

Von SAS ausgeführte SAS-Programme schreiben stets Log-Ausgaben, die sich vielfältig nutzen lassen. Im vorliegenden Projekt wurde die Zuordnung von ETL-Prozessen zu den Datenbeständen, die durch die Prozesse gelesen und geschrieben werden, aus solchen Logs extrahiert, sodass die Data Lineage dokumentiert und Impact-Analysen erleichtert werden.
Verlässliche Doku zur Data Lineage
Metadaten werden gerne als DNA eines Data Warehouses (DWH) bezeichnet, weil sie als zentrales Instrument zur Steuerung, Planung und Überwachung der Datenbewirtschaftung dienen können. Zu den nützlichsten Metadaten im DWH-Bereich zählen Informationen, die die Frage beantworten, welcher ETL-Prozess welche DWH-Daten einliest, überschreibt oder ändert und in welchem Turnus er dies tut. Diese Art Metadaten können die Anforderung erfüllen, die Data Lineage zu dokumentieren, also die „Abstammung“ oder Herkunft der DWH-Daten. Anhand der Lineage kann z. B. eine oft komplexe Kennzahl wie „Neugeschäft“ zurückverfolgt werden zu den genauen Quelldaten, die zu ihrer Berechnung verwendet werden. Die Dokumentation der Data Lineage wird im Rahmen von Data-Governance-Initiativen immer mehr zum regulatorisch geforderten Standard im DWH-Umfeld.
Metadaten sollten aber nicht durch manuelle Erfassung oder Pflege gesammelt werden müssen – nur ein automatisiertes Vorgehen verspricht hier die notwendige Vollständigkeit und Genauigkeit der Dokumentation. Doch nicht alle ETL-Plattformen stellen Metadaten auf komfortable Weise bereit. Gerade in Legacy-Systemen stellt die automatisierte Extraktion von Metadaten oft eine Herausforderung dar. In diesem Beitrag beschreiben wir, wie man aus Logdateien von mit SAS erstellten ETL-Prozessen die wichtigsten Metadaten extrahieren kann.
Damit kann stets nachvollzogen werden, welche Prozesse welche Daten lesen und schreiben, wie viele Daten es sind und zu welchen Zeiten die Prozesse laufen. Diese Informationen sind äußerst nützlich für die Dokumentation der Data Lineage, aber auch für die Fehlerverfolgung oder die Impact Analyse bei der Planung von Änderungen an Datenmodellen oder ETL-Prozessen.
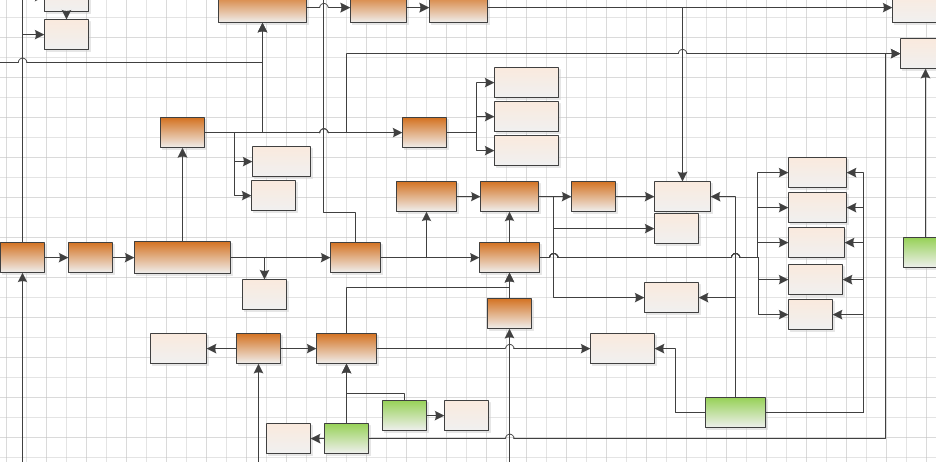
Start: Log-Dateien sammeln
Wir gehen in diesem Beitrag davon aus, dass eine Menge von SAS-Programmen vorliegt, die zu unterschiedlichen Zeiten regelmäßig ausgeführt werden und dabei auf eine gewisse Menge von SAS-Tabellen in ggf. unterschiedlichen SAS-Bibliotheken lesend und/oder schreibend zugreifen. Ziel ist die automatisierte Erstellung eines Metadatenbestands (in SAS oder einer beliebigen Datenbank), welcher dokumentiert,
- welches SAS-Programm wann gelaufen ist,
- welches SAS-Programm auf welche SAS-Tabellen lesend zugreift,
- welches SAS-Programm welche SAS-Tabellen erstellt oder schreibend ändert,
- wie viele Datensätze von den jeweiligen SAS-Programmen gelesen oder geschrieben wurden.
Basis für diese Informationen sind die Log-Dateien der ausgeführten SAS-Programme. Diese lassen sich je nach Betriebsplattform auf unterschiedliche Weise sammeln. Unter Windows oder Linux lässt sich das SAS-Log problemlos in Dateien ausgeben, beispielsweise mit der SAS-Systemoption ALTLOG. Die einzelnen Logs können für die hier beschriebene Extraktion auch verkettet werden, solange in der Gesamtdatei die Abschnitte für die einzelnen Logs erkennbar sind (ein guter Indikator für den Beginn eines neuen Logs ist die Zeichenkette „Copyright (c) … by SAS Institute“, das Ende eines Logs kann anhand von „The SAS session used … CPU seconds“ erkannt werden). Auch auf Mainframe-Plattformen ist dies grundsätzlich möglich, allerdings gibt es hier oft Restriktionen durch die Architektur der Dateizugriffsrechte. Im vorliegenden Projekt in einer Mainframe-Umgebung ist der Druck der Jobprotokolle aus dem IBM-Systemtool „Beta92“ in eine sequenzielle Datei der einfachste Weg, SAS-Logs aller in einem bestimmten Zeitraum ausgeführten Jobs zu sammeln. Dabei sind die SAS-Logs eingebettet in das gesamte Jobprotokoll, das zusätzlich Informationen zu verwendeten Dateien und zur Ausführungszeit enthält. Diese Informationen können daher ebenfalls genutzt werden. Unter Windows oder Linux können diese „SAS-externen“ Informationen auf andere Weise leicht protokolliert werden.
Vorbereitung der SAS-Logs
Ausgehend von einer Datei, die die gewünschten SAS-Logs enthält, nutzen wir ein weiteres SAS-Programm zur Analyse dieser Logs. Dabei wird ausgenutzt, dass SAS (mit geeigneten Einstellungen) alle tatsächlich ausgeführten SAS-Statements in aufbereiteter Form ins Log schreibt. Aufbereitet bedeutet zum Beispiel, dass Kommentare in der „/*“-Syntax bereits entfernt und – besonders nützlich – Makrovariablen aufgelöst sind.
Als Beispiel betrachten wir folgenden Auszug aus einem SAS-Programm:
PROC SQL;
CREATE TABLE ZIEL.ERGEBNIS AS
SELECT A, B, C
/* Lese Quelle je nach Vorgabe */
FROM QUELLE.&EINGABE.
WHERE DATUM = …;
QUIT;
Wird das Programm mit SAS ausgeführt, so wird dieser Code, inklusive Kommentar, im SAS-Log wiederholt, sodass man ihn analysieren könnte. Dabei fügt SAS Zeilennummern und gelegentliche „NOTE:“-Meldungen ein, die leicht zu ignorieren sind. Allerdings bleibt hierbei der Kommentar erhalten und die Makrovariable EINGABE wird nicht aufgelöst, sodass nicht erkennbar ist, auf welche Tabelle letztlich zugegriffen wurde. (Bei einem Zugriff mit SET innerhalb eines DATA-Steps würde die im Log folgende „NOTE: There were X observations read from the data set…“ den aufgelösten Wert von EINGABE zeigen, doch bei PROC SQL fehlt diese Logausgabe.)
Wenn allerdings das obige Programm in ein Makro eingebettet ist und die SAS-Option MPRINT (in älteren SAS-Versionen MACROGEN) eingeschaltet ist, so schreibt SAS eine standardisierte Form aller SAS-Statements ins Log, die mit MPRINT(Makroname) eingeleitet wird:
MPRINT(AUSFUEHREN): PROC SQL;
MPRINT(AUSFUEHREN): CREATE TABLE ZIEL.ERGEBNIS AS SELECT A, B, C FROM QUELLE.tabelle1 WHERE …;
MPRINT(AUSFUEHREN): QUIT;
Hier wurde von SAS bereits der Kommentar entfernt und die Makrovariable aufgelöst. Im hier behandelten Projekt wurde daher dafür gesorgt, dass alle SAS-Prozesse in Makros eingebettet sind und einheitlich MPRINT nutzen. Dann benötigt man für die Analyse nur die Zeilen, die mit „MPRINT“ beginnen (für die Extraktion der Anzahl Datensätze je Tabelle allerdings auch die mit „NOTE:“ beginnenden Zeilen). Entfernt man nun noch den Zeilenbeginn bis zum Doppelpunkt, so hat man ein standardisiertes SAS-Log, in dem alle tatsächlich ausgeführten SAS-Statements enthalten sind. Längere Statements erstrecken sich ggf. über mehrere Zeilen, doch da jedes Statement mit Semikolon endet, lassen sich die Zeilen leicht zu einem Gesamtstatement zusammensetzen. Man sollte übrigens in produktiven Projekten durchaus mit Statements von mehreren tausend Zeichen Länge rechnen!
Code-Teile, die aufgrund einer Makro-Bedingung nicht ausgeführt wurden, fehlen allerdings in diesen aufbereiteten Logs. Ziel ist jedoch die Dokumentation der tatsächlich ausgeführten Prozesse.
Extraktion von Metadaten
Im letzten Schritt soll erkannt werden, welche SAS-Tabellen ein SAS-Programm liest und/oder schreibt. Dabei machen wir uns zunutze, dass der Zugriff auf SAS-Tabellen im standardisierten Log (außer im Fall der WORK-Bibliothek) immer anhand der Notation „SAS_LIB.Tabellenname“ erfolgt, wobei SAS_LIB ein maximal 8-stelliges alphanumerisches Kürzel ist und die möglichen Ausprägungen dieses Kürzels in aller Regel vorab bestimmt werden können. Mit anderen Worten, wenn eine Liste der SAS-Bibliotheksreferenzen (librefs, also in LIBNAME-Statements vergebenen Bibliotheksnamen) vorliegt, so kann jedes Vorkommen im standardisierten Log einer Zeichenkette nach dem Muster „libref.irgendwas“ als Erwähnung der SAS-Tabelle „irgendwas“ gedeutet werden. Kommt die Zeichenkette also innerhalb des SAS-Logs eines bestimmten SAS-Programms vor, so kann geschlossen werden, dass dieses Programm auf diese Tabelle zugreift. Aber ist der Zugriff lesend oder schreibend?
Ohne einen SAS-Syntaxparser kann diese Frage nicht mit letzter Sicherheit beantwortet werden – doch gibt die üblicherweise verwendete SAS-Syntax genügend Hinweise, um die Unterscheidung in „lesend“ oder „schreibend“ heuristisch vorzunehmen und in den allermeisten Fällen richtig zu liegen. Im obigen Beispiel liefert das Schlüsselwort CREATE den Hinweis, dass auf ZIEL.ERGEBNIS schreibend zugegriffen wird, während FROM zeigt, dass QUELLE.tabelle1 nur gelesen wird. Möglicherweise wird auf QUELLE.tabelle1 an anderer Stelle im selben SAS-Programm schreibend zugegriffen – dann ergibt sich auf Ebene des Programms natürlich insgesamt ein schreibender Zugriff, aber an der genannten Stelle ist der Zugriff lesend.
Die SAS-Statements aus dem standardisierten Log werden also Wort für Wort bzw. Token für Token durchlaufen. Als Trennzeichen für die Tokenbildung haben wir Leerzeichen, runde Klammern, Komma, Gleichheitszeichen und Bindestrich verwendet. Auf jedes Token wird zunächst die SAS-Funktion dequote() angewandt, falls deren Ergebnis nicht leer ist.
Kommentare in *-Notation sind im standardisierten Log noch enthalten. Zwischen * und dem nächsten Semikolon sind daher alle Token zu ignorieren, außer bei der Konstruktion SELECT * FROM.
Entspricht ein Token einem SAS-Schlüsselwort, so wird die Erkennung nachfolgender SAS-Tabellen entsprechend behandelt. Die folgenden Schlüsselwörter zeigen schreibenden Zugriff an:
UPDATE, OUT, BASE, CNTLOUT, CREATE, OUTPUT, DELETE, ALTER, INSERT, DATA
Diese Schlüsselwörter gehen lesendem Zugriff voraus:
IN, CNTLIN, FROM, DATASET:, MERGE, SET, JOIN
Hierbei ist der Spezialfall zu beachten, dass FROM einen schreibenden Zugriff anzeigt, falls es innerhalb der Konstruktion DELETE FROM genutzt wird. DATA kann innerhalb von PROC SORT sowohl lesend als auch schreibend verwendet werden, je nach Vorhandensein der OUT=-Option.
Je nach den verwendeten Programmierkonventionen lassen sich mit diesen Regeln und ggf. ein paar spezifischen „Tunings“ schon 99 % der Zugriffe korrekt klassifizieren. Das Ergebnis ist eine Tabelle, die für jedes SAS-Programm die gelesenen und geschriebenen SAS-Tabellen anzeigt.
Ziel erreicht: Impact-Analyse, Lineage-Doku u.v.m.
Ergebnis der beschriebenen Extraktion ist eine Zuordnung der Schreib- und Lesevorgänge zu den durchführenden SAS-Programmen. In einer typischen Kette von datenverarbeitenden SAS-Programmen kann man sich also anhand dieser Zuordnung leicht vorwärts und rückwärts durch die Datenflüsse hangeln: Liest das Programm B eine SAS-Tabelle, die durch Programm A geschrieben wird, so hängt B von A ab bzw. folgt auf A. Auch eine grafische Darstellung der Datenflüsse ist mit entsprechenden Werkzeugen automatisiert erstellbar. Damit ist ein wichtiger Bestandteil von Data-Lineage-Anforderungen erfüllt. Auch die Analyse der Auswirkungen anstehender Änderungen an Quell- oder Zieldaten (Impact-Analyse) wird deutlich erleichtert. Die Vollständigkeit der Dokumentation ist durch das automatisierte Verfahren gegeben. Die Grundlage für eine vielseitig nutzbare Metadaten-Basis kann somit auch in Legacy-Systemen der hier vorgestellten Art mit relativ geringem Aufwand gelegt werden.
Autor
 Dr. Timm Euler war bis September 2020 Senior-Berater bei der viadee IT-Unternehmensberatung und Leiter des F&E-Bereichs Business Intelligence.
Dr. Timm Euler war bis September 2020 Senior-Berater bei der viadee IT-Unternehmensberatung und Leiter des F&E-Bereichs Business Intelligence.
Er interessiert sich für alles rund um Big Data, Data Warehousing und Data Mining.

zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



