

Politische Anzeigen sind zu kennzeichnen – geschieht das auch konsequent? Erkennen wir per XAI Entscheidungsgrundlagen oder Lücken? Ein Experiment.
Politische Werbeanzeigen mit KI identifizieren
Im Verlauf der letzten Jahre hat sich gezeigt, dass soziale Netzwerke wie Facebook wichtige Plattformen für die Verbreitung politischer Inhalte sind. Sie werden sowohl von politischen Parteien und Kandidat:innen für Wahlwerbung benutzt als auch von Verbänden, Interessensgruppen und anderen Initiativen zur Erreichung ihrer Ziele. Insbesondere die U.S. Präsidentschaftswahl im Jahr 2016 hat gezeigt, dass aufgrund der Möglichkeiten der hochpräzisen Auswahl von Zielgruppen bei Facebook Transparenz darüber fehlt, welche politischen Anzeigen existieren und wer diese schaltet. Das hat die Beeinflussung der Wahl durch russische Gruppen ermöglicht. Als Reaktion darauf hat Facebook angefangen politische Werbung zu kennzeichnen oder einzuschränken.
Wie effektiv Facebooks Methoden zur Erkennung politischer Werbung sind, ist allerdings eine offene Frage, die Wissenschaftler:innen und Journalist:innen auf der ganzen Welt einzuschätzen versuchen. Die ersten Ergebnisse deuten darauf hin, dass es weiterhin möglich ist, mit Facebook Werbung politisch Einfluss zu nehmen ohne die Anzeigen entsprechend als politisch zu markieren.
Eine Kernfrage einer von der viadee betreuten Masterarbeit ist, wie man politische Werbeanzeigen mit Machine-Learning-Modellen erkennen kann. Das Ziel ist Wissenschaftler:innen und Journalist:innen Werkzeuge zur Bewertung von Facebooks Richtlinien für politische Werbung in die Hand zu geben. Deswegen ist es nicht nur notwendig, ein Modell zu erstellen, das politische Anzeigen korrekt erkennen kann, sondern auch nachzuvollziehen, wie dieses Model Entscheidungen trifft. Aus diesem Grund wurde nach der Erstellung eines Modells inspiziert, wie wichtig welche Informationen für das gesamte Model sind (Global Explanations) und wie diese für einzelne Vorhersagen genutzt werden (Local Explanations).
Können wir politische Inhalte erkennen?
Die Grundlage zur Erstellung eines solchen Machine-Learning-Models ist ein Datensatz, der politische und nicht-politische Facebook Werbeanzeigen enthält. Informationen über alle aktiven Facebook Werbeanzeigen und über frühere politische Anzeigen sind in Facebooks Anzeigenarchiv einsehbar. Dieses wurde genutzt, um einen Datensatz aus 49.294 Anzeigen zu erstellen, welcher die Grundlage für Training und Prüfung des Models bildet. Dabei wurden die folgenden Informationen zur Erstellung des Machine Learning-Models genutzt:
- Der Anzeigentext: Fast alle Facebook Anzeigen enthalten einen Text, der den Nutzer:innen mit der Anzeige ausgespielt wird. In den meisten Fällen enthält dieser die Kernbotschaft der Anzeige und verweist auf einen Call-to-Action. Die Analyse der Bedeutung dieses Textes ermöglicht daher Rückschlüsse auf den Inhalt und das Ziel einer Anzeige. Jedoch können Texte nicht ohne weitere Transformation von Modellen als Variablen genutzt werden. Aus diesem Grund wird die Ähnlichkeit zwischen dem Anzeigentext und Beispieltexten berechnet, die klar politisch und verschiedene Themen abdecken (z. B. Nachhaltigkeit oder Bürger:innenrechte). Zur Berechnung der Ähnlichkeit werden Satz-Embeddings genutzt die mit Sentence-BERT erzeugt werden. Dabei handelt es sich um eine State-of-the-Art-Technik aus dem Bereich Natural Language Processing (NLP). Embeddings sind Vektoren mit der Eigenschaft, dass Texte mit einer ähnlichen Bedeutung eine geringe Distanz zueinander haben. Darüber hinaus wurden zusätzlich strukturierte Informationen aus den Texten in Variablen überführt, wie die Textlänge oder die Nutzung von Emojis und Hashtags.
- Der Titel: Die meisten Anzeigen enthalten neben einem Text einen kurzen Titel. Auf Basis dieses Titels wurden ebenfalls Ähnlichkeiten als Modelvariablen berechnet.
- Der Typ der Call-To-Action: Für Facebook Anzeigen stehen 29 verschieden Call-To-Action Buttons zur Verfügung, aus denen Werbetreibende wählen können. Diese Information wird vom Modell als kategorielle Variable genutzt.
- Die Top-Level-Domain: Die meisten Facebook anzeigen enthalten einen Link zu der Webseite der Werbetreibenden. Die Domainendung (bspw. „.com“) wird als eine weitere kategorielle Variable genutzt.
- Genutzte Plattformen: Facebook-Anzeigen können über eine oder mehrere der vier Plattformen Facebook, Instagram, Messenger und dem Audience Network ausgespielt werden.
- Anzeigenformat: Facebook bietet verschiedene Anzeigenformate. Manche enthalten Bilder, andere Videos oder Kombinationen verschiedener Medienformate.
- Anteil aktuell aktiver politischer Anzeigen: Diese Variable kodiert die Information wie hoch der Anteil aller politische Anzeigen and allen aktiven Anzeigen einer Facebook Seite ist. Diese Information ist ein Proxy für die Werbehistorie einer Facebook Seite, die nicht berechnet werden kann, weil für nicht-politische Anzeigen keine Historie öffentlich verfügbar ist.
- Kategorie der Facebook Seite: Jede Facebook Seite ist einer Kategorie zugeordnet. Um diese in eine Variable zu transformieren, wird erneut die Eigenschaft von Embeddings genutzt, dass ähnliche Texte im Vektorraum eine geringe Distanz haben. Für jede Kategorie wird ihre Distanz zur Kategorie „Politische Organisation“ im Vektorraum der Embeddings berechnet.
Auf Basis dieser Variablen wurden Random-Forest-Modelle trainiert, um verschiedene Kombinationen dieser Variablen vergleichen. Für das Training wurde die Implementierung der H2O Bibliothek genutzt. Random-Forest-Modelle haben den Vorteil, dass sie nicht-lineare Zusammenhänge erkennen und es zugleich unwahrscheinlich ist, dass ein solches Model die Daten overfitted. Außerdem bieten sich diese Modelle für eine genauere Analyse der genutzten Informationen an (siehe unten). Als Benchmark wurde zudem ein einfaches lineares Modell auf Basis einer Logistischen Regression trainiert.
| Predicted | ||||
| False | True | Total | ||
| Actual | False | 4646 | 22 | 4668 |
| True | 31 | 2696 | 2727 | |
| Total | 4677 | 2718 | 7395 | |
Die abgebildete Tabelle stellt die Entscheidungen des Random-Forest-Modells bei einem Test-Set dar. Es ist in der Lage mit einer Genauigkeit von 99,28 Prozent zu erkennen, welche Anzeigen politische sind. Das lineare Benchmark Modell hat eine Genauigkeit von 98,44 Prozent. Demnach ist es möglich auf Basis der genutzten Informationen mit hoher Sicherheit zu erkennen, ob eine Anzeige politisch ist oder nicht. Was das Modell gelernt hat und wie genau es Entscheidungen trifft, ist allerdings noch nicht klar. Diese Fragen werden in den nächsten zwei Schritten beantwortet.
Was macht „politisch“? Feature Importance zur globalen Erklärung des Modells
Random-Forest-Modelle erlauben die Wichtigkeit der einzelnen Variablen beim Training des Models zu untersuchen. Das erlaubt Rückschlüsse darauf, wie wichtig diese Variablen zur Erkennung von politischen Werbeanzeigen sind. Dazu wird die Struktur dieser Modelle genutzt: Jedes Random-Forest-Modell kombiniert die Vorhersagen vieler unterschiedlicher Decision Trees (in diesem Fall 100) die alle auf Basis einer zufälligen Teilmenge der Trainingsdaten und nur mit einer zufälligen Teilmenge aller Variablen erstellt werden.
Bei jeder Verzweigung in einem dieser Modelle, wird jeweils die Variable ausgewählt, welche zu der höchsten Reduktion im Vorhersageerrors führt. Durch die Untersuchung aller Verzweigungen in allen Bäumen des Modells lässt sich herausfinden um wie viel der Vorhersagefehler durch die Nutzung bestimmter Variable verringert würde. In der folgenden Abbildung ist der relative Beitrag zur Reduktion des Vorhersagefehlers der genutzten Variablen abgebildet.
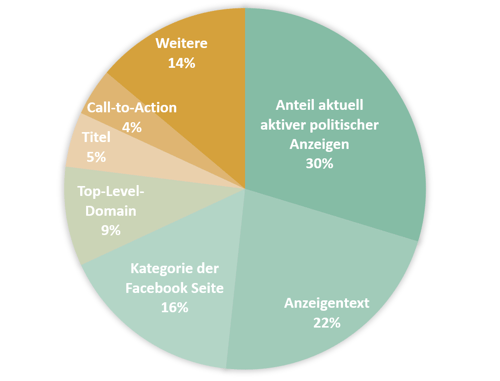
Dort kann man erkennen, dass das trainierte Modell unterschiedliche Informationen für die Entscheidung nutzt und dass vor allem die Facebook Seite, welche die Anzeige schaltet und der Anzeigentext wichtige Informationen enthalten: „Politische Seiten enthalten politische Anzeigen.“
Der Anzeigentext, der Anteil aktuell aktiver politischer Anzeigen und die Kategorie der Facebook Seite sind die drei mit Abstand wichtigsten Variablen und sind zusammen für den Großteil der Vorhersage-Performance des Modells verantwortlich. Am anderen Ende der Skala lässt sich erkennen, dass die Nutzung von Hashtags und Emojis, die genutzten Werbeplattformen und das Format der Anzeige nur wenige wichtige Informationen enthalten (alles in „Weitere“ enthalten).
Machine-Learning-Modelle, die Word-Embeddings nutzen, sind oft besonders schwer zu interpretieren. Hier wird das möglich, indem wir nicht die Embeddings selbst im Machine Learning nutzen, sondern die Distanz zu definierten Prototyp-Anzeigen im Vektorraum, die damit als interpretierbare „Leuchttürme“ fungieren können.
Die hohe Bedeutung der auf dem Anzeigentext basierenden Variablen zeigt, dass der genutzte Ansatz um strukturierte Texte in Variablen zu überführen, für die Erkennung politischer Anzeigen sinnvoll einsetzbar ist. Außerdem wird deutlich, dass das Modell in der Lage ist unterschiedliche Informationen zu berücksichtigen, die auch bei Menschen für die Beurteilung einer Werbeanzeige wichtig sind. Wie die Kernbotschaft einer Anzeige lautet und wer für die Werbebotschaft verantwortlich ist, sind auch für Menschen für die Erkennung politischer Werbung von hoher Bedeutung. Kontextuelle Informationen wie die Art der CTAs und die Nutzung von Emojis sind dabei normalerweise weniger wichtig und werden vom Modell ebenfalls so behandelt.
Diese Betrachtung hat allerdings den Nachteil, dass sie nur die globale Bedeutung von Variablen für das Modell betrachtet und keine Einschätzung möglich ist, in welche Richtung Variablen wirken (sind Anzeigen einer bestimmten Facebook Seite wahrscheinlicher oder unwahrscheinlicher politisch?) und wie sich diese auf individuelle vorhersagen auswirken. Eine solche Betrachtung ist bei Random Forest-Modellen ohne die Nutzung weiterer Tools nicht möglich, weswegen im Rahmen dieser Arbeit Shapley-Values dafür genutzt werden.
Machine Learning Debugging – Fehlerfälle mit Shapley Values untersuchen
Shapley Values sind eine Methode aus der Spieltheorie zur fairen Verteilung von Ergebnissen von kooperativen Spielen mit unterschiedlich großen Beiträgen der einzelnen Spieler:innen. Übertragen auf die Erklärung von Machine-Learning-Modellen bedeutet es, dass der Beitrag der einzelnen Variablen (ihre Verhandlungsstärke, falls sie aussteigen) berechnet wird.
In der nächsten Grafik ist das Ganze für eine fälschlicherweise als politisch klassifizierte Werbeanzeige eines Energieversorgers visualisiert. Der zu dieser Anzeige gehörende Text lautet:
„Gemeinsam bewegen wir was – für Sie und für die Umwelt. Mit 100% Ökostrom und Ökogas zu maßgeschneiderten Tarifen.“
Durch die Betrachtung der Shapley Values erkennt man, dass dieser Text den mit Abstand größten Einfluss auf die Entscheidung des Modells diese Anzeige als politisch zu klassifizieren hat. Der Grund ist, dass das Modell eine hohe Ähnlichkeit zwischen dem Anzeigentext und einem politischen Leuchtturm-Text zum Thema Umweltfreundlichkeit erkennt.
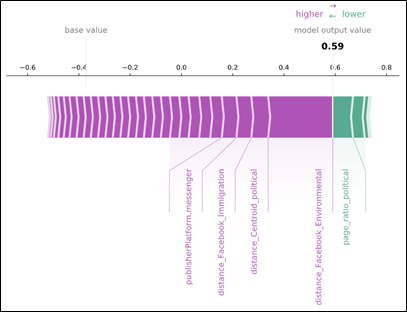
Die o. g. Feature Importances können für Einzelfälle ganz anders aussehen als im Gesamtüberblick.
Durch die Betrachtung weiterer falsch klassifizierter Anzeigen bestätigt sich die Erkenntnis, dass das Model Probleme hat, Anzeigen korrekt zu erkennen, wenn Inhalte von politischen und nicht-politischen Anzeigen sehr ähnlich sind. Das zeigt sich vor allem bei Anzeigen für Stromverträge für erneuerbare Energien (wie im Beispiel) und bei den Anzeigen von Nachrichtenherausgeber:innen.
Darüber hinaus werden auch einzelne Anzeigen von Facebook Seiten aus einem politischen Umfeld allerdings ohne politischen Inhalt als politisch klassifiziert, obwohl sie es laut Facebooks eigenen Richtlinien nicht sind. Ein Beispiel dafür sind Anzeigen der Kampagne des Bundesgesundheitsministeriums zum Tragen von Alltagsmasken während der Corona Pandemie. Diese Erkenntnisse verdeutlichen die Limitierungen des Modells und weisen auf Situationen hin, in denen die Einschätzung eines Menschen notwendig ist.

Dieser Beitrag fasst die Master-Thesis von Jan Mennen (WWU) zusammen, die betreut durch Prof. Thomas Hupperich und viadee im Herbst 2020 entstanden ist.
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



