

Von einer automatisierten Anomalie-Erkennung versprechen sich Data Scientists, seltsame und verdächtige Werte in Daten zu identifizieren. So können z. B. betrügerische Transaktionen, durch Maschinen produzierte Fehler oder ungewöhnliche Prozessschritte aufgedeckt werden. Oder man behandelt die Fälle für andere Machine Learning-Zwecke separat. Ende 2018 veröffentlichte h2o.ai einen neuen Mechanismus zur Anomalie-Erkennung: den Isolation Forest. Mithilfe dieser Methode des Unsupervised Machine Learning lassen sich Anomalien in Datensätzen leicht erkennen und filtern. Das erproben wir hier und versuchen, insbesondere die Ergebnisse der Anomalie-Erkennung nachvollziehbar zu machen: Was macht die Anomalie zur einer Anomalie?
Wie funktioniert ein Isolation Forest?
Die Idee eines Isolation Forest ist es, aufzudecken, welche Datensätze sich schnell partitionieren lassen. Dies kann ganz einfach anhand der unten abgebildeten Grafik erklärt werden. Um den Datenpunkt X zu finden, muss der Datensatz viele Male zufällig unterteilt werden. Der Datenpunkt Y wurde hingegen bereits nach einer zufälligen Trennung isoliert. Ein Datenpunkt, welcher sich wie der Punkt Y schnell isolieren lässt, wird nach dem Ansatz des Isolation Forest als Anomalie gesehen.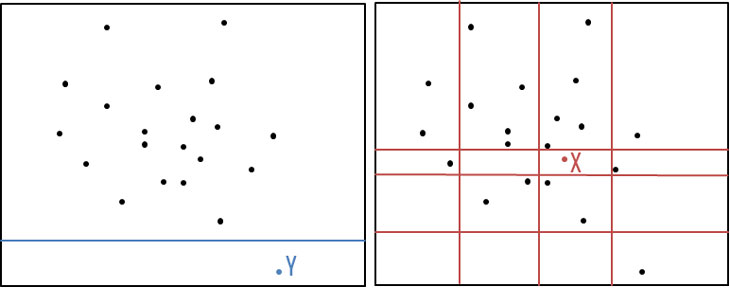
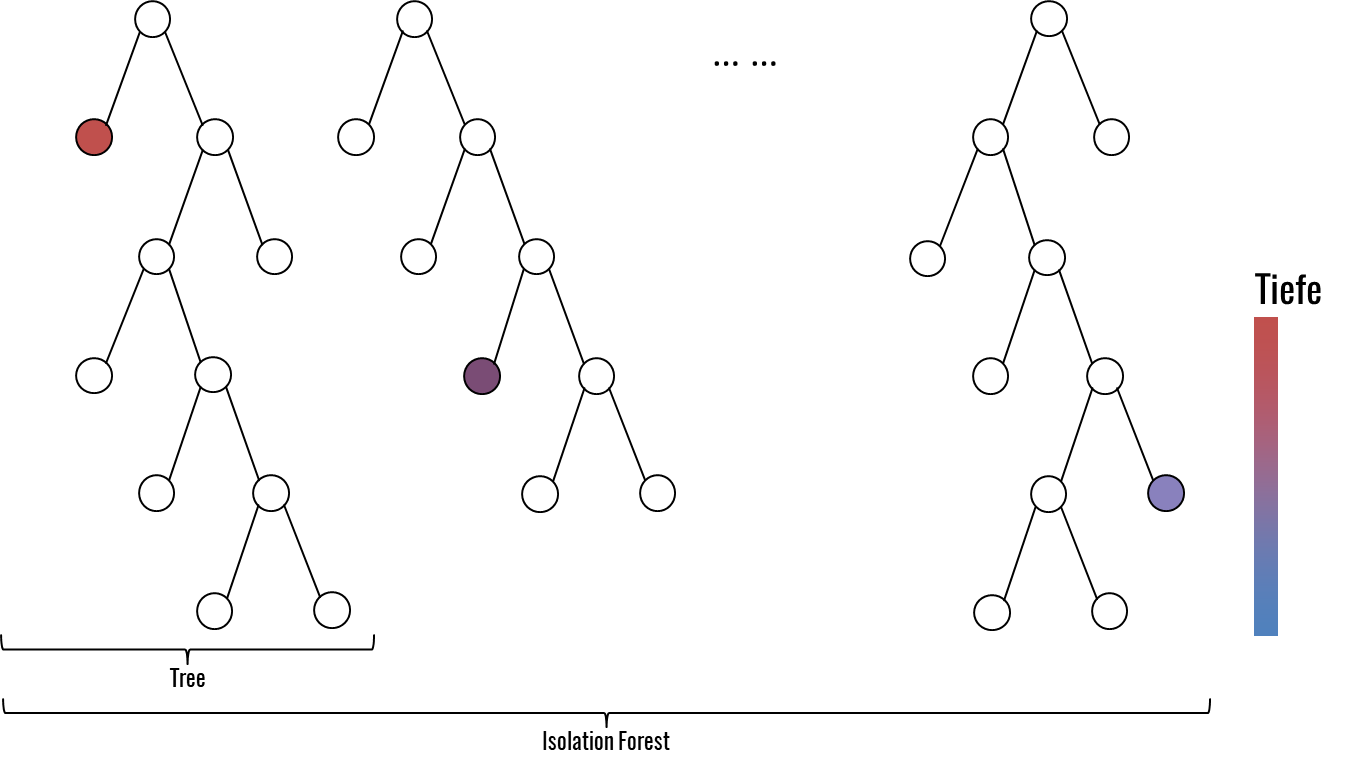
Im Isolation Forest wird die zuvor beschriebene Partitionierung anhand von binären Bäumen mehrfach durchgeführt. Jeder Baum besteht aus einem zufälligen Subset des Datensatzes mit einer festgelegten Größe. Der Datensatz wird solange partitioniert, bis entweder jeder Datenpunkt isoliert dargestellt wird oder eine durchschnittliche Tiefe erreicht wird. Diese Vorgehensweise ist valide, da ausschließlich anomale Datenpunkte von Interesse sind und diese bereits nach Partitionierung bis auf die durchschnittliche Tiefe gefunden wurden. Das Feature und der Threshold der Partitionierung werden jeweils zufällig gewählt. Erzeugt man viele dieser Isolation Trees, so ergibt sich ein Isolation Forest. Um nun zu bestimmen, ob es sich bei einer Beobachtung um eine Anomalie handelt, wird für jede Beobachtung in den Daten die durchschnittliche Tiefe aller Bäume des Isolation Forest berechnet. Je geringer dieses Maß ausfällt, desto ungewöhnlicher ist die Beobachtung und umso deutlicher handelt es sich um eine Anomalie.
Ein Anwendungsbeispiel: h2o-Isolation Forest mit R
Der Aufruf der Funktion ist, wie auf der h2o-Plattform üblich, sehr einfach. Wir wollen im Folgenden die Anomalie-Erkennung anhand des Titanic Datensatzes der kaggle Challenge testen. Inhaltlich umfasst der Datensatz Informationen über Passagiere der Titanic wie beispielsweise ihr Alter, ihr Geschlecht oder ihren Namen. Den Datensatz haben wir vorverarbeitet und ebenfalls im git-Repository zur Verfügung gestellt: Die Vorverarbeitung war notwendig, da unser Ansatz zur Anomalie-Erklärung ausschließlich auf numerischen Werten arbeiten kann. Aus diesem Grund wurden alle nicht numerischen Features im Vorhinein transformiert. Um diesen Schritt zu vereinfachen, stehen die vorverarbeiteten Daten ebenfalls im Repository bereit. Grundsätzlich lässt sich ein Isolation Forest aber auf beliebige Datentypen und Skalenniveaus der Features anwenden.Im ersten Schritt müssen ein h2o-Cluster gestartet und der Titanic Datensatz importiert werden. Für die Anomalie-Erkennung nutzlose Features wie die Id des Passagiers oder sein Name werden für das Trainieren des Modells entfernt - diese sind ohnehin einzigartig und wir können daraus keine Erkenntnisse über Anomalien erwarten. Danach kann der Datensatz in Trainings- und Testdaten unterteilt werden.
# 1. load data and packages
library(h2o)
library(dplyr)
library(ggplot2)
source("./XAIUtils.R")
titanic = read.csv("./titanic.csv")
h2o.init()
# 2. generate train and test data
train = titanic[1:round(nrow(titanic)*0.8),]
test = titanic[round(nrow(titanic)*0.8):nrow(titanic),]
trainh2o = as.h2o(train[,c(-1,-2,-3,-12)]) # remove useless columns (e.g. IDs)
testh2o = as.h2o(test[,c(-1,-2,-3,-12)])
Jetzt kann das Modell bereits trainiert werden. In diesem Fall generieren wir 100 Bäume und führen dann die Vorhersage auf den Testdaten durch. Die Ergebnisse der Vorhersage werden im dataframe iso_DF abgelegt.
# 3. train model
model_iso <- h2o.isolationForest(training_frame = trainh2o, model_id = "isoForest", seed = 42, ntrees = 100)
iso_DF = h2o.predict(model_iso, testh2o) %>% as.data.frame()
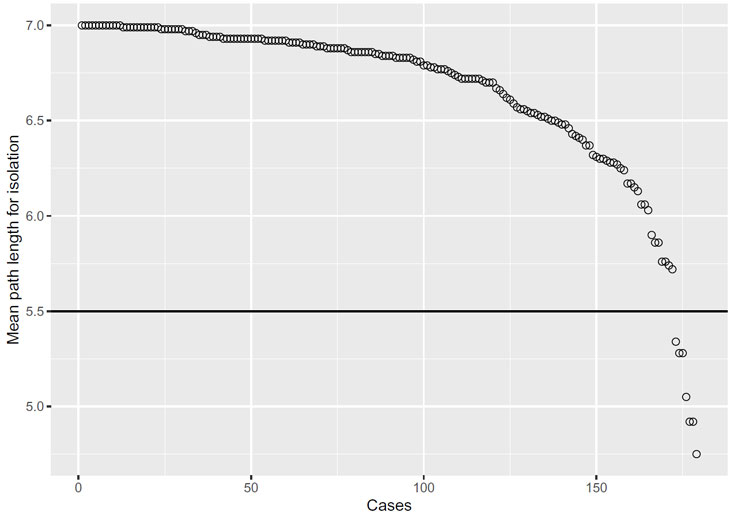
Stellt man nun die durchschnittliche Baum-Tiefe der Beobachtungen grafisch dar, lässt sich einfach bestimmen, welche Datenpunkte Anomalien darstellen. In diesem Fall wählen wir die sieben Datenpunkte, die die geringste durchschnittliche Tiefe aufweisen, und deklarieren sie als Anomalien. Diese Anzahl ist zwar ein wenig willkürlich, drängt sich hier aber auf. Die sieben Datenpunkte werden abschließend im dataframe iso_anomaly abgelegt.
# 4. identify anomalies
anomaly_threshold = 5.5 # Set threshold by looking at the graph!
iso_DF_ordered = iso_DF %>% arrange(desc(mean_length))
ggplot(iso_DF_ordered, aes(x=c(1:nrow(iso_DF_ordered)), y=iso_DF_ordered$mean_length)) geom_point(size=2, shape=1)
ylab("Mean Length") xlab(" ") geom_hline(yintercept = anomaly_threshold) theme(legend.position="none")
iso_anomaly = data.frame(iso_DF,test) %>% filter(mean_length < anomaly_threshold)
Isolation Forest und Explainable AI (XAI)
Am oben gezeigten Beispiel sieht man, dass der Mechanismus zwar auf sehr einfache Weise in der Lage ist, Anomalien aufzudecken, es aber noch keine Hinweise darauf gibt, wie der Algorithmus zu diesem Ergebnis kommt. Ein Blick in diese Blackbox ist in der Praxis jedoch von hoher Bedeutung, da nur so reagiert werden kann.Ein erster XAI-Ansatz versucht, die Anomalien mithilfe eines Decision Trees zu erklären. Nachdem eine Anomalie mit dem Isolation Forest identifiziert wurde, wird der Datensatz durch eine Spalte ergänzt, die bestimmt, ob es sich bei einem Datenpunkt um eine Anomalie handelt. Auf diese Zielvariable wird ein Decision Tree trainiert, welcher Aufschluss darüber gibt, welche Features für das Vorliegen der Anomalie verantwortlich sind.
Um jedoch die Komplexität zu reduzieren und möglichst nah am ursprünglichen Modell des Isolation Forest zu bleiben, haben wir einen neuen Ansatz entwickelt. Im git-Repository isolationForestXAiUtils haben wir dazu eine Funktion namens findShortestPath bereitgestellt, die genau dies auf Basis der ebenfalls noch recht neuen Tree-API der H2o-Plattform tut. Der Funktion müssen lediglich eine beliebige Beobachtung (für unseren Zweck eine identifizierte Anomalie) und das Modell des Isolation Forest übergeben werden. Der Algorithmus traversiert daraufhin sämtliche Bäume des Isolation Forest und bestimmt die jeweilige Tiefe des Pfades von der Wurzel bis zur gesuchten Beobachtung. Der Pfad, der die Anomalie am schnellsten isoliert (kürzester Pfad), stellt die Grundlage für die Erklärung der Anomalie dar. Die Ausprägungen der Merkmale der Anomalie, welche auf diesem kürzesten Pfad liegen, stellen seltene Werte oder Wertekombinationen dar und sind somit verantwortlich für die Einstufung der Beobachtung als Anomalie.
Dazu ein Beispiel: Beispielhaft untersuchen wir den Datenpunkt des Passagiers mit der Id 847. Mit einer durchschnittlichen Tiefe von 4.75 stellt dieser Datenpunkt die "stärkste" Anomalie dar. Wir übergeben den Datenpunkt gemeinsam mit dem Modell der Funktion findshortestPath.
findShortestPath(model_iso, iso_anomaly[5,])Die Funktion findShortestPath durchsucht alle Bäume des Isolation Forest nach dem Datenpunkt des Passagiers mit der Id 847. Dabei wird für jeden Baum die Länge des Pfades von der Wurzel bis zum jeweiligen Datenpunkt bestimmt. Schließlich wird der kürzeste aller dieser Pfade des Modells zurückgegeben. Im Fall des Passagiers mit der Id 847 ist das ein Pfad mit den Merkmalen Survived (Survived < 0.5) und SibSp (SibSp ≥ 6.5). Die Zahl der Elternteile und Geschwister des Passagiers mit der Id 847 entspricht 8 und darüber hinaus hat dieser Passagier das Schiffsunglück nicht überlebt (Survived = 0). Diese beiden Eigenschaften charakterisieren den Passagier 847 als Anomalie.
Der Isolation Forest im Vergleich
Um unseren XAI-Ansatz zu erproben, wollen wir abschließend die XAI-Ergebnisse mit denen eines Auto-Encoders vergleichen. Der Auto-Encoder ist die etablierte und offensichtliche Wahl für eine Anomalie-Analyse und ebenfalls im Angebot der h2o-Plattform enthalten. Wir haben deshalb auch dieses Verfahren auf den Titanic Datensatz angewandt. Im Fall vom Auto-Encoder werden Anomalien mithilfe des MSE identifiziert. In der untenstehenden Grafik haben wir die Ergebnisse des Isolation Forest anhand der Mean Length und die des Auto-Encoders anhand des MSE gegenüber gestellt. Es fällt auf, dass beide Verfahren zu ähnlichen Ergebnissen kommen. Nichtsdestotrotz bleibt spannend, dass einige Datenpunkte von einem Verfahren als Anomalie bewertet wurden, ein anderes Verfahren den Datenpunkt jedoch als „normal“ einstuft.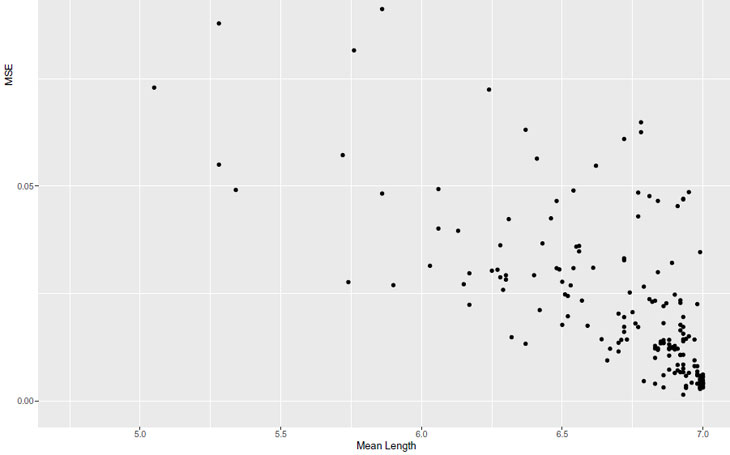
Wenn wir noch einmal den Datenpunkt des Passagiers 847 betrachten, so konnte dieser auch mit einem MSE von 0.11 vom Auto-Encoder als Anomalie identifiziert werden. Um die Ergebnisse des Auto-Encoders nachvollziehbar zu machen, kann der SE der verschiedenen Features verwendet werden. Je höher der SE eines Features ausfällt, desto entscheidender ist das Feature für das Vorliegen der Anomalie. In diesem Fall ist vor allem das Feature SibSp entscheidend für den vergleichsweise hohen MSE - analog zum Isolation Tree.
Ein kritischer Blick auf den Isolation Forest
In unserem Vergleich mit dem Auto-Encoder-Ansatz konnten wir nachweisen, dass der h2o- Isolation Forest vergleichbare und damit valide Ergebnisse liefert. Damit können wir den Isolation Forest als gute Alternative zum Auto-Encoder empfehlen. Der Isolation Forest zeichnet sich insbesondere durch seine Verständlichkeit aus. Dies wird vor allem auch durch die von h2o bereitgestellte Funktionalität unterstützt, die es ermöglicht, die einzelnen Bäume des Isolation Forest zu visualisieren. Außerdem lässt sich die Methode in nahezu linearer Laufzeit ausführen und funktioniert gut bei hochdimensionalen Problemen, die eine große Anzahl irrelevanter Attribute aufweisen, sowie in Situationen, in denen das Trainingsset keine Anomalien enthält.Neben den Stärken des Isolation Forest lassen sich jedoch auch einige Schwächen des Ansatzes abschließend anmerken. Zuerst einmal ist im Isolation Forest im Gegensatz zum Auto-Encoder von vornherein keine Funktionalität inkludiert, die die Ergebnisse nachvollziehbar macht. Da dies jedoch insbesondere in der Praxis von hoher Bedeutung ist, besteht die dringende Notwendigkeit, den Isolation Forest um einen Erkläralgorithmus - wie in unserem Ansatz - zu ergänzen. Kritisch zu sehen ist außerdem, dass der Aufbau der Bäume (Feature und Threshold der Partitionierung) des Isolation Forest teilweise unvollständig dargestellt wird. So bleibt beispielsweise unklar, wie der Ansatz einen Threshold für die Trennung von Factor-Werten wählt.
Sprechen wir darüber - auch freuen wir uns über Feedback und Beiträge zu dem im Rahmen dieses Blogartikels entstandenen GitHub-Projekt.
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



