eines Operators stets abgewogen werden, ob die hierdurch entstehende Komplexität verhältnismäßig ist. Denn häufig kann die erwünschte Funktionalität einfacher mit standard Kubernetes-Ressourcen, -Konfigurationen und -Tools erreicht werden. Hier würde ein Operator unnötige Komplexität erzeugen. Außerdem gilt es zu beachten, dass das Erstellen und Pflegen eines Operators spezialisiertes Wissen und Zeit erfordert. Wenn nicht über die erforderliche Expertise oder Ressourcen verfügt wird, kann es besser sein, vorhandene Operator oder andere Lösungen zu verwenden.
Custom Resources und deren Definition
Eine Custom Resource in Kubernetes beschreibt eine Ressource, die über die Kubernetes API angelegt werden kann. Sie muss - wie alle Kubernetes Objekte - bestimmte Felder wie apiVersion, kind und metadata enthalten. Weitere Felder können durch Entwickler:innen frei bestimmt werden, um den spezifischen Anwendungsfall zu beschreiben. Ein Beispiel für eine Custom Resource soll unsere "MyApp" sein, die spezielle Eigenschaften wie die Anzahl der replizierten Pods unserer Anwendung vorgibt:
Bevor eine solche Ressource erstellt werden kann, muss sie jedoch erst mittels einer Custom Resource Definition (CRD) definiert und so dem Cluster bekanntgemacht werden. Eine CRD beschreibt lediglich die Metadaten der Ressource, einschließlich des Namens und des Schemas, das bei Erstellung der Ressourcen überprüft wird. Logik implementiert sie keine - dafür ist der Controller zuständig.
Die Definition einer CRD kann durch die Angabe eines Schemas lang und unübersichtlich werden. Daher empfiehlt es sich, diese Definition generieren zu lassen. Einige der Frameworks, die uns bei der Erstellung von Operators unterstützen, können die CRD automatisiert erstellen. Dazu später mehr.
Operator from Scratch? Besser nicht!
Wurde die oben aufgeführte CRD angelegt, können Ressourcen vom Typ MyApp erstellt werden. Jedoch würde das ohne Effekt bleiben: zwar befindet sich dann unsere MyApp-Ressource im Cluster, es gibt aber keine Komponente, die sich hierfür interessieren oder entsprechend ihrer Definition handeln würde. Um das zu ändern müssen wir einen Operator erstellen, der den Lebenszyklus unserer MyApp-Objekte überwacht.
Hierfür empfiehlt es sich, auf eines der verschiedenen Frameworks zur Erstellung von Operators zurückzugreifen. Diese vereinfachen die Erstellung und Verwaltung von Operators enorm. Zwei bekannte Frameworks möchten wir kurz vorstellen: Kubebuilder und Metacontroller.
Kubebuilder
Kubebuilder ermöglicht die Entwicklung von performanten Operators mit einer einfachen CLI bzw. API, basierend auf der Programmiersprache Go. Zusammen mit dem auf ihm aufbauenden Operator Framework gehört es zu den beliebtesten und meistgenutzten Operator-Tools
Um mit Kubebuilder einen Operator zu erstellen, müssen wir lediglich unsere MyApp mit Go-Structs beschreiben und die Control Loop implementieren; der Rest bzw. das Programmgerüst wird uns von Kubebuilder vorgegeben. Im Falle unserer MyApp könnte das wie folgt aussehen:
Anhand dieser MyApp-Definition und den typisierten Go-Structs generiert Kubebuilder nun unsere CRD und das Schema. Dies geschieht mittels der mitgelieferten Makefile bzw. mit dem Terminal-Befehl make manifests.
Nun müssen wir die Control Loop implementieren. Dies geschieht innerhalb der Reconcile-Methode. Sie enthält die gesamte Logik unseres Operators und verarbeitet unser oben definiertes MyApp-Struct bzw. leitet zu erzeugende Ressourcen ab.
Hierfür wird fast immer das gleiche Schema genutzt: wir erhalten über die Kubernetes API ein Objekt, für das wir uns interessieren, definieren auf dessen Grundlage neue Ressourcen und erstellen bzw. updaten sie.
Sind Definition und Reconcile-Methode definiert, bietet uns das Framework eine passende Dockerfile und alle manifest-Dateien, um das Image zu bauen und den Operator im Cluster zu deployen. Zudem bietet uns das Framework ein ausgezeichnetes Testing-Environment, mit dem wir den Controller ausgiebig testen können, bevor er im Cluster aktiv wird.
Metacontroller
Metacontroller ermöglicht die Erstellung von Operators durch die Verwendung von Kubernetes-Webhooks. Entwickler:innen müssen also keine eigene Control Loop zu schreiben, sondern lediglich einen Web-Service bereitstellen, der auf Anfragen des Metacontrollers mit Objekten im JSON-Format antwortet. Ein Vorteil von Metacontroller ist, dass es die Entwicklung von Operatoren vereinfacht und es Entwickler:innen ermöglicht, schnell und in jeder beliebigen Programmiersprache auf Änderungen in ihren Anwendungen zu reagieren.
Für die Implementierung eines Operators muss die Metacontroller-Anwendung zunächst im Cluster installiert werden. Danach wird ihr mitgeteilt, welche Ressource von unserem Controller verarbeitet wird und unter welcher Adresse er erreichbar ist. Dies wird wie folgt definiert:
Anschließend liegt es an uns einen Service bereitzustellen, der unter der angegebenen URL erreichbar ist und auf die Anfrage des Metacontrollers mit Objekten antwortet, die aus der jeweiligen MyApp-Ressource abgeleitet werden sollen. Ein simpler Python Web Server könnte diese Anforderung bspw. mit wenigen Zeilen Code umsetzen:
Der anfragende Metacontroller wird die Antwort verwalten und entsprechend im Cluster propagieren. Somit müssen wir keine API requests für das Erstellen oder Updaten von Ressourcen durchführen.
Fazit
Das Operator Pattern in Kubernetes ermöglicht es Entwickler:innen, ihre Anwendungen und Services als Custom Resources in Kubernetes zu definieren und ihren Lebenszyklus automatisch verwalten zu lassen. Dies führt zu einem vereinfachten und sichereren Management des Clusters, einer beschleunigten Konfiguration und Überwachung von Anwendungen, der Wiederverwendung von komplexen Funktionalitäten und einer Minimierung von benötigten Berechtigungen im Cluster.
Jedoch verlagert sich ein Teil der Komplexität in die Umsetzung des Operator Patterns bzw. der Controller. Daher empfiehlt es sich eines der verschiedenen Frameworks zu nutzen. Mit Kubebuilder und Metacontroller haben wir zwei mögliche Kandidaten vorgestellt, die unterschiedliche Ansätze verfolgen: Während Kubebuilder einen eher strukturiertes und striktes Vorhergehen mit best-practices fördert, bietet Metacontroller Flexibilität und Abstraktion. Im Kern haben jedoch beide das gleiche Ziel: das automatisierte Ableiten neuer Ressourcen aus einer von uns definierten, domänenspezifischen Ressource zur Erweiterung der Kubernetes API.
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



