
Wie könnte KI dazu genutzt werden, den Handel mit Bitcoins zu automatisieren? Was wären die grundlegenden Schritte und wie wäre das Ganze mit "R" umzusetzen? Folgender Beitrag zeigt dies anschaulich und gibt hilfreiche Tipps im Umgang mit KI-Methoden.
Der Begriff Künstliche Intelligenz (KI) ist in aller Munde und die damit verbundenen Erwartungen sind groß. Dennoch weiß nur eine vergleichsweise kleine Minderheit von Experten, was genau hinter diesem Begriff steckt und wie die dahinterstehenden Methoden und Algorithmen sinnvoll einzusetzen sind. Mit folgendem Beitrag soll anschaulich gezeigt werden, wie eine populäre Problemstellung mit Methoden der KI gelöst oder zumindest vereinfacht werden kann: die Suche nach optimalen An- und Verkaufspunkten beim Handel mit Bitcoins. Dabei sollen Techniken aus dem Teilbereich Machine Learning angewendet werden, worunter alle Methoden zu verstehen sind, welche Wissen aus Erfahrung generieren (Supervised Learning) oder auch neue Muster erkennen können (Unsupervised Learning).
Da der Bitcoin-Markt oder auch allgemein der Markt für digitale Währungen sehr starken Schwankungen unterworfen ist und momentan eher davon auszugehen ist, dass der Kurs langfristig weiter sinken wird, kann es aktuell nur sinnvoll sein, kurzfristige Trends und Schwankungen auszunutzen und dadurch kleine aber in Summe dennoch lohnenswerte Gewinne zu generieren. D. h. Ziel wird es sein, kurzfristige Trends zu erkennen und so schnell und so lange wie möglich auf der Welle „mitzureiten“.
Das Thema der Trenderkennung ist nicht neu: So wurden in den letzten Jahrzehnten eine Vielzahl von Indikatoren entwickelt, die anhand von Preis und/oder Handelsvolumen Trendveränderungen rechtzeitig zu erkennen versuchen. Prominente Vertreter hiervon sind:
- RSI: Aus den x letzten Kursgewinnen oder Kursverlusten wird eine sich zwischen 0 und 1 bewegende Zahl errechnet. Bewegt sich der RSI-Wert von einem hohen Niveau (z.B. > 0,8) schnell Richtung 0, sind Kursverluste wahrscheinlich. Bewegt er sich von einem niedrigen Niveau (z.B. < 0,2) schnell Richtung 1, sind Kursgewinne wahrscheinlich.
- MFI: Erweiterung des RSI durch eine Gewichtung mit dem aktuellen Handelsvolumen. Sonst ähnliche Funktionsweise.
- MACD: Hierbei werden zwei gleitende Durchschnitte gebildet, wobei ein Durchschnitt (A) auf einer höheren Anzahl von vergangenen Kurswerten basiert als der andere Durchschnitt (B). Ist B höher als A, ist davon auszugehen, dass eine kurzfristige Trendänderung ins Positive stattfindet, andersherum ins Negative.
Gesucht werden soll ein Machine Learning (ML)-Algorithmus, welcher auf Basis der aktuellen Indikatorenwerte entscheiden kann, ob es sich um einen guten Ankauf- oder Verkaufspunkt handelt. Dabei sollen Klassifikationsmethoden des überwachten Lernens (supervised learning) angewendet werden, d.h. dem KI-Algorithmus ist a priori bekannt, was die richtige Antwort in der Vergangenheit gewesen wäre (Kauf/Verkauf). Um an dieses Ziel zu gelangen, sind die folgenden Schritte notwendig, welche sich in den allermeisten KI-Projekten in ähnlicher Form wiederfinden:
- Datenextraktion, d.h. Beschaffung von Kursdaten (Preis- und Volumenentwicklung)
- Datenvorbereitung
- Markierung von guten An- und Verkaufspunkten
- Berechnung von Indikatoren
- Training (Ergebnis ist ein KI-Modell, welches Prognosen auf neuen Daten durchführen kann)
- Evaluation (funktioniert mein Modell auch auf neuen Daten?)
Im Folgenden werden diese Schritte am Beispiel der sehr prominenten OpenSource-Software "R" in Verbindung mit der Entwicklungsumgebung R-Studio vorgestellt.
1. Datenextraktion
Als gute Datenquelle eignet sich die GDAX-REST-API von Coinbase (https://docs.gdax.com). Neben vielen anderen Daten lassen sich hier unter anderem historische Handelsdaten in der Granularität von einer Minute bis hin zu einem Tag über mehrere Monate herunterladen, jedoch maximal 300 Datenpunkte per Download. Enthalten sind dabei folgende Informationen:
- Time: Startzeit des Intervalls im Unix-Zeit-Format (Sekunden seit 01.01.1970)
- Low: Niedrigster Preis während Intervall
- High: Höchster Preis während Intervall
- Open: Preis zur Startzeit des Intervalls
- Close: Preis zum letzten Zeitpunkt im Intervall
- Volume: Gehandeltes Gesamtvolumen im Intervall (Käufe und Verkäufe)
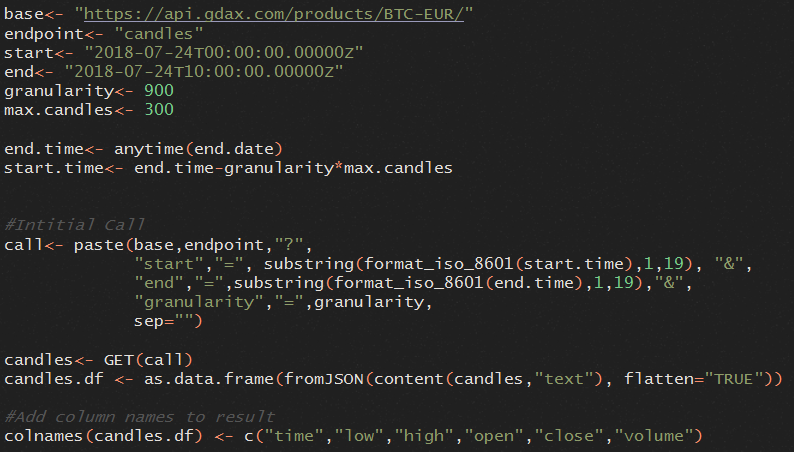
Um Daten über einen längeren Zeitraum von z. B. mehreren Monaten zu extrahieren, ist das Schreiben eines R-Programms notwendig, welches die Parameter start, end und granularity wiederholt an den Rest-Service übermittelt und die zurückgelieferten JSON-Dokumente in der richtigen Reihenfolge zusammenfügt und diese in die R-Datenstruktur DataFrame überführt, welche die Basis für weitere Analysen ist. Folgender Code kann für einen Aufruf genutzt werden (für den HTTP-Get-Request wird hier die R-Bibliothek „httr“ verwendet):
2. Datenvorbereitung
Je nach Machine Learning-Modell sind unterschiedliche Schritte der Datenvorbereitung sinnvoll. In diesem Fall wollen wir ein Modell entwickeln, dass Datenpunkte richtig klassifiziert und anhand von vergangenen „richtigen Entscheidungen“ lernt. In ML-Terminologie hieße dies: Wir wollen ein Klassifikationsmodell des Typs Supervised Learning entwickeln. Damit ein Modell dieses Typs sinnvoll trainiert werden kann, sind mindestens zwei Dinge essenziell: (1) geeignete Features, d. h. Attribute, welche jeden vorhandenen Datenpunkt so gut wie möglich aber nicht mehr als nötig charakterisieren, damit ein Modell Gesetzmäßigkeiten und wiederkehrende Muster erkennen kann; (2) beschriftete Daten (engl. Labled Data), d. h. die Datenpunkte müssen um die Information angereichert sein, zu welcher Klasse, d. h. in diesem Fall Kaufen, Verkaufen oder Warten, sie gehören.
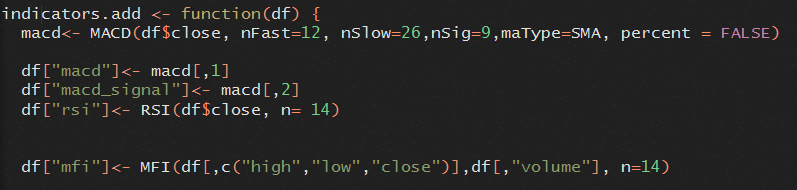
Teil 1 ist bereits teilweise abgedeckt, da die heruntergeladenen Daten bereits die Informationen Preis und Volumen enthalten. Um Trends in der Preisentwicklung besser erkennen zu können, sollen zusätzlich die eingangs erwähnten Indikatoren RSI, MFI und MACD aus den Daten berechnet werden. Hierfür kann die bereits bestehende R-Bibliothek „quantmod“ verwendet werden, die mit wenigen Zeilen Code die zusätzlichen Daten generieren kann:
Teil 2 ist nicht ganz so leicht, denn es gibt nicht die „eine“ richtige Handelsstrategie, sondern vielmehr risikoreiche oder risikoarme Strategien. Zusätzlich können meistens mehrere Punkte als richtiger Ein- oder Ausstiegspunkt angesehen werden, insbesondere dann, wenn der Kurs für eine gewisse Zeit stabil bleibt. Nun könnte ein Mensch relativ schnell auf einen Blick gute oder schlechte Bereiche in der Vergangenheit identifizieren, doch für das Ziel des automatisierten Handels ist dies nur bedingt sinnvoll. Deshalb soll mit einem automatischen Algorithmus nach vergangenen geeigneten Kauf- und Verkaufspunkten gesucht werden. Hierfür wurde ein R-Skript geschrieben, welches vereinfacht folgende Schritte durchführt:
- Schritt 1: Es wird über alle Datenpunkte iteriert und alle 50 Punkte das Minimum sowie das Maximum markiert.
- Schritt 2: Nicht sinnvolle Minima/Maxima werden entfernt, d. h. wenn z. B. ein Maximum auf ein Maximum folgt oder wenn ein Maximum nicht mehr als eine ein-prozentige Preissteigerung zum vorherigen Minimum aufweist.
- Schritt 3: Die verbliebenen Minima/Maxima werden als Kauf- bzw. Verkaufspunkte und die restlichen Punkte als Wartepunkte deklariert.
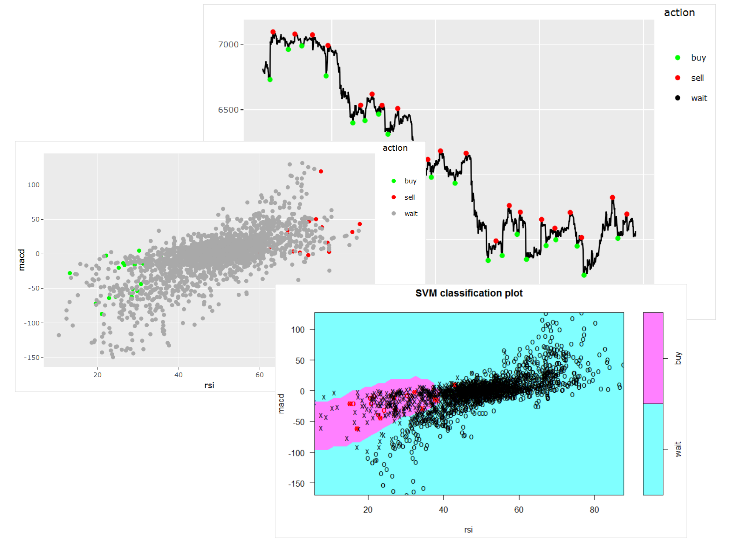
Mittels der R-Bibliothek GGPLOT können wir das Ergebnis der Datenvorbereitung kompakt darstellen und auch direkt versuchen, mögliche Muster zu erkennen:
Es wird beispielsweise sichtbar, dass der RSI-Indikator bei Einstiegspunkten (Kaufen) immer ein relativ niedriges Niveau aufweist, während er bei Ausstiegspunkten (Verkaufen) ein sehr hohes Niveau hat. Ein zusätzlicher Scatter-Plot kann genutzt werden, um dies zu untermauern:

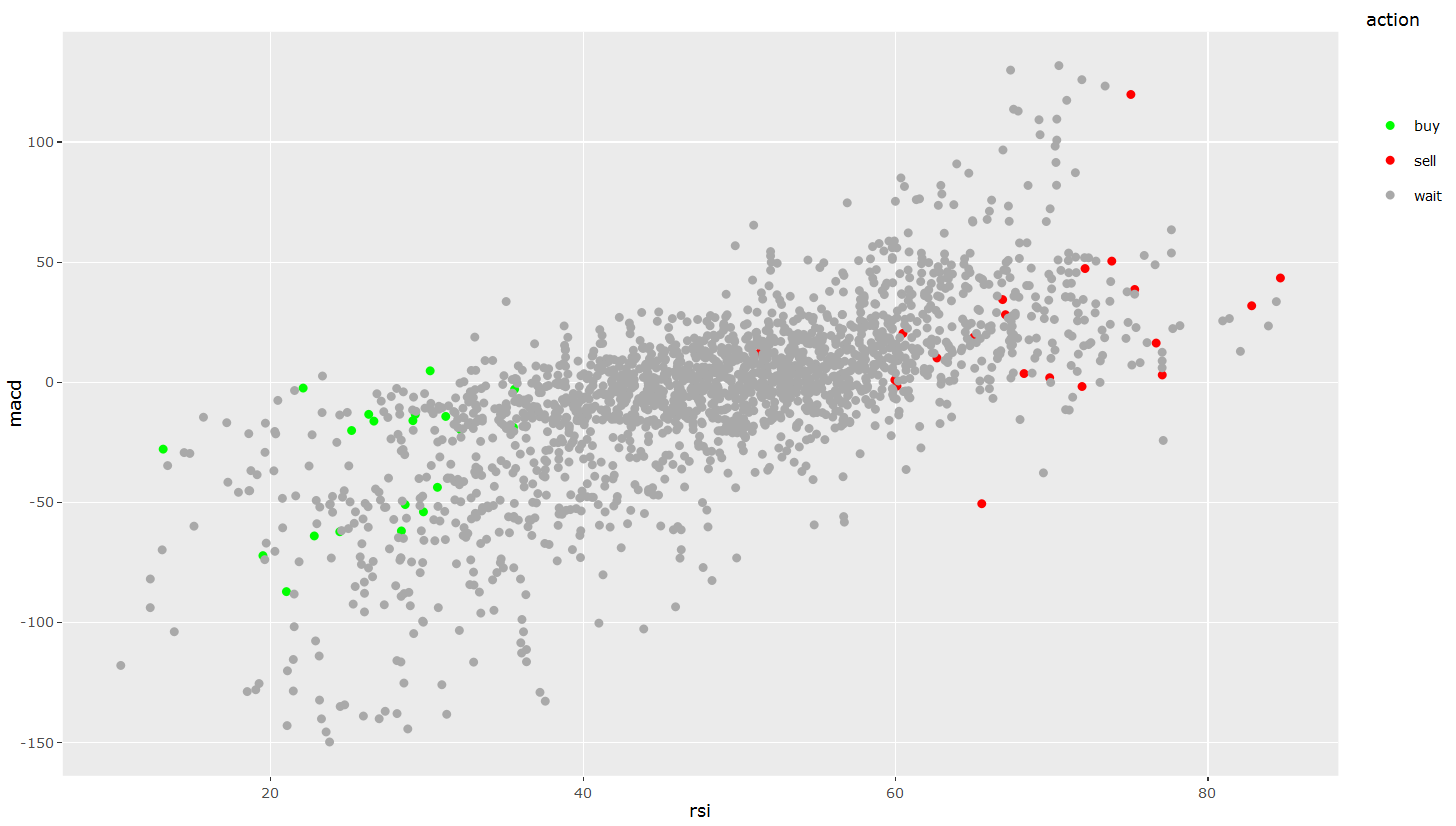
Wir können auf einen Blick ein deutliches Muster erkennen. Dies ist immer ein guter Indikator dafür, dass die Anwendung eines Machine Learning-Modells sinnvoll sein könnte. Es kann jedoch genauso gut auch sein, dass das Muster nur in den aktuell betrachteten Daten vorkommt und nicht vollständig generalisierbar ist.
Was in der Grafik ebenfalls auffällt, ist, dass die Kauf- und Verkaufspunkte eine vergleichsweise kleine Minderheit darstellen und dass die Wartepunkte sowohl in die Kauf- als auch die Verkaufspunkte hineinstreuen. Dies ist für Prognosemodelle ein Problem: Denn ihr oberstes Ziel ist es, so viele Punkte wie möglich richtig einzuordnen. Sind 99 % der Punkte vom Typ „Warten“, ist die logische Konsequenz, dass hauptsächlich „Warten“ als Ergebnis zurückgegeben wird, da so das Modell für die vorliegenden Daten die höchstmögliche Präzision erlangt. Aushelfen können hier die Strategien Oversampling (die Instanzen der Klassen mit dem geringeren Auftreten werden vervielfacht) und Undersampling (die Instanzen der Klassen mit dem häufigeren Auftreten werden reduziert). Für diesen Fall wurde Oversampling angewendet unter Verwendung der R-Bibliothek „Rose“.
3. Training
Das Trainieren eines neuen Modells in "R" benötigt vergleichsweise wenige Zeilen Code, was jedoch nicht bedeutet, dass es hier keine Fallstricke gibt. Ganz entscheidend für die Güte des Modells ist, welcher Modelltyp mit welchen Parametern gewählt wird. So eignen sich manche Modelle (z. B. Logistische Regression) besonders gut, um Daten zu klassifizieren, die linear trennbar sind, d. h. Daten, die sich z. B. im zweidimensionalen Raum durch eine gerade Linie sinnvoll voneinander trennen lassen. Andere Modelle wie Decision Trees, Support Vector Machines und insbesondere Neuronale Netze sind besser geeignet, um komplexe Zusammenhänge zu erkennen, sind jedoch häufig schwer zu interpretieren und zu konfigurieren. Generell sollte gelten: Ein Modell sollte nur so komplex wie nötig sein und es sollte nicht „mit Kanonen auf Spatzen geschossen werden“.
Für den hier beschriebenen Fall wurde als Vorhersagemodell eine Support Vector Machine (SVM) auf Basis der Indikatoren MACD und RSI gewählt. Eine SVM hat den Vorteil, dass sie auch komplexe Entscheidungsgrenzen abbilden kann und weniger zu Overfitting neigt (d. h. dass zu viele Spezialfälle gebildet werden, die genau zu den aktuellen Daten, nicht aber zu neuen Daten passen), wie z. B. Decision Trees. Vereinfacht gesagt versucht eine SVM, eine Entscheidungsgrenze zu finden, welche mithilfe von Instanzen der jeweiligen Klasse (den Support Vectors) gebildet wird. Mit dem sogenannten Kernel-Trick wird dabei eine Transformation in einen höherdimensionalen Raum durchgeführt, sodass eine einfachere/lineare Trennung möglich ist. (Diese Transformation ist mathematisch nicht ganz einfach, weswegen eine genaue Erklärung außerhalb des Rahmens dieses Beitrags liegt).
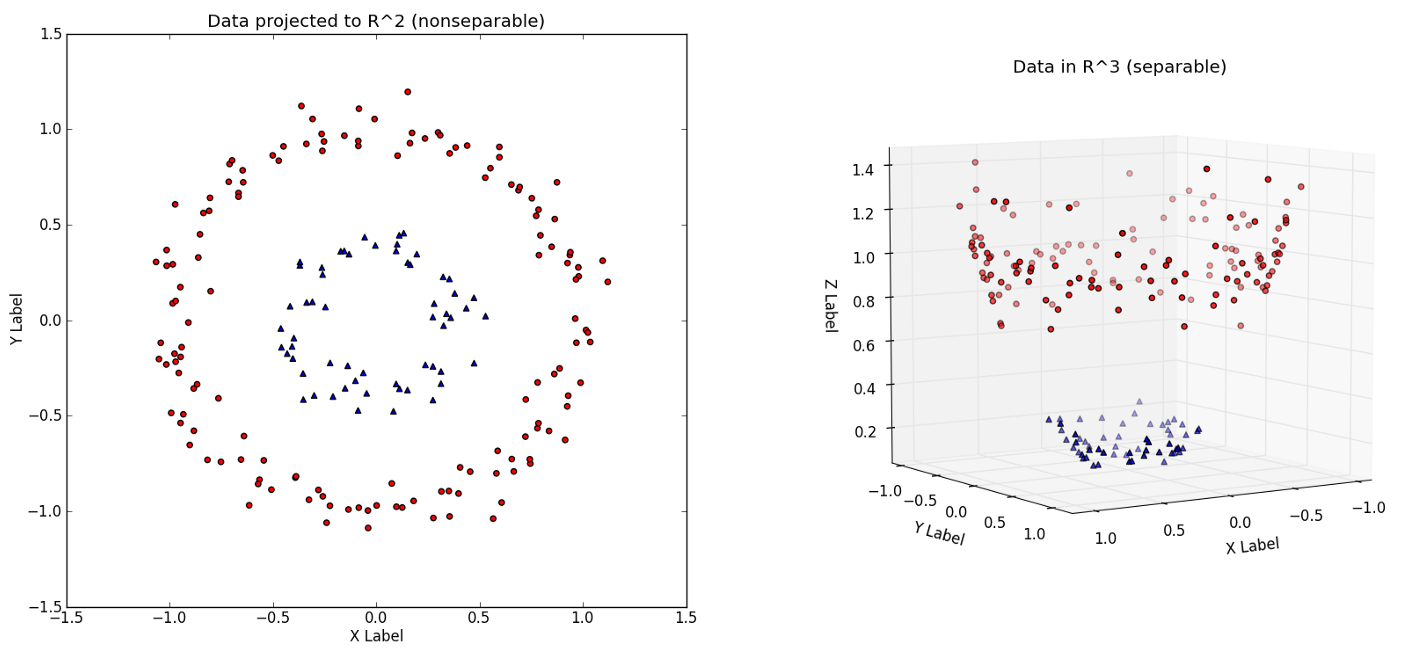
Durch Wahl eines bestimmten Kernels kann die Form des Grenzverlaufs beeinflusst werden. Bspw. sorgt ein Radial-Kernel für einen kreisförmigen Verlauf, welcher im konkreten Anwendungsfall am besten für die Trennung der Kauf- und Verkaufspunkte von den Wartepunkten ist.
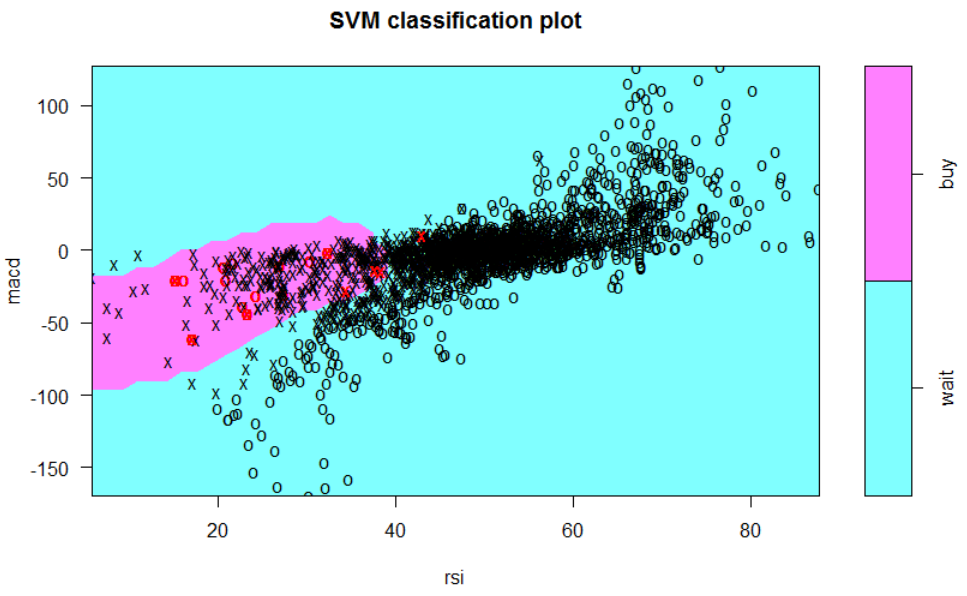
Mit folgenden Anweisungen wird zuerst ein SVM-Model trainiert (mit gamma und cost kann die Form des Grenzverlaufs bzw. Pönalisierung von Ausreißern kontrolliert werden), anschließend visualisiert und eine Confusion Matrix (Vergleich Trainingsdaten/Reference mit Vorhersage/Prediction) sowie Präzisionsmaße generiert.

Die zugrunde liegenden Daten sind in diesem Fall alle Kauf- und Wartepunkte, da ein binäres Entscheidungsproblem leichter zu kontrollieren ist.
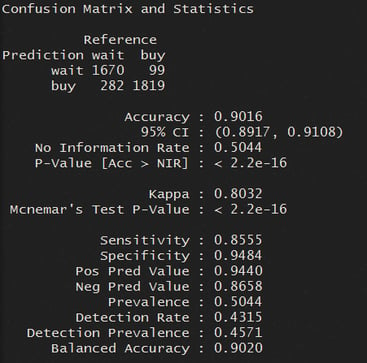
 Wir können erkennen, dass ca. 90 % der Klassen korrekt vorhergesagt wurden. Konkret wurden von 1670+282 Wartepunkten bzw. 99+1819 Kaufpunkten in den Trainingsdaten 1670 bzw. 1819 Punkte korrekt vorhergesagt.
Wir können erkennen, dass ca. 90 % der Klassen korrekt vorhergesagt wurden. Konkret wurden von 1670+282 Wartepunkten bzw. 99+1819 Kaufpunkten in den Trainingsdaten 1670 bzw. 1819 Punkte korrekt vorhergesagt.
Gleiches wird nun auch mit den Verkaufs- und Wartepunkten durchgeführt, sodass anschließend zwei Modelle, eines für Kaufen und eines für Verkaufen trainiert sind.
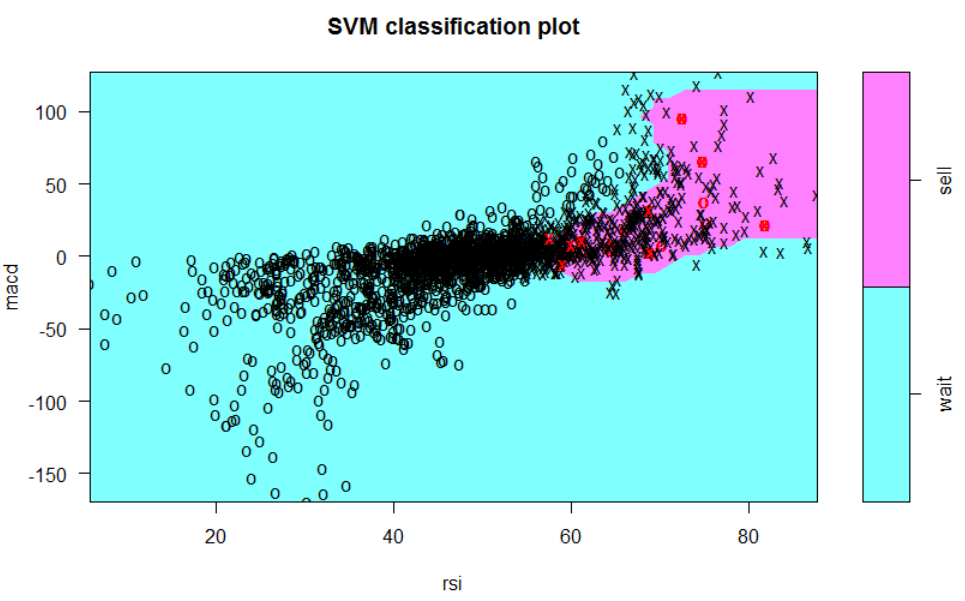
Beide Modelle können nun zusammen verwendet werden, um auf neuen Daten Kauf- und Verkaufs-Entscheidungen zu treffen: Wird Kaufen vorhergesagt, wird gekauft, falls zuvor verkauft oder noch keine Aktion durchgeführt wurde - wird Verkaufen vorhergesagt, wird verkauft, sofern zuvor gekauft wurde.
4. Evaluation
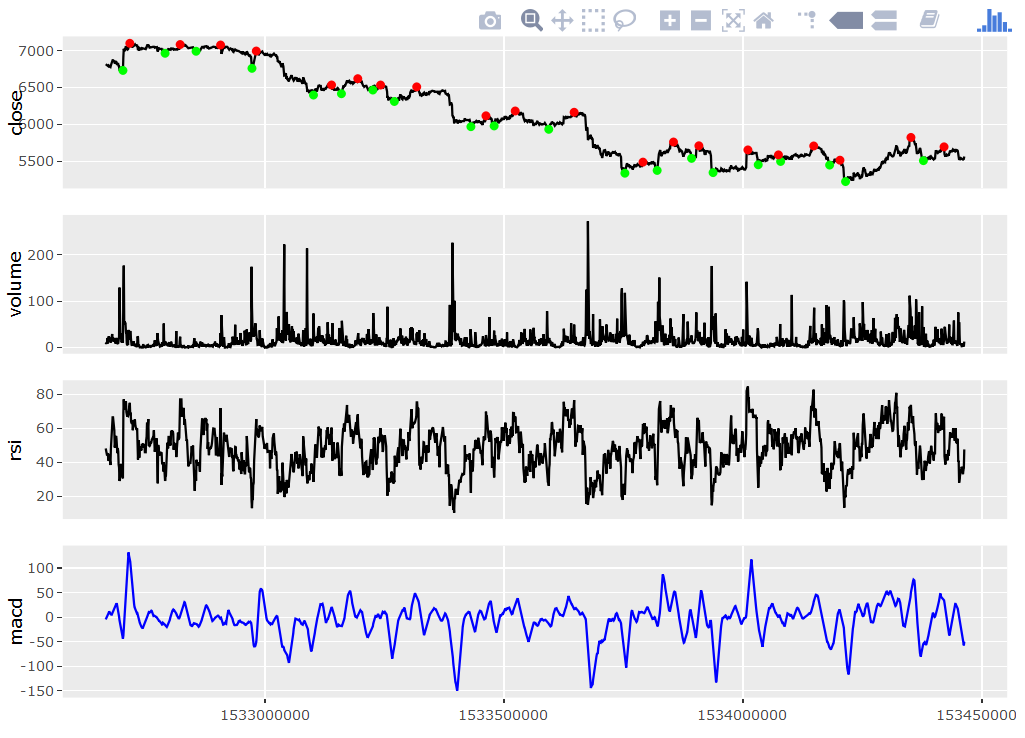
Das wirklich Interessante ist nun: Wie funktioniert das Modell (bzw. beide Modelle) auf neuen Daten? Hierzu wird ein neues Datenset mithilfe der GDAX-API (wie weiter oben beschrieben) heruntergeladen, dieses Mal ausgehend vom 30.06.2018 10 Tage in die Vergangenheit (der letzte Download begann am 17.06.2018).
Anschließend werden wieder mithilfe des oben beschriebenen Algorithmus automatisch „gute“ Kauf- und Verkaufspunkte bestimmt (Labeling) und schließlich versucht, diese mithilfe der beiden Modelle möglichst gut zu treffen.

In der folgenden Grafik wird sichtbar, dass dies nur zum Teil gelingt: Es werden zwar einige Gewinne realisiert, doch insbesondere der große Kursabstieg in der Mitte wird nur unzureichend abgefedert. Dies liegt vor allem daran, dass noch kurz vor Beginn des Abstiegs ein Kaufsignal prognostiziert wurde und ein geeigneter Verkaufspunkt anschließend nicht rechtzeitig gefunden werden konnte. Hier wäre die Einführung einer Verlustgrenze überlegenswert, z. B. „Verkaufe immer, wenn bereits mehr als x % Verlust drohen“.
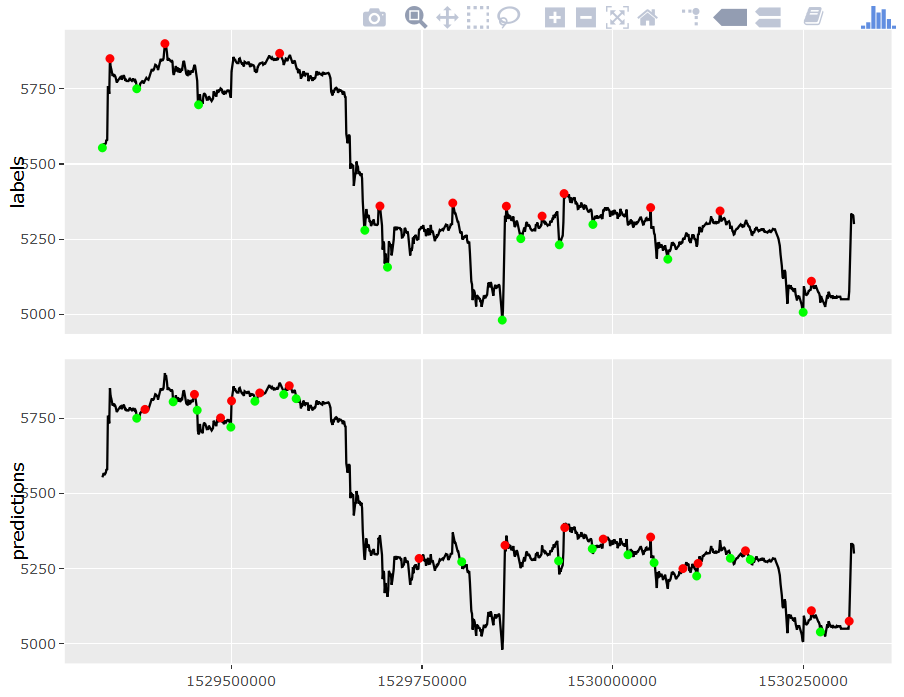
Generell ist dies nur ein erster Schritt in die richtige Richtung. Es müssen noch viele weitere Validierungen durchgeführt und Kombinationen anderer Indikatoren und ML-Modelle untersucht werden. Bspw. muss auch berücksichtigt werden, dass Transaktionskosten beim An- und Verkauf von digitaler Währung entstehen können, was einen starken Einfluss auf die realisierten Gewinne haben kann. Dennoch sollte bereits jetzt deutlich geworden sein, wie der Weg zu einem funktionierenden KI-Modell aussehen kann und welche typischen Fallstricke auf dem Weg dorthin lauern. Insbesondere sollte mitgenommen werden, dass Machine Learning bzw. KI kein Hexenwerk (mehr) ist und durch kostenfreie, ausgereifte und gut dokumentierte Software (wie z. B. "R") zunehmend demokratisiert wird. Die Einstiegshürden werden zusätzlich durch eine immer größere Anzahl kostenfreier Schulungen gesenkt (für eine gute Übersicht siehe hier).
Um immer am „Puls der Zeit“ zu sein, besitzt die viadee einen eigenen Forschungs- und Entwicklungsbereich, der mit Hochschulkooperationen, Schulungen und natürlich Forschungsprojekten dazu beträgt, dass das Unternehmen ein kompetenter Ansprechpartner ist und bleibt. Näheres zum F&E-Bereich finden Sie hier.
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



