
Wann kann ich mit der Lieferung der Ware rechnen? Wie lange dauert die Bearbeitung meines Antrages? Wann kann ich mit einer Antwort Ihrerseits rechnen? Antworten auf diese und viele weitere Fragen werden durch die Laufzeit unternehmerischer Prozesse bestimmt. Aber wie lässt sich die Laufzeit eines laufenden Prozesses eigentlich bestimmen? Eine mögliche Antwort ist Machine Learning.
Machine Learning (ML) ist eine Methode, mit der Muster in Vergangenheitsdaten erkannt werden können. So soll ein IT-System in die Lage versetzt werden, Probleme eigenständig zu lösen. Mit Algorithmen aus dem Teilgebiet des überwachten Lernens ist es möglich, aus den Ein- und Ausgabedaten ein Prognosemodell zu entwickeln, das die Eingaben beschreibt und somit Vorhersagen von Ausgabedaten ermöglicht.

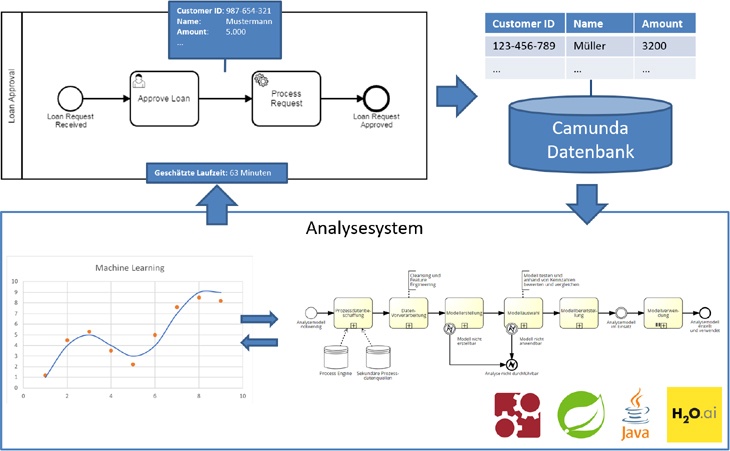
Die Erstellung eines Laufzeitprognosemodells benötigt in den meisten Fällen eine individuelle Analyse der Laufzeitfaktoren. Schließlich kann die Laufzeit eines Produktionsprozesses von anderen Faktoren getrieben sein, als die eines Bestellprozesses; und auch der Zufall spielt eine Rolle. Die Aktivitäten, die zur Schaffung eines Prognosemodells notwendig sind, können grundsätzlich als ein Referenzprozessmodell generalisiert werden (siehe obige Grafik unten rechts). Das umfasst das Beschaffen der Prozessdaten, die Vorverarbeitung sowie das Erstellen des Modells mit dem Machine Learning Algorithmus und auch die Auswahl eines Prognosemodells. Nicht jedes Prognosemodell ist zwangsläufig zuverlässig, was die Genauigkeit der Prognosen angeht. Im Rahmen eines Auswahlprozesses wird eben diese Eigenschaft überprüft und sichergestellt, dass das Modell seinen Zweck hinreichend gut und stabil erfüllt. Ist das erzeugte Modell geeignet, kann es den Anwendern zur Verfügung gestellt werden. Damit steht es ihnen anschließend für die Durchführung von Prognosen bereit – oder auch einfach nur als „Erklärung“ für das aktuelle Verhalten ihres Prozesses.
Hier wird die Implementierung der oben genannten Aktivitäten als Analysesystem behandelt. Mit dem System soll es fachlichen Anwendern des Prozesses möglich sein, die Laufzeit einer individuellen, neuen Prozessinstanz im Vorfeld schätzen zu lassen und darauf zu reagieren. Zum Beispiel mit einer Priorisierung, einer Rückmeldung an den Kunden oder einer Personaleinsatzplanung im Folgeprozess. Die Teile des Referenzprozesses sind dabei ebenfalls als BPMN-Prozesse abgebildet und werden mit der Camunda Process Engine automatisiert. Die Vorteile des BPM-Ökosystems, aus dem die Daten stammen, werden so mehrfach ausgenutzt.
Aus technischer Sicht werden die Daten des zu analysierenden Prozesses über die REST-Schnittstelle der Process Engine beschafft und gemäß genannter Prozedur in Form von Prozessen verarbeitet. Die Machine Learning Plattform h2o.ai dient dabei als Technik zur Erzeugung der Laufzeitprognosemodelle. Die Plattform führt das Aufteilen der Daten, das Trainieren des Modells sowie die Erzeugung eines verwendbaren Java POJOs durch. Das erzeugte POJO wird vom Analysesystem benutzt, um die Laufzeitvorhersageanfragen zu verarbeiten. Die Anfragen werden ebenfalls mithilfe eines BPMN-Prozesses verarbeitet, der die Datenbeschaffung, Vorverarbeitung und Abfrage des Java-Objektes durchführt. Abschließend kann die ermittelte Laufzeit von dem jeweiligen Anwender über das System abgefragt werden.
Insgesamt lässt sich mit der entwickelten Lösung der ganzheitliche Workflow aus Modellerstellung und Modellauswahl sowie Anwendung der Prognosen abbilden. Damit steht es fachlichen Nutzern offen, Laufzeitprognosen für ihre laufenden Prozesse in kontrollierter Weise zu erzeugen, mit denen sie potentiell weiterführende betriebliche Analysen durchführen können. Die gewonnen Informationen machen es ihnen möglich, mehr Transparenz im Kontext des Prozesses zu schaffen.
Hinweis: Dieser Artikel fasst im Wesentlichen Erkenntnisse aus Literatur-Recherche, eigenen Experimenten und Experten-Interviews aus der Master-Arbeit von Matthias Kutz an der FH Münster 2018 zusammen. Die Arbeit wurde in Kooperation mit der Duni AB erstellt.
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



