
.jpg?width=734&height=367&name=Design%20ohne%20Titel%20(86).jpg)
Viele Unternehmen verfolgen das Ziel, Daten zentralisiert zu speichern und zu managen. Traditionell erfolgte die zentrale Datenintegration in einem Data Warehouse. Wächst die Mengen an semi- und unstrukturierten Daten werden Data Lakes geschaffen oder ein Lakehouse, um die verschiedenen Arten von Daten wieder in einer Plattform zu integrieren. Mehr und mehr Unternehmen stellen dabei fest, dass trotz ausgeklügelter technologischer Lösungen die Daten nicht in der gewünschten Zeit und in der gewünschten Form den einzelnen Abteilungen bereitstehen. An dieser Stelle tritt das Prinzip des Data Mesh in Erscheinung. Es stellt im Gegensatz zu Data Lake oder Lakehouse keineswegs eine weitere technologische Lösung dar, sondern viel mehr ein Organisationsprinzip für analytische Daten.
Wie kann dieses Organisationsprinzip in der Praxis umgesetzt werden und welche Tools können die Umsetzung unterstützen? In diesem Blogartikel betrachten wir die Umsetzung eines Data Mesh mithilfe von Snowflake.
Von der zentralen Datenverwaltung zum Data Mesh
Um das Prinzip Data Mesh besser zu verstehen, müssen wir zunächst feststellen, was die Probleme einer zentralisierten Datenspeicherung sind. Das zentrale Datenteam verwaltet die Datenflüsse des Unternehmens, lenkt sie in die richtigen Bahnen und formt die Daten nach einem einheitlichen Prinzip. Das Produkt ist ein Data Warehouse (oder Data Lake / Lakehouse), das weitestgehend standardisiert ist und auf das alle Abteilungen des Unternehmens zugreifen. In einer sich nicht verändernden Unternehmenswelt wäre dieses Produkt irgendwann fertig modelliert und alle Abteilungen könnten sich am Buffet aus Daten bedienen. Tatsächlich verändern sich aber nicht nur die Anforderungen der einzelnen Abteilungen, sondern auch die Quellsysteme und die Daten selbst. Schnell kommt das zentrale Datenteam an seine Kapazitätsgrenzen. Die Themen werden also priorisiert und nacheinander abgearbeitet. Während das zentrale Datenteam nach und nach an den Themen arbeitet, werden weitere Anforderungen gestellt und diese zwischen die vorhandenen Themen priorisiert – der Backlog wächst und wächst. Dieser Prozess besitzt folgende Probleme:
- Anwender:innen warten lange auf ihre Anforderungen und werden dadurch in ihrer Arbeit eingeschränkt
- Anwender:innen stellen keine neuen Anforderungen aufgrund von langen Wartezeiten -> Innovation und Beteiligungswille von Mitarbeiter:innen sinken
- Das zentralen Datenteam ist frustriert über den langen Backlog, der scheinbar nie kleiner wird
- Priorisierung der Projekte des zentralen Datenteams erfolgt meist durch externen Einfluss und nicht durch das Team selbst -> Selbstbestimmung und Selbstorganisation im Team werden eingeschränkt
- Innovationsthemen werden häufig hinter den Themen, die das Tagesgeschäft des Unternehmens betreffen, priorisiert
Verfolgt man das Prinzip Data Mesh, wird das zentrale Datenteam zum Teil aufgelöst und die Organisation erfolgt in Domainteams. Das zentrale Datenteam verantwortet zukünftig die Bereitstellung der Plattform sowie die Grundfunktionen für die Domainteams. Je nach Fähigkeit und persönlicher Präferenz wechseln Mitarbeiter:innen des zentralen Datenteams in die Domainteams, um dort mit technischer Expertise zu unterstützen. Hier wird bewusst von Domainteams gesprochen und nicht von Abteilungen, da nicht alle Abteilungen ein Domainteam bilden und ein Domainteam nicht nur Aufgaben einer Abteilung erfüllt.
Domain-driven Ownership
Ein Domainteam ist ein autonomes Team, welches seine Aufgaben und Arbeitsabläufe selbst verwaltet. Das Team übernimmt die Verantwortung für die eigenen Daten, indem sie den gesamten Prozess von der Extraktion der Daten aus der Datenquelle bis hin zur Bereitstellung von Data Analytics und Data Science Produkten übernehmen. Neue Datenquellen können erschlossen und die Datenpipelines erstellt werden, die aus Sicht des Domainteams benötigt werden. Es entfällt die Wartezeit darauf, dass ein zentrales Datenteam freie Kapazität für diese Tätigkeiten hat, sodass die Domainteams selbst priorisieren können, wann welche Aufgaben erledigt werden sollen. Die Domainteams sollen zwar autonom arbeiten und auch eigene Entscheidungen bezüglich der eingesetzten Technologien treffen können, dabei muss aber auch der laufende Betrieb und die Berücksichtigung von Governance- und Sicherheitsaspekten berücksichtigt werden. Daher ist es nicht erstrebenswert, dass jedes Team eine eigene Plattform nutzt. Hilfreich sind hingegen gemeinsame technische Plattformen, die eine logische Trennung bieten. Snowflake erfüllt diese Anforderungen und kann somit eine zentrale Plattform für verteilte Teams sein.
In Snowflake kann die Arbeit der einzelnen Domainteams sowohl innerhalb eines Snowflake Accounts organisiert werden oder jedes Domainteam nutzt einen eigenen Account. Der Austausch zwischen den Teams erfolgt mithilfe von Snowflakes Data Sharing Möglichkeiten. Im Folgenden wird die Arbeitsorganisation innerhalb eines Accounts betrachtet.
Der Aufbau von Snowflake lässt es zu, dass jedes Domainteam eine eigene Database innerhalb des Accounts hat. Jede Database beinhaltet wiederum ein oder mehrere Schemata und diese Schemata beinhalten wiederum Tabellen, Views und andere Objekte.
.jpg?width=730&height=365&name=Design%20ohne%20Titel%20(89).jpg)
Die Domainteams können somit völlig unabhängig voneinander ihre Arbeit organisieren. Ein Snowflake Warehouse, welches die virtuellen Maschinen bereitstellt, kann je Domainteam angelegt werden oder Domainteams teilen sich virtuelle Maschinen, die idealerweise als Multicluster Maschinen aufgesetzt werden, damit bei parallelen Anforderungen in die Breite skaliert werden kann. Durch das Nutzen von eigenen Ressourcen je Domainteam können nicht nur Kosten genauer attribuiert werden, sondern auch die Kapazitäten an das jeweilige Produkt angepasst werden. Ein Data Science Produkt wird in den meisten Fällen eine größere virtuelle Maschine benötigen, als ein Analytics Projekt. Den Bedarf an Rechenleistung und Parallelität sollte man daher bei der Auswahl der virtuellen Maschine berücksichtigen. Darüber hinaus bietet das umfangreiche Rollen- und Rechtesystem von Snowflake, dass User anderer Domainteams Zugriff auf die Daten eines anderen Domainteams erhalten (z.B. nur Leserechte), ohne dass sie beabsichtigt oder unbeabsichtigt Änderungen an dem Produkt vornehmen können. Dadurch wird Data Sharing erleichtert und Redundanzen zwischen den Teams reduziert.
Eine Beispielhafte Organisation von mehreren Domainteams soll die folgende Abbildung skizzieren:
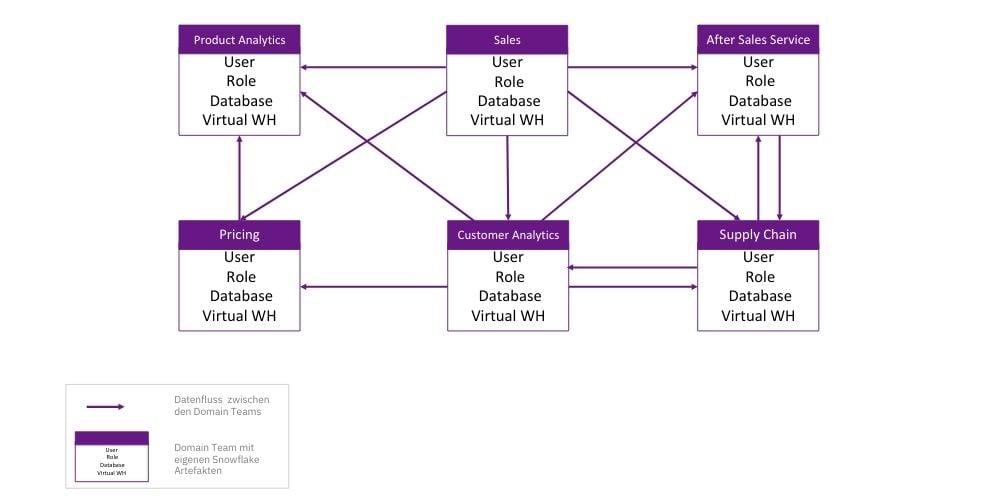
Das Thema Mandantentrennung in Snowflake und ein Vergleich zu Azure Synapse wurde bereits in einem vorherigen Blogartikel beleuchtet, diesen finden Sie hier:

Data as a product
Die Grundlage dafür, dass die Domainteams ein Datenprodukt im Sinne von Data Mesh erstellen können, liegt darin, dass jedes Datenprodukt ein Architektur Quantum [en: architecture quantum] besitzt. Damit ist gemeint, dass ein Datenprodukt alle notwendigen Komponenten, die es benötigt, um es nutzen zu können, selbst besitzt und die Möglichkeit hat, die Daten sicher mit anderen zu teilen.
Die Tätigkeiten innerhalb des Domainteams resultieren somit in einem Datenprodukt, welches andere Domainteams nutzen können. Dies können beispielsweise Views und Tabellen innerhalb von Snowflake sein, die anderen Domainteams zur Verfügung stehen, aber auch Dashboards und Reports, die mithilfe von Reportinglösungen auf Snowflake aufsetzen. Auch Data Science Modelle und Machine Learning Algorithmen sind Produkte im Sinne von Data Mesh. Durch das Produktdenken gibt es nicht nur klare Verantwortlichkeiten, sondern auch Ansprechpartner:innen zu den einzelnen Produkten. Abnehmer:innen der Produkte können mit dem Domainteam Anforderungen festlegen, die in SLAs (Service Level Agreements) dokumentiert werden. Die zuvor häufig nur verbal kommunizierten Vereinbarungen an das Produkt werden so überprüfbar und es können Maßnahmen festgelegt werden, falls ein Produkt dem Service Level nicht entspricht.
Self-Serve Infrastruktur as a platform
Die Self-Service Infrastruktur ist dazu da, die Reibungspunkte zwischen den einzelnen Produkten zu minimieren. Die Prozesse und Aufwände, die alle Produktteams betreffen, werden verallgemeinert und dadurch die Komplexität und der Arbeitsaufwand der einzelnen Domainteams reduziert. Die Plattform regelt nicht nur den Zugang zu anderen Datenprodukten innerhalb des Data Mesh, sondern auch den Zugang zu operativen Systemen. Außerdem wird der Produkt-Lebenszyklus der einzelnen Datenprodukte verwaltet.
Die Plattform benötigt daher eine zentrale Lösung zur Orchestrierung der Pipelines und eine zentrale Monitoring Lösung. Zur Orchestrierung ist Snowflake nicht die ideale Lösung, da die Pipelines in Snowflake über Tasks und Tasktrees gesteuert werden, die schnell unübersichtlich werden. Ein separates Tool bietet sich hier an, wie beispielsweise Airflow. Dennoch ist es denkbar, dass die Datenprodukte in Snowflake anderen Domainteams zur Verfügung gestellt werden. In diesem Fall würde Snowflake, im Sinne von Data Mesh, sowohl die Plattform darstellen, mit der Produkte entwickelt werden, als auch die Plattform, mit der Datenprodukte geteilt werden. Die Organisation im Data Mesh beinhaltet also durchaus mehrere technische Komponenten. Um die Plattform zu ergänzen, bieten sich Clouddienste wie Azure Synapse Analytics durch ihre Flexibilität an. Auch Komponenten zum Datenaustausch wie Airbyte können sinnvolle Ergänzungen der Data Mesh Plattform sein.
Grundsätzlich besteht ein Konflikt zwischen übergreifenden Pipelines und kleinen, produktindividuellen Pipelines. Dieser sollte im Zweifel zu Gunsten der produktindividuellen Pipelines entschieden werden, damit die Domain-Teams so unabhängig wie möglich voneinander agieren können.
Federated computational Governance
Ein Cross-Produkt-Team bildet dieses domainübergreifende Team und gibt die Akzeptanzkriterien eines Datenprodukts vor. Dazu zählen Qualitäts-, Struktur-, Dokumentation- aber auch Sicherheitsaspekte. Aus diesem Grund wird dieses Team nicht nur von Mitgliedern der verschiedenen Domainteams zusammengesetzt, sondern gegebenenfalls durch weitere Mitglieder (z.B. Legal) erweitert.
Wichtig ist, dass das Governance Team nicht dafür da ist, manuell einzugreifen oder komplexe Validierungsprozesse durchzuführen. Viel mehr wird die Verantwortung, qualitativ hochwertige Datenprodukte zu modellieren an die individuellen Domainteams delegiert und die Überprüfung dieser Vorgabe durch Automatisierung erreicht. Die operative Arbeit des Governance Teams soll so gering wie möglich gehalten werden.
Diese Komponente von Data Mesh wird stark von der Organisation selbst getragen. Snowflake kann dies unterstützen durch sein Rollen- und Rechtesystem. Mit diesem erhalten Mitglieder des Governance Teams Zugriff auf die Produkte, um Akzeptanzkriterien zu überprüfen, ohne dass sie Änderungsrechte erhalten. Durch Object Tagging können Akzeptanzkriterien überprüft werden aber auch Zugriffe und Ressourcenverbrauch überwacht werden. Bei besonders sensiblen Daten kann durch Snowflakes Secure Views oder Data Masking sichergestellt werden, dass keine Inhalte einsehbar sind. Auch User Defined Functions bieten eine Möglichkeit, Akzeptanzkriterien automatisiert zu überprüfen.
Fazit
Snowflake kann die Organisation eines Data Mesh sehr gut unterstützen. Insbesondere die Abgrenzung der einzelnen Produkte gelingt mit Snowflake sehr gut. Durch die vielen Möglichkeiten mit anderen Tools zu interagieren, eignet sich Snowflake auch hervorragend, wenn nicht alle Domainteams Snowflake nutzen. Die Flexibilität von Snowflake ermöglicht den Domainteams ihre Produkte autonom zu gestalten und Ressourcen effizient einzusetzen, da immer nur der tatsächliche Verbrauch Kosten verursacht und keine Ressourcen vorbehalten werden müssen. Dennoch ist die reine Nutzung von Snowflake nicht die Lösung aller bisheriger Probleme in einem zentralen Datenteam. Damit aus dem zentralen Datenteam ein Data Mesh wird, bedarf es mehr als nur ein zusätzliches Tool. Da es sich bei Data Mesh um ein Organisationsprinzip handelt, muss ein Umdenken in den Abläufen stattfinden und die Domainteams befähigt werden, autonom zu arbeiten. Neben der Bereitstellung der richtigen Tools und Systeme ist ein wichtiger Faktor zum Erfolg einer Data Mesh Organisation, dass die Teams zur Übernahme von Verantwortung gegenüber ihrem Datenprodukt befähigt werden und außerdem das passende Wissen innerhalb der Domainteams zur Verfügung stehen, damit keine Abhängigkeiten zu anderen Teams entstehen.
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



