

Als marktführender IT-Dienstleister für alle am Transportprozess beteiligten Parteien positioniert sich TIMOCOM als Partner der Kunden, mit dem Ziel, Prozesse zu verschlanken, zu vernetzen und zu digitalisieren. Die Erfolgsgeschichte des Unternehmens reicht dabei viele Jahre zurück bis zur Firmengründung der „TimoCom Soft- und Hardware GmbH“ im Jahr 1997. Damals erkannte Jens Thiermann, einer der beiden namensgebenden Firmengründer, dass das Auffinden von Ladungen und die Auslastung von LKW eine große Herausforderung darstellen. Die Lösung wurde in der Entwicklung einer digitalen Fracht- und Laderaumbörse gefunden und umgesetzt, über die Rückladungen gesucht und Leerfahrten verringert werden konnten. Mittlerweile unter TIMOCOM GmbH firmierend, ist daraus ein Smart Logistics System mit weiteren Anwendungen, sog. Smart Apps, z. B. zur digitalen Auftragsabwicklung und GPS Tracking, gewachsen. Mit diesem System unterstützt TIMOCOM mehr als 43.000 Unternehmen aus ganz Europa täglich bei der Bewältigung komplexer Prozesse der Transportlogistik.
Dank der Anwendungsvielfalt, dem starken Einsatz der mehr als 130.000 Nutzer und dem hohen Durchsatz des Systems entsteht ein beträchtlicher Datenschatz. Dieser wird eingesetzt, um das System flexibel an die sich stetig ändernden Anforderungen der Kunden anzupassen. Transportunternehmen, Spediteure sowie Unternehmen aus Industrie und Handel werden so durch verschiedenste Ansätze zielgerichtet in ihrem operativen Geschäft unterstützt.
Sprich, die vielschichtigen Arbeitsprozesse in der Transportlogistik werden für den Nutzer immer weiter gebündelt und automatisiert, was folglich zur Zeit- und Kostenersparnis führt. TIMOCOM schafft sich durch das hohe Maß an Flexibilität eine enorme Wettbewerbsstärke in einem Markt, der zunehmend technologisch demokratisiert und disruptiv agiert. Zudem zahlt die Optimierung logistischer Prozesse nachweisbar auf das Konto eines grüneren und emissionsärmeren Straßenverkehrs ein.
Um eine höchstmögliche Leistung für das System zu erreichen, das den Einsatz künstlich intelligenter Systeme einschließt, wurde bei TIMOCOM das Applied Technology Research (ATR) Team gegründet. Das Unternehmen sichert sich damit wiederholt die Position des Pioniers, denn laut Gartners Hype Cycle werden die ersten Machine Learning Ansätze erst bald das Plateau der Produktivität erreichen.
Hier kam viadee ins Spiel, die TIMOCOM bereits in einem ganz anders gelagerten Projekt unterstützte. Mit unseren Kompetenzen in den Bereichen Data Science und Machine Learning konnten wir die Verantwortlichen schnell überzeugen. Genauso schnell und unkompliziert wurde der Kontakt zum ATR-Team hergestellt und nach einem ersten Zusammentreffen eine Vorstudie beantragt, welche durch einen viadee Berater vor Ort in Erkrath durchgeführt wurde. Ziel war es, das Unternehmen kennenzulernen und in einer geschützten Testumgebung vorhandene Daten zu analysieren, um Möglichkeiten zum Einsatz von Machine Learning Ansätzen sowie deren Chancen und Risiken aufzudecken.
Zum Projektstart wurde gemeinsam eine simple Zielsetzung definiert: mögliche Anwendungsfälle identifizieren, die einen Mehrwert für den Kunden oder das Unternehmen ermöglichen.
Um die Fülle an Informationen und Ideen zu verwalten, wurde zunächst ein Lean Startup-Ansatz eingeführt. Dieser ermöglicht ein agiles und strukturiertes Vorgehen bei Unsicherheit im Projekt; perfekt also für das Bewerten von komplexen Data Science-Potenzialen. Für jede mögliche Idee wurde ein Lean Canvas geschaffen. Dieses veranschaulicht übersichtlich die wesentlichen Facetten und Konzepte einer Idee. Im Gegensatz zu anderen Methoden ist der Lean Canvas-Ansatz also leichtgewichtig und lässt sich fortlaufend weiterentwickeln, kommunizieren und mit Alternativen vergleichen. Somit konnte der Mehrwert jeder Idee zum Einsatz von Machine Learning klar dargestellt und mögliche Risiken identifiziert werden.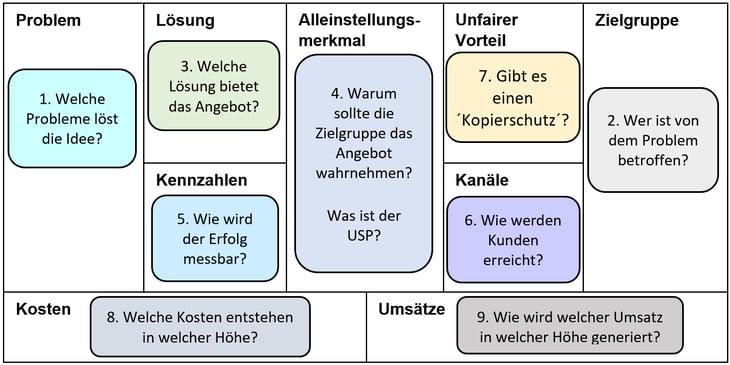
Abb.1: Das Lean Canvas hilft, eine Idee auf ihre wesentlichen Elemente zu reduzieren und zu bewerten.
In enger Zusammenarbeit mit dem TIMOCOM ATR-Team wurden die Ideen anhand der gewonnenen Erkenntnisse interaktiv in wöchentlichen Meetings priorisiert. So entstand eine fortlaufend gewartete Prioritätenliste, deren Elemente nach und nach detailliert erforscht wurden. Die daraus allmählich entstandenen Erkenntnisse und Proofs of Concepts führten dazu, dass die verschriftlichten Ideen verändert, neu priorisiert oder sogar ganz verworfen wurden. Alle dafür durchgeführten Analysen fanden stets in besonders geschützten Projektbereichen statt, um die Einhaltung der hohen Datenschutzstandards von TIMOCOM zu gewährleisten.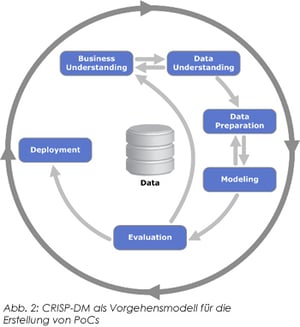 Das methodische Vorgehen bestand jedoch nicht nur auf der konzeptionellen, sondern auch auf der praktischen Ebene. Hier wurde für die Erforschung jeder Idee der Industriestandard für Data Mining-Projekte angewandt, genannt CRISP-DM (Cross-industry standard process for data mining). Dieser bietet ein strukturiertes und zugleich iteratives bzw. agiles Vorgehen, das die kreative und experimentelle Natur von Machine Learning-Unternehmungen einfangen kann. Das Vorgehensmodell unterscheidet mehrere, nicht zwangsweise sequenziell verlaufende Phasen:
Das methodische Vorgehen bestand jedoch nicht nur auf der konzeptionellen, sondern auch auf der praktischen Ebene. Hier wurde für die Erforschung jeder Idee der Industriestandard für Data Mining-Projekte angewandt, genannt CRISP-DM (Cross-industry standard process for data mining). Dieser bietet ein strukturiertes und zugleich iteratives bzw. agiles Vorgehen, das die kreative und experimentelle Natur von Machine Learning-Unternehmungen einfangen kann. Das Vorgehensmodell unterscheidet mehrere, nicht zwangsweise sequenziell verlaufende Phasen:
Der initiale Aufbau des Geschäftsverständnisses ist unerlässlich, um den Kontext eines Ansatzes zu verstehen. Dieser hilft, das Problem zu identifizieren und mögliche Lösungen zu skizzieren. Hieraus ergeben sich erste Hypothesen und Anforderungen an die Daten, die über die verbleibenden Phasen fortlaufend weiterentwickelt werden können. Durch die Anwesenheit beim Kunden kann das Verständnis schnell, effizient und unvoreingenommen aufgebaut werden.
Es folgt die Datensammlung – ein häufig bürokratisch aufwendiger Prozess, denn i. d. R. sind Daten über viele Quellen verteilt. Diese müssen fachlich identifiziert und der Zugang zu ihnen geschaffen werden. Nachdem die Daten vorliegen, werden sie explorativ untersucht, wodurch ein Verständnis für die Daten geschaffen wird. Die durchgeführte Exploration umfasst u. a. das Visualisieren von Verteilungen und die Überprüfung der Datenqualität.
Danach kann die Datenaufbereitung erfolgen. Daten werden vereint, gesäubert, korrigiert und berichtigt, Attribute entfernt und neue geschaffen. Dieser Schritt zählt zu den zeitaufwendigsten, denn in fast keinem echten Szenario liegen Daten so vor, dass sie in ihrer Rohversion für statistische Methoden nutzbar sind.
In der Modellierungs- und Evaluationsphase werden auf Basis der aufbereiteten Daten Machine Learning-Modelle geschaffen, die Vorhersagen zu neuen Instanzen oder Fakten erstellen können. Hierfür wird eine Zielvariable benötigt, deren Wert vorhergesagt wird. Dieser Prozess wird auch Modelltraining genannt, denn ein Machine Learning-Algorithmus lernt ein Modell mithilfe der historischen Daten. Verschiedenste Techniken, von einfachen Regressionen bis hin zu neuronalen Netzen können angewendet werden. Die Auswahl der Algorithmen ist häufig ein kreativer und experimenteller Prozess, der auf den Erfahrungen des Data Scientists und den zuvor aufgestellten Hypothesen und der Exploration beruht. Die erstellten Entscheider werden schlussendlich mittels statistischer Metriken bzgl. ihrer Eignung als Problemlöser bewertet. Zusätzlich können Techniken aus dem Bereich der Explainable Artificial Intelligence (XAI) angewandt werden, um das Modell und die Problemdomäne genau zu verstehen und gesetzliche Anforderungen an das System zu erfüllen.
Sollte ein Modell ausreichend gut performen, kann es in bestehende Prozesse integriert werden. Dieser Schritt wird als Deployment bezeichnet und unterscheidet sich im Falle einer Vorstudie insofern, als dass anstelle eines vollen Deployments lediglich Reports und PoCs angefertigt werden, die zur erneuten Bewertung des Ansatzes dienen.
Im Rahmen der TIMOCOM-Vorstudie konnte diese Methodik klar ihre Vorteile zeigen: Es wurden circa zehn Ideen erstellt und routinemäßig priorisiert. Für eine Handvoll der wichtigsten und vielversprechendsten Ansätze wurden ausführliche Analysen und Berichte angefertigt. Dafür wurden zusätzlich zwei Masterarbeiten mit anonymisierten Echtdaten gestartet, welche die Analysen mit theoretischen Befunden untermauerten. Die Prioritätenliste änderte sich folglich fortlaufend, denn die allmählich gewonnenen Erkenntnisse aus Theorie und Praxis zeigten, dass gewisse Ideen aufgrund der Datenbeschaffenheit oder mangelnder Qualität verworfen oder niedriger priorisiert werden sollten. Die Betrachtung konzentrierte sich fortan auf einige wenige und besonders wertvolle Ideen. Deren Potenzial bezüglich des möglichen Kundenmehrwerts und der Anwendbarkeit von Machine Learning-Methoden wurde mittels PoCs herausgestellt und unter allen Stakeholdern klar kommuniziert. Für einen besonders hochpriorisierten Anwendungsfall wurde außerdem ein Workshop mit Beratern der viadee veranstaltet. Dieser ermöglichte die Kommunikation der Produktvision in einem weiten und heterogenen Stakeholder-Kreis, wodurch sich die Idee hoher Zustimmung erfreuen konnte.
Konkrete Umsetzungen der Anwendungen stehen nun aus. Hierbei werden insbesondere solch intelligente Anwendungen in Betracht gezogen, deren Umsetzung als möglich erachtet wird und die dem Kunden durch Prozessverbesserungen und Kostensenkungen einen hohen Mehrwert bieten. Als Marktführer wird TIMOCOM mit diesen Innovationen die Digitalisierung der Transportlogistik sicherlich maßgeblich formen und in eine vielversprechende Zukunft führen können.
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



