
 Um mit DMN-Tabellen getroffene Entscheidungen zu verbessern, kann es sich lohnen, einen strukturierten, experimentellen Ansatz z.B. auf Basis von Multi-Armed Bandits zu verfolgen. Architektonisch ist DMN eine Investition in Flexibilität – Warum nutzen wir sie nicht gezielt?
Um mit DMN-Tabellen getroffene Entscheidungen zu verbessern, kann es sich lohnen, einen strukturierten, experimentellen Ansatz z.B. auf Basis von Multi-Armed Bandits zu verfolgen. Architektonisch ist DMN eine Investition in Flexibilität – Warum nutzen wir sie nicht gezielt?
Problem: Brachliegende Flexibilität
Die Decision Model & Notation (DMN) ist eine Modellierungssprache für Entscheidungsregeln. Ein Kernbestandteil von DMN sind Entscheidungstabellen, die die Regeln bzw. Entscheidungslogik abbilden, auf deren Grundlage eine Entscheidung getroffen wird.
DMN glänzt oft im Zusammenspiel mit der BPMN (Business Process Model and Notation), denn sie ermöglicht es, Entscheidungslogik aus BPMN-Prozessmodellen auszulagern, um Sie getrennt verwalten zu können. Zum einen macht dieses Vorgehen Prozessmodelle übersichtlicher und lesbarer, zum anderen erlaubt DMN dadurch flexibleres, agileres Management von Entscheidungsregeln, da bei der Änderung einer Regel nicht mehr das ganze Prozessmodell, sondern lediglich das DMN Modell angepasst werden muss.
In der Praxis aber werden DMN-Tabellen einmal angelegt und bleiben dann häufig ohne weitere Änderungen so bestehen oder werden nur bedarfsgetrieben angepasst oder erweitert. Eine gezielte, kontinuierliche Anpassung der DMN-Tabellen, um damit die Verbesserung der Entscheidungs-Performance zu erreichen, ist selten. Gründe dafür sind:
- das mit Veränderungen von Entscheidungsregeln einhergehende Risiko Fehler zu machen und
- die Unsicherheit von tatsächlich erzielbaren Verbesserungen, zum anderen aber auch
- der hohe Aufwand, um ein solches Verfahren systematisch zu betreiben.
Können wir ein Verfahren entwickeln, das zum einen Risiko und Unsicherheit, aber auch den Aufwand von Änderungen verringert, um kontinuierlich DMN-Tabellen anzupassen und somit die Performance von Entscheidungen stetig zu verbessern? Process Engines und DMN-Tabellen sind eine „Investition in Flexibilität“, die letztlich ungenutzt bleibt, solange DMN-Tabellen sich nur selten verändern.
Letztlich erreicht man mit gut orchestrierten Machine-Learning-Schritten in Geschäftsprozessen etwas Vergleichbares. Dabei opfert man aber viel Transparenz von Entscheidungen und die gezielte Veränderbarkeit von Regeln. Wie sähe stattdessen eine Übertragung dieser Ansätze zu „lernenden DMN-Tabellen“ aus?
Lösungsansatz: Ein kontinuierlicher Verbesserungsprozess
Es braucht einen zweistufigen Prozess, um die kontinuierliche Verbesserung der DMN-Regeln zu unterstützen.
Die erste Prozessstufe dient der Vorbereitung, um einen kontinuierlichen Verbesserungsprozess für DMN-Tabellen wirksam betreiben zu können. Im ersten Schritt müssen die DMN-Tabellen einer Organisation identifiziert werden, die tatsächlich für eine kontinuierliche Verbesserung geeignet sind. Diese müssen anschließend für die Implementierung eines Verbesserungsprozess priorisiert werden.
Um die Eignung von DMN-Tabellen für einen kontinuierlichen Verbesserungsprozess zu bewerten, wurde ein Klassifikationsrahmen entwickelt, der hierfür relevante Eigenschaften von DMN-Tabellen enthält.
Zu betrachten sind Entscheidungs- und Regel-bezogene Eigenschaften von DMN-Einsätzen.
- Einer der wichtigsten „Filter“ in diesem Zusammenhang ist die Verfügbarkeit von Feedback zu einer Entscheidung, anhand dessen die Entscheidungsgüte bewertet werden kann. Nur so ist ein gezieltes Experimentieren möglich.
- Außerdem sind fachliche Entscheidungen mit relevanten wirtschaftlichen Effekten interessanter als technischer orientierte DMN-Tabellen, die eher einer Look-up-Tabelle gleichen.
- ...
In der zweiten Prozessstufe wird der eigentliche kontinuierliche Verbesserungsprozess durchgeführt. Wie bereits angeschnitten, wird hier ein experimenteller Ansatz verfolgt. Der Prozess ist daher angelehnt an ein Modell zum kontinuierlichen Durchführen von Experimenten (vgl. Fagerholm et al. (2017)).
Dieser lässt sich in die drei Phasen Build, Measure und Learn unterteilen, die nacheinander durchlaufen werden und zusammen einen vollständigen Zyklus des kontinuierlich wiederholten Prozesses beschreiben.
Während der Build-Phase wird ein Experiment geplant und definiert. Zunächst werden die Situation und Verbesserungspotenziale analysiert, und festgelegt, welches Ziel mit einem Experiment erreicht werden soll (und wie wir dies messen möchten). Anschließend werden die Eigenschaften des Experiments festgelegt, dazu gehören u.a. Dauer und Zeitraum des Experiments, sowie die Stichprobengröße (d.h. Anzahl der Fälle bzw. Prozessinstanzen) und die Sampling-Strategie (z.B. randomisiert).
Kern der Build-Phase ist die Definition verschiedener Varianten einer DMN-Tabelle. Um eine Verbesserung der DMN-Tabellen zu erzielen, müssen mehrere Varianten einer DMN-Tabelle evolutionär „gegeneinander antreten". Hier könnten bspw. Schwellwerte für manuelle Prüfungen o.ä. sich etwas verändern, um deren Einfluss auf Zielgrößen zu optimieren. Diese Experimente sind nötig, da das Ableiten von Verbesserungen aus historischen Daten oft nicht verlässlich möglich ist. Dies liegt am Bias bzw. der Verzerrung durch die genutzten DMN-Tabellen – oft bestimmen Regeln nicht nur das Verhalten eines Prozesses, sondern dadurch auch, in welchen Fällen Daten gesammelt werden und in welchen nicht bzw. ob Regeln angewendet werden – es mangelt an Zufall!
In der Measure-Phase wird ein vorher definiertes Experiment durchgeführt. Bei jeder Entscheidung innerhalb einer Prozessinstanz wird hierbei basierend auf der Sampling-Strategie bestimmt, mit welcher Variante einer DMN-Tabelle diese getroffen werden soll. Zur Kontrolle des Risikos von unvorhergesehen Folgen eines Experiments oder bei nötigen Reaktionen auf äußere Einflüsse hat der Anwender in dieser Phase die Möglichkeit zum Eingreifen, d.h. das Experiment abzubrechen oder zu pausieren.
Ein wichtiges Steuerungsinstrument und Diskussionspunkt zwischen Analysten und Process-Ownern:innen ist hier das Experimental-Budget: Wir begrenzen, wie viele Prozessinstanzen die veränderten DMN-Tabellen nutzen werden, um gezielt Risiken zu begrenzen – ähnlich einem A/B-Test, aber über mehrere Stufen hinweg. Zur Realisierung der Measure-Phase wurde ein Tool entwickelt, das im nächsten Abschnitt vorgestellt wird.
Während der abschließenden Learn-Phase werden die Ergebnisse des durchgeführten Experiments analysiert und interpretiert. Aus den gezogenen Schlüssen werden dann Änderungen der DMN-Tabelle realisiert, indem z.B. die vorher hinterlegte DMN-Tabelle mit der am besten abschneidenden Variante ersetzt wird. Das wiederholte Durchführen des Prozesses führt schließlich zu kontinuierlich besser werdenden Regeln und damit Entscheidungen. Abschließend sollten die Ergebnisse und Folgen des Experiments noch dokumentiert werden, um so auch dauerhaft Wissen aufbauen zu können.
Experimentierwerkzeuge auf Camunda-Basis
Um die praktische Anwendung des Verbesserungsprozesses zu ermöglichen und zu validieren, wurde prototypisch ein Tool für das kontinuierliche Durchführen solcher Experimente entwickelt. Das Tool wurde innerhalb von Camunda BPM umgesetzt und fokussiert sich, wie bereits erwähnt, auf die Measure-Phase als aufwändigste Phase.
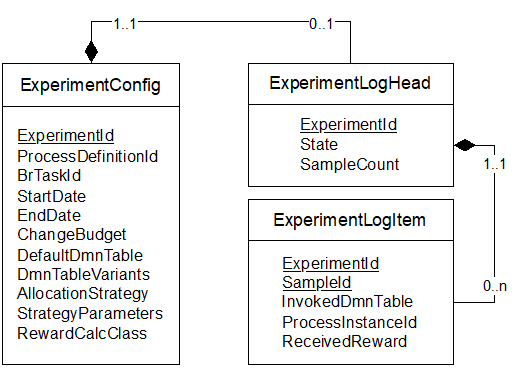
Das Datenmodell für die Experimente deckt einerseits die Konfiguration bzw. Definition der Experimente ab, und anderseits das Logging der Experimente, d.h. die getroffenen Entscheidungen der einzelnen Varianten und die Entscheidungsgüte bzw. das oben erwähnte Feedback zu einer Entscheidung: Das kann eine Kundenzufriedenheit sein oder auch die Laufzeit oder Dunkelverarbeitungsquote der umgebenden Prozesse.
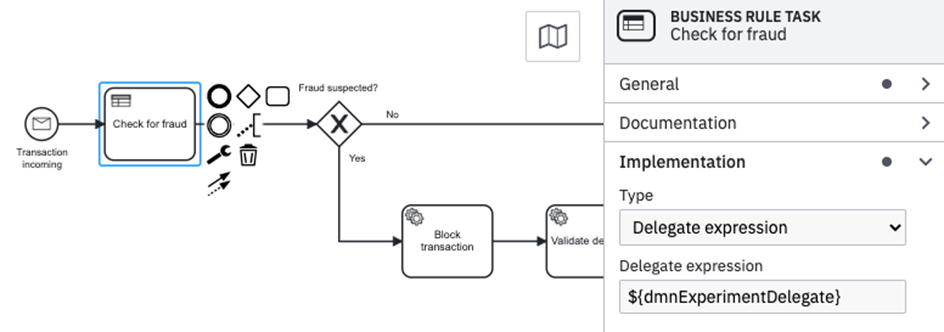
Um ein Experiment durchführen zu können, muss der Business Rule Task im entsprechenden Prozess so konfiguriert werden, dass nicht, wie üblich, direkt eine einzelne, bestimmte DMN-Tabelle aufgerufen wird. Stattdessen muss dort eine sog. Delegate expression hinterlegt werden, damit eine implementierte Spring Bean beim Durchführen der Task aufgerufen wird. Als Teil des Prototyps wurde eine Spring Bean entwickelt, die die Ausführungslogik der Experimente kapselt. Bei dem Aufruf einer Business Rule Task wird dann zunächst die Konfiguration eines Experiments geladen und basierend auf der hinterlegten Sampling-Strategie eine der definierten DMN-Tabellen Varianten ausgewählt und ausgeführt. Diese Spring Bean kann damit ohne nötige Anpassungen überall dort in Prozessmodellen hinterlegt werden, wo ein Experiment mit DMN-Tabellen durchgeführt werden soll.
Um für die nächste Prozessinstanz eine konkrete DMN-Tabelle innerhalb einer Prozessinstanz bzw. eines Business Rule Task auszuwählen, greift das Tool auf Multi-Armed Bandits als Methode zurück. Das hat den Vorteil, dass noch verschiedene Varianten dieser Algorithmus-Klasse je nach Zweck und Ziel verwendet werden können. Weil somit aus verschiedenen Sampling-Strategien gewählt werden kann, ergibt sich eine hohe Flexibilität und die Möglichkeit, die Strategie je nach Risiko-Aversion auszuwählen. Mit einem Multi-Armed Bandit kann z.B. eine vollständig zufällige Bestimmung der DMN-Tabelle realisiert werden, aber bspw. auch eine sogenannte Epsilon-Greedy Strategie, bei der nur mit einer Wahrscheinlichkeit von einem vorher gewählten Epsilon eine zufällige Variante ausgewählt wird - in den anderen Fällen die durchschnittlich am besten abschneidende Variante. Das Entscheidungs-Feedback zur Bewertung der Varianten wird bei dieser Strategie daher bereits während des Experiments benötigt: Sie eignet sich nicht für Situationen, in denen eine Entscheidung erst durch bspw. später abgefragtes Kunden-Feedback reflektiert werden kann. Idealerweise ist kurzfristiges Feedback noch innerhalb des laufenden Prozesses verfügbar oder es kann zumindest mit Prozessinstanzen korreliert werden.
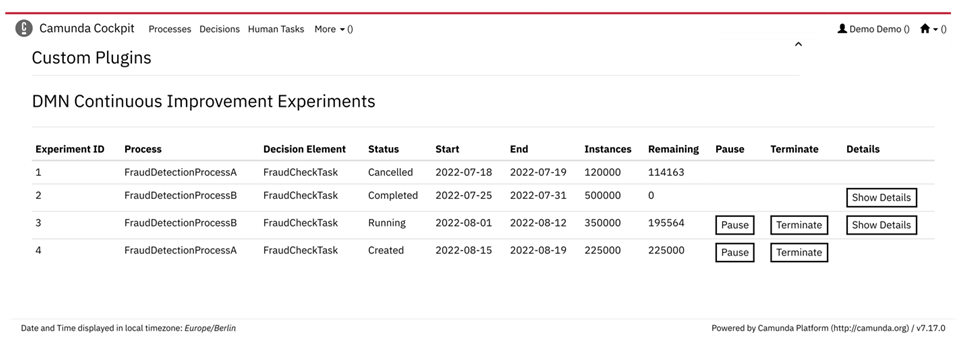
Zur Administration der Experimente wurde ein Camunda Cockpit-Plugin entwickelt, das perspektivisch auch zur Auswertung der Experimente dienen soll. Es stell eine Übersicht aller Experimente bereit, mit Informationen zum Zeitrahmen und der Anzahl der zu durchlaufenden Prozessinstanzen. Zusätzlich bietet es die Möglichkeit, Experimente vorzeitig manuell zu beenden oder zu pausieren.
Lessons Learned:
DMN-Tabellen kontinuierlich verbessern
Während der Evaluation hat sich gezeigt, dass die Wahl der Stichprobengröße je nach Strategie einen entscheidenden Einfluss auf die gewonnenen Erkenntnisse eines Experiments hat. Je näher die Werte einer variierten Zelle sich in den verschiedenen Varianten beieinander liegen, desto mehr Prozessinstanzen müssen außerdem durchlaufen werden, um ein signifikantes Ergebnis zu erhalten.
Zusammenfassend lässt sich sagen, dass Experimente mit Multi-Armed Bandits ein wirksamer Ansatz sind, um mit DMN-Tabellen getroffene Entscheidungen kontinuierlich zu verbessern. Der verwendete Ansatz ist außerdem nicht beschränkt auf DMN-Tabellen, sondern prinzipiell auch für andere Prozess-Elemente geeignet, die kontinuierlich verbessert werden sollen.
Wenn Sie DMN-basiert Entscheidungen in Geschäftsprozessen fällen und Interesse an einem Experiment oder einer Auswertung haben, sprechen Sie uns gern an!
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



