

kustomize ermöglicht die Anpassung von Kubernetes-Deployments zur Erzeugung mehrerer Varianten (z. B. für unterschiedliche Umgebungen). Dabei werden die originalen YAML-Dateien nicht modifiziert, sondern mit Overlays überlagert. Im Gegensatz zu Helm kommt kustomize also ganz ohne Templates aus, was die Verwendung besonders einfach macht. In diesem Blog-Post stellen wir die wichtigsten Features von kustomize anhand eines Beispiels vor.
Jegliche Ressourcen in Kubernetes werden als YAML-Dateien definiert und per "kubectl apply" an den API-Server geschickt (siehe Blog-Post zum API-Server). Nun dauert es nicht lange, bis von einem Deployment leicht unterschiedliche Varianten notwendig werden. Im einfachsten Fall wird in PROD eine andere Datenbank-URL benötigt als in DEV. Komplexer wird es, wenn die YAML-Dateien an andere User ausgeliefert werden (z.B. in OpenSource-Projekten) und so eigentlich jede Einstellung anpassbar sein soll.
Diese "Tooling-Lücke" hat lange Zeit "Helm" gefüllt und sich zum De-facto-Standard entwickelt, der nun zu wackeln beginnt. Warum? Gerade in Deployment-Szenarien mit überschaubarer Komplexität macht Helm die Wartbarkeit unnötig schwer, bremst die Entwicklung und erhöht die Fehleranfälligkeit. In diesem Blog-Post schauen wir uns daher kustomize als Alternative an, welche kürzlich auch in die Kubernetes-CLI kubectl integriert wurde. Um das Fazit vorwegzunehmen: Ich würde kustomize insbesondere für kleinere Projekte empfehlen!
Das Original
Schauen wir uns die Alternativen Schritt für Schritt an. Ein simples Deployment eines Alpine-Linux sieht bspw. so aus:
Hier ist nichts parametrisiert - diese YAML-Datei ist konform zur Kubernetes API-Spezifikation und wird somit direkt vom API-Server akzeptiert. Schreibt man eine solche YAML-Datei in einer IDE wie Visual Studio Code oder IntelliJ, kann man sich über Features wie Auto-Completion freuen.
Helm
Helm nutzt das Templating-System von Go und bündelt mehrere zusammengehörige Template-Dateien zu sog. Charts - häufig bleibt es ja nicht bei einem Deployment, sondern es gesellen sich noch weitere YAML-Dateien für Services, Ingresses, Secrets usw. hinzu, bevor daraus ein fachlich vollständiges Deployment-Paket wird. Mit dem Kommando helm create <app-name> kann man sich eine Vorlage erzeugen und diese weiter ausbauen. Wie sieht das Pendant für unser Alpine-Deployment aus?
Lesbarkeit? Hm.
IDE-Unterstützung wie Auto-Completion? Nicht mehr vorhanden, bestenfalls rudimentär.
Ach so, zu der Template-Datei gehört natürlich noch eine values.yaml-Datei mit den Werten für die Platzhalter:
Eigentlich haben wir jetzt - neben dem sperrigen Template - eine values.yaml-Datei, die fast genauso groß ist wie das Original. Hm.
Das Problem der Wartbarkeit kann man sich an dem kleinen Beispiel bereits vorstellen, wächst aber mit der Größe des jeweiligen Projektes. Das Deployment unserer vPW-Showcase-Umgebung besteht bspw. aus knapp 90 Template-Dateien mit über 3000 Zeilen Code, wobei externe Abhängigkeiten wie Elasticsearch, Kafka und Co hier noch nicht mit eingerechnet sind. Was in überschaubaren Deployments "nur" den Spaß der Entwickler trübt, wird bei größeren Setups zu einem relevanten Risiko, denn die Fehleranfälligkeit nimmt extrem zu.
Kustomize
Was macht kustomize nun anders?
- Keine Templates: kustomize setzt auf eine Overlay-/Patch-Strategie, d. h. man schreibt "normale" YAML-Dateien, die durch Overlays ergänzt werden (also keine Templates mit Platzhaltern wie bei Helm!)
- Deklarativ: Da man jederzeit valide Kubernetes-YAML-Dateien ohne Platzhalter schreibt, hat man automatisch die volle IDE-Unterstützung inkl. Auto-Completion.
- Praktische Features: Typische Use-Cases wie "alle Ressourcen sollen ein bestimmtes Label erhalten und in einen angegebenen Namespace deployed werden" sowie "Änderungen einer Config-Map sollen zu einem neuen Rollout des Deployments führen" werden gezielt adressiert.
- Flexibel und unabhängig: Das CLI-Tool kustomize rendert letztlich nur YAML-Output nach Stdout, welcher anschließend je nach Geschmack mittels des Bash-Pipe-Operators weiterverarbeitet werden kann (z. B. kustomize build ~/someApp/overlays/production | kubectl apply -f -)
- Integration: Seit kubectl v.1.14 sind die kustomize-Funktionen für das Rendering in kubectl integriert, sodass keine weitere Binary benötigt wird.
Overlays
Statt Templates verwendet kustomize sog. Overlays. Die Idee: Man definiert eine Basis-Version der YAML-Dateien ("base") und dann Overlays für Modifikationen des Originals. Dabei handelt es sich um normale YAML-Dateien, welche nur die Attribute der "spec" enthalten, welche dann das Original überdecken/überschreiben sollen. In folgender Abbildung wird bspw. der Replica-Count eines Deployments von 1 auf 3 geändert. Neben den abweichenden Attributen muss das Overlay auch die notwendigen Informationen enthalten, um die Ressource zu identifizieren, die überlagert werden soll (hier also ein Deployment mit Namen "my-app"). Weitere Details zu diesem Mechanismus schauen wir uns im Folgenden an.
.png?width=1172&name=overlay%20(2).png)
Ordnerstruktur
Der Code zum folgenden Beispiel ist vollständig auf GitHub verfügbar: https://github.com/viadee/kustomize-examples
Die Verzeichnisstruktur kann grundsätzlich frei gewählt werden, etabliert hat sich jedoch:
~/my-app
├── base
│ ├── deployment.yaml
│ └── kustomization.yaml
└── overlays
├── prod
│ ├── deployment_env.yaml
│ ├── deployment_replicas.yaml
│ ├── deployment_volume.yaml
│ └── kustomization.yaml
└── dev
│ ├── kustomization.yaml
│ └── ...
└── ...
- ./base: Als Verzeichnis für die originalen Kubernetes YAMl-Dateien.
- ./overlays/<env>: Eigener Unterordner je Umgebung, in welchem die Overlays mit den jeweiligen Modifikationen gesammelt werden.
./base
Neben der originalen deployment.yaml-Datei (siehe oben), müssen wir noch eine kustomization.yaml-Datei anlegen. Letztlich enthält sie einfach nur eine Liste aller Ressourcen, die von kustomize berücksichtigt werden sollen.
./overlays/prod
Um einzelne Felder des Deployments umgebungsspezifisch anpassen zu können, legen wir einen Ordner für PROD an. Auch dieser muss eine kustomization.yaml-Datei enthalten, die wir im Folgenden nach und nach erweitern werden. Zunächst enthält sie nur den relativen Pfad zur Basis-Version ("../../base"), auf welches die Overlays angewendet werden sollen.
Mit kubectl kustomize ./overlays/prod können wir nun einen ersten Versuch wagen - voilà! Als Output erhalten wir die unveränderte deployment.yaml-Datei.
$ kubectl kustomize ./overlays/prod
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 1
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- env:
- name: foo
value: bar
image: alpine:3.10
name: my-app
resources:
limits:
cpu: 100m
memory: 64Mi
stdin: true
tty: true
Overlays: Replicas & Umgebungsvariablen
Greifen wir gleich das obige Beispiel nochmal auf. In PROD wollen wir eine höhere Redundanz unseres Deployments haben (Replica-Count) sowie Umgebungsvariablen ergänzen. Anpassen müssen wir also die Felder "replicas" und "spec.template.spec.containers[].env" der Ressource "my-app" vom Typ "Deployment".
Ob man die Modifikationen in einer gemeinsamen YAML-Datei unterbringt oder für jede Anpassung eine eigene Datei anlegt, bleibt letztlich jedem selbst überlassen - wir splitten es hier mal auf, um die Features einzeln demonstrieren zu können.
Die erste Overlay-Datei kümmert sich um die Anpassung des Replica-Counts: /overlays/prod/deployment_replicas.yaml:
Die ersten vier Zeilen dienen nur zur Identifizierung der Ressource. Alles, was nun als "spec" folgt, überschreibt die ursprüngliche Version aus ./base.
Die zweite Overlay-Datei ergänzt eine Umgebungs-Variable. Da die Umgebungsvariablen auf Container-Ebene gesetzt werden, muss der zur Identifizierung des richtigen Containers (es kann mehrere geben) notwendige Anteil der "spec" angegeben werden. Oder ganz praktisch ausgedrückt: Der Pfad bis zum "name" Attribut des Containers.
Damit die beiden Overlay-Dateien berücksichtigt werden, müssen wir diese in der kustomization.yaml-Datei für PROD registrieren:
Ergebnis:
$ kubectl kustomize ./overlays/prod apiVersion: apps/v1 kind: Deployment metadata: name: my-app spec: replicas: 2 selector: matchLabels: app: my-app template: metadata: labels: app: my-app spec: containers: - env: - name: foo value: we-are-in-prod image: alpine:3.10 name: my-app resources: limits: cpu: 100m memory: 64Mi stdin: true tty: true
Namespaces & Labels
Um alle Ressourcen in einem bestimmten Namespace zu deployen und mit gemeinsamen Labels zu versehen, erweitern wir die kustomization.yaml-Datei für PROD wie folgt:
Wenn man sich das Ergebnis ansieht, wird deutlich, dass die Labels wirklich zu allen Ressourcen hinzugefügt werden, auch zu dem Pod-Template innerhalb eines Deployments.
$ kubectl kustomize ./overlays/prod apiVersion: apps/v1 kind: Deployment metadata: labels: foo: bar name: my-app namespace: my-app-prod spec: replicas: 2 selector: matchLabels: app: my-app foo: bar template: metadata: labels: app: my-app foo: bar spec: containers: - env: - name: foo value: we-are-in-prod image: alpine:3.10 name: my-app resources: limits: cpu: 100m memory: 64Mi stdin: true tty: true
ConfigMaps & Secrets
ConfigMaps und Secrets sind beliebte Konstrukte, um die Konfiguration der Anwendung vom eigentlichen Deployment-Deskriptor zu trennen. Die ConfigMap enthält dann diverse Einstellungen als Key-Value-Paare und im Deployment wird nur noch auf die ConfigMap referenziert und bspw. alle Key-Value-Paare in Umgebungsvariablen umgewandelt.
Was passiert, wenn man einen Wert in der ConfigMap ändert? Nichts! Die Änderung wirkt sich erst auf neu erzeugte Pods aus. Um zu erreichen, dass die angepasste Konfiguration auch unmittelbar von der deployten Applikation verwendet wird, muss man alle Pods einmal löschen und diese vom ReplicaSet des Deployments neu erzeugen lassen. Wem das zu lästig war, der hat bisher mit Workarounds gearbeitet: Zum Beispiel mit einer Annotation im Deployment, wo einfach nur eine Zahl hochgezählt wurde, um eine (irrelevante) Änderung zu provozieren und damit ein Rollout anzustoßen.
Mit kustomize geht das nun eleganter, wenn man ConfigMaps über den "configMapGenerator" in der kustomization.yaml erzeugt:
Analog funktioniert das auch für schützenswerte Inhalte, also Secrets:
Übrigens: Neben Literals kann man ConfigMaps und Secrets auch aus Dateien erzeugen, was z. B. für Zertifikate interessant sein kann. Mehr dazu im GitHub-Repo: https://github.com/viadee/kustomize-examples/tree/master/overlays/prod
Damit ConfigMap und Secret dann letztlich auch verwendet werden, müssen wir das Overlay deployment_env.yaml entsprechend anpassen und den "envFrom"-Block ergänzen:
Was passiert nun beim Rendering?
- Neben dem Deployment wird auch die YAML-Ausgabe für die ConfigMap und das Secret erzeugt
- Die Namen der ConfigMap und des Secrets enthalten einen Hash-Wert ihres Inhaltes. Eine Änderung der ConfigMap oder des Secrets führt nun also zu einem neuen Hash-Wert und damit auch zu einer Veränderung in der YAML-Spezifikation des Deployments, denn dort taucht der Name ja als Referenz auf → Dadurch wird ein Rollout getriggert und die Pods ausgetauscht!
$ kubectl kustomize ./overlays/prod
apiVersion: v1 data: username: prod-user kind: ConfigMap metadata: labels: foo: bar name: app-config-8f582gb49h namespace: my-app-prod --- apiVersion: v1 data: password: Zm9v kind: Secret metadata: labels: foo: bar name: credentials-bdkm7dgmb9 namespace: my-app-prod type: Opaque --- apiVersion: apps/v1 kind: Deployment metadata: labels: foo: bar name: my-app namespace: my-app-prod spec: replicas: 2 selector: matchLabels: app: my-app foo: bar template: metadata: labels: app: my-app foo: bar spec: containers: - env: - name: foo value: we-are-in-prod envFrom: - configMapRef: name: app-config-8f582gb49h - secretRef: name: credentials-bdkm7dgmb9 image: alpine:3.10 name: my-app resources: limits: cpu: 100m memory: 64Mi stdin: true tty: true
Anpassungen zum Zeitpunkt des Deployments
Bisher haben wir Änderungen betrachtet, die man gut in einem Repository verwalten und versionieren kann. Was aber tun, wenn die Information erst zum Ausführungszeitpunkt von kubectl kustomize zur Verfügung steht? Als Image-Tag wird häufig der Hash-Wert des Commits verwendet, welcher die aktuell laufende Build-Pipeline getriggert hat. Der Commit-SHA ist demnach vorab unbekannt und trotzdem muss er seinen Weg in das Image-Attribut der YAML-Datei finden.
Die folgende Grafik stellt eine typische Continuous-Deployment-Pipeline schematisch dar. Der Commit-SHA steht erst zur Laufzeit der Pipeline zur Verfügung, kann also nicht in ein Overlay eingebaut und vorab committet werden.
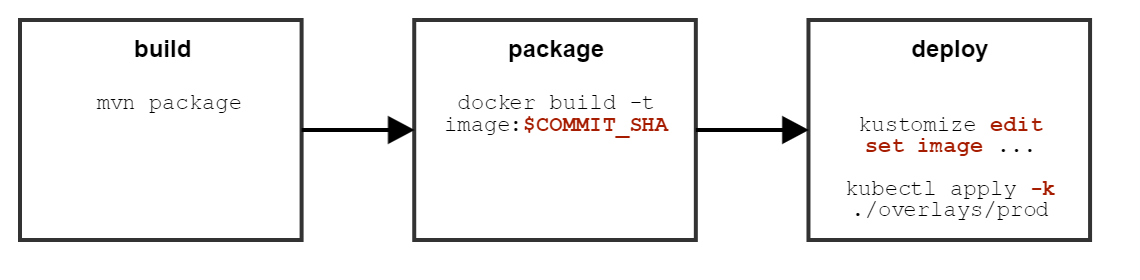
kustomize bietet für einige Felder "edit"-Befehle an. So setzen wir bspw. in allen Ressourcen den Tag des "alpine" Images neu:
cd ./overlays/prod kustomize edit set image alpine=alpine:3.9
Alternativ hätte man hier natürlich den Commit-Hash übergeben können.
kustomize edit set image alpine=myimage:$COMMIT_SHA
Letztlich führt beides zu einer Anpassung der /overlays/prod/kustomization.yaml-Datei:
Wenn wir nun nochmal die Ausgabe mit kubectl kustomize ./overlays/prod rendern, sieht man, dass die neuen Image-Koordinaten verwendet werden.
Hinweis: Das edit-Kommando steht nur in der kustomize-Binary zur Verfügung, nicht in der kubectl-Integration. kubectl kustomize <args> ersetzt kustomize build <args>, für alle anderen Befehle braucht man die Binary von https://github.com/kubernetes-sigs/kustomize/releases.
Wie schickt man die YAML-Ausgabe zum API-Server?
In der offensichtlichen Variante übergibt man einfach den gerenderten YAML-Output von kustomize an "kubectl apply" mittels des Bash-Pipe-Operators ("|"). kubectl hat allerdings auch noch eine Abkürzung implementiert. Während man normalerweise YAML-Dateien mit kubectl apply -f ./filename.yaml an den API-Server schickt, kann man mit "-k" vorab noch ein Rendering mittels kustomize erzwingen.
# Variante 1 mit kubectl kubectl kustomize ./overlays/prod | kubectl apply -f - # Variante 2 - Abkürzung mit kubectl (-k statt -f) kubectl apply -k ./overlays/prod
Fazit
Zunächst: kustomize hat noch weitere Features. Die Dokumentation ist noch etwas knapp, einen besseren Einstieg liefern die Beispiele (https://github.com/kubernetes-sigs/kustomize/blob/master/examples/).
Wenn Sie Ihre Deployments selbst in der Hand haben (z. B. interne Anwendungen im Unternehmen) und diese ohne größere Abhängigkeiten auskommen (z. B. integriertes Deployment einer Datenbank), empfehle ich, kustomize einfach mal auszuprobieren und zu evaluieren. Dies gilt insbesondere für Deployments mit geringer Komplexität. Es macht das Vorhaben schlicht einfacher und transparenter.
Übrigens: Auch eine Kombination von Helm und kustomize ist möglich! Wenn man ein Helm-Chart aus der Community verwenden möchte, dieses aber nicht alle notwendigen Konfigurationen erlaubt, kann man den mittels "helm template" gerenderten YAML-Output anschließend mit kustomize nochmal modifizieren. Dies erspart ein aufwendiges Forken bzw. die manuelle Pflege einer Kopie des Helm-Charts aus dem offiziellen Repository.
Haben Sie Fragen zu kustomize, CI/CD-Pipelines oder dem Umgang mit Kubernetes? Nehmen Sie gerne mit uns Kontakt auf! Hier finden Sie unser Leistungsspektrum zum Thema Cloud.



zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



