
Wir haben eine neue Version von unserer OpenSource-Lösung für Machine Learning auf Geschäftsprozessdaten (bpmn.ai) in Github released. In der Version 1.1.0, die jetzt auch im Maven Repository zur Verfügung steht, haben wir, neben kleineren Verbesserungen, vor allem die Datentransformations-Pipeline refactored.
In bpmn.ai kann die Pipeline zur Datentransformation frei konfiguriert und durch eigene Schritte erweitert werden. In der Version 1.0.0 bestanden zwischen den einzelnen enthaltenen Schritten teilweise Abhängigkeiten, die eine bestimmte Reihenfolge voraussetzte, um überhaupt lauffähig zu sein. In Version 1.1.0 haben wir daher die gesamte Standard-Pipeline refactored und diese Abhängigkeiten auf ein Minimum reduziert.
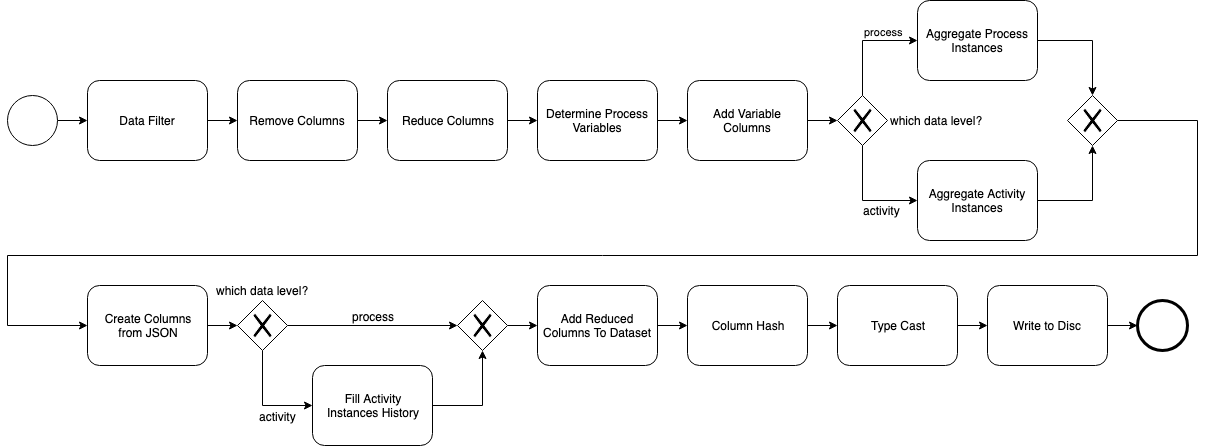
Was würdet ihr gerne in bpmn.ai sehen? Oder wollt ihr euch vielleicht an der Entwicklung beteiligen? Dann stellt doch einen Issue in Github ein, sendet einen Pull Request oder schreibt einen Kommentar und tretet mit uns in Kontakt.
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



