
Im Data Warehouse Umfeld gibt es viele gute Softwarewerkzeuge, die beim Aufbereiten, Analysieren und Integrieren von Daten unterstützen. Wer auf diese oftmals teuren Produkte verzichten möchte und seine Daten in einer relationalen Datenbank vorhält, kann mit SQL die Aufgaben meist ebenso gut erledigen. Vor allem die kommerziellen Datenbanksysteme von Microsoft und Oracle, aber auch die OpenSource-Alternative Postgres, verfügen über mächtige Sprachkonstrukte, die teils im SQL Sprachstandard definiert sind oder ihn erweitern. Teil 1 dieser Artikelserie stellt die Operatoren PIVOT und UNPIVOT vor und zeigt, wie sich damit Datenintegration realisieren lässt.
Datenaufbereitung, Strukturierung und Transformation
Ein Data-Warehouse integriert heterogene und verteilte Datenquellen in ein gemeinsames Datenmodell. Um neue Daten in dieses Modell zu integrieren, müssen Maßnahmen zur Datenaufbereitung und Transformation durchgeführt werden.
Das Vertauschen von Zeilen und Spalten ist eine Möglichkeit, Daten in eine grundlegend andere Struktur zu bringen. Oracle und Microsoft bieten in ihren kommerziellen Datenbanksystemen mit PIVOT und UNPIVOT komfortable Operatoren an. Postgres unterstützt nur das Pivotieren mit der crosstab-Funktion. DB2 und MySQL fehlen diese Operatoren und Funktionen.
UNPIVOT
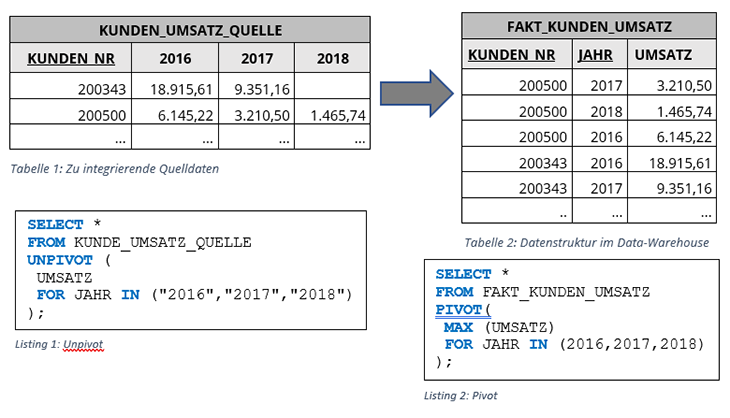
Mit einem UNPIVOT lassen sich Spalten in Zeilen transponieren. Breite Datenbanktabellen, mit vielen Spalten, können so in eine Key-Value-ähnliche Struktur überführt werden, wie nachfolgendes Beispiel zeigt. Dort werden die Kundenumsatzdaten aus Tabelle 1 in ein Data-Warehouse integriert. Das UNPIVOT aus Listing 1 liefert eine flache Datenstruktur, die mit der Tabelle 2 FAKT_KUNDEN_UMSATZ übereinstimmt und eine einfache Integration, z.B. über ein INSERT, ermöglicht.
PIVOT
Ebenso gut ist es möglich, mit dem PIVOT in Listing 2, Zeilen in Spalten zu transponieren. Die FAKT_KUNDEN_UMSATZ aus Tabelle 2 könnte somit in die Datenstruktur der KUNDEN_UMSATZ_QUELLE überführt werden.
Die PIVOT Funktion berechnet vor dem Transponieren eine Aggregation durch implizite Gruppierung aller Spalten, die nicht aggregiert werden. Darin liegt auch begründet, warum UNPIVOT im Allgemeinen keine Umkehrfunktion von PIVOT ist. Das Beispiel in Tabelle 3 und Tabelle 4 soll dies verdeutlichen. PIVOT erzeugt nicht nur eine neue Datenstruktur, sondern führt mit der Aggregatfunktion COUNT auch eine Auswertung durch, indem es Zeilen gruppiert.
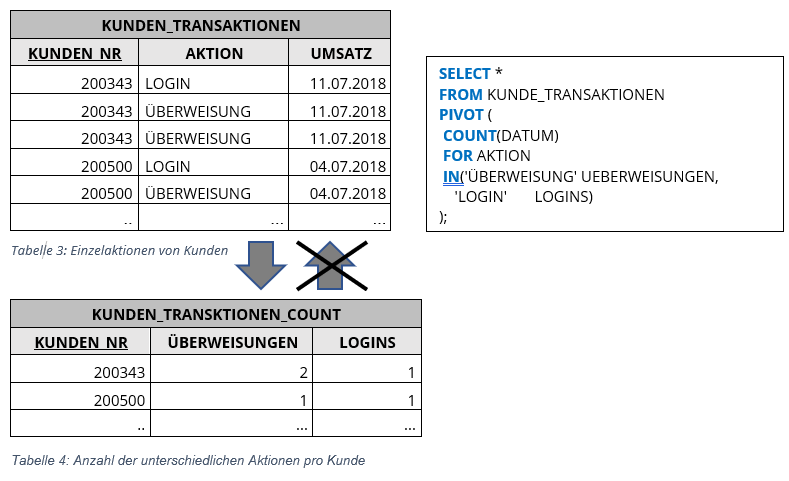
Der PIVOT Operator eignet sich meist bei Key-Value-ähnlichen Strukturen. Bei Anwendung muss allerdings der Wertebereich der Key-Spalte bekannt sein oder vorher eingegrenzt werden, da dieser die IN-Clause bildet. Bei schwankenden Wertebereichen ist es auch möglich mit dynamischen SQL (z. B. PL/SQL) das PIVOT Statement zu bilden. Dies kann unter Umständen zu Problemen führen, wenn der PIVOT Operator mehr Spalten erzeugt, als die Datenbank maximal handhaben kann – Oracle 11 und 12 können maximal 1000 Spalten in einer Tabelle darstellen.
Pivotieren in anderen Datenbanksystemen
Wie bereits erwähnt unterstützen nicht alle Datenbanksysteme PIVOT und UNPIVOT. Jedoch können diese Operatoren mit ANSI-SQL nachgebildet werden. Die Pivotierung der Tabelle 3 lässt sich z. B. umschreiben in:

Analoges gilt für UNPIVOT. Hier erfolgt die Realisierung mit UNION. Am Beispiel für Tabelle 1 ergibt sich daraus:

Sie schreiben selbst SQL-Transformationen? Sie möchten Ihre Abfragen übersichtlicher und gleichzeitig performanter schreiben?
Dann sind erweiterte SQL-Funktionen genau das Richtige für Sie. Mit ihnen können Sie SQL-Code verständlicher und performanter gestalten und so mit wenigen Zeilen Probleme lösen, für die sonst mehrere Seiten lange Abfragen nötig wären.
Erfahren Sie mehr dazu im Seminar Analytisches SQL für Business Intelligence.

Mehr Performance
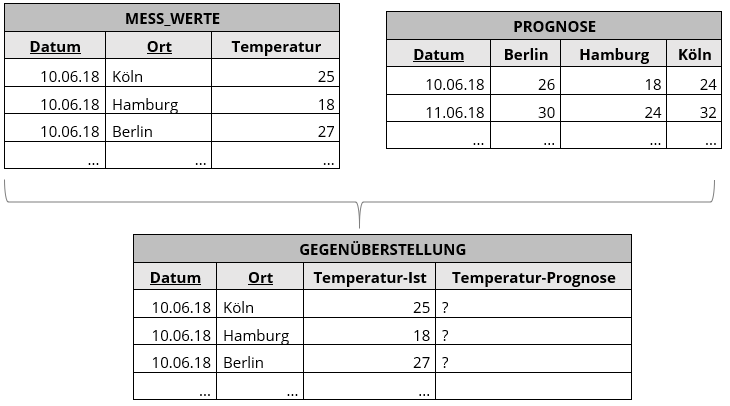
Das Vertauschen von Zeilen und Spalten kann eine effiziente Datenverarbeitung fördern, vor allem dann, wenn durch diesen Vorgang JOINS mit anderen Tabellen möglich werden. Als Beispiel soll nachfolgend das Wetter dienen. In der Tabelle MESS_WERTE befinden sich die tatsächlich gemessenen Höchsttemperaturen der Städte Berlin, Hamburg und Köln an verschiedenen Tagen. Die prognostizierten Höchsttemperaturen stehen in der Tabelle PROGNOSE. Ziel ist eine Gegenüberstellung der tatsächlichen Mess- und Prognosewerte.
Leider lassen sich die Mess- und Prognosewerte nicht ohne Weiteres miteinander verknüpfen. Ein vorheriges UNPIVOT der Tabelle PROGNOSE löst das Problem jedoch. Es sorgt dafür, dass beide Tabellen miteinander verknüpft werden können. Bei großen Datenmengen kann dies einen erheblichen Performancegewinn bringen.
Fazit
Dieser Artikel zeigt, dass das Vertauschen von Zeilen und Spalten einen Beitrag zur Datenintegration leisten kann. Nutzer von Oracle und Microsoft sind leicht im Vorteil. Sie können mit PIVOT und UNPIVOT diese Aufgabe komfortabler lösen als Nutzer anderer Datenbanksysteme. Es geht aber auch mit ANSI-SQL und ohne zusätzliche Softwarewerkzeuge.
Autor
 Tobias Rafreider war Berater bei der viadee IT-Unternehmensberatung und in den Bereichen Handel, Banken und Versicherungen unterwegs. Seine Schwerpunkte liegen in der Datenbank- und Softwareentwicklung. Er ist Java Experte, Spring Boot Enthusiast und erfahren mit Oracle Datenbanken.
Tobias Rafreider war Berater bei der viadee IT-Unternehmensberatung und in den Bereichen Handel, Banken und Versicherungen unterwegs. Seine Schwerpunkte liegen in der Datenbank- und Softwareentwicklung. Er ist Java Experte, Spring Boot Enthusiast und erfahren mit Oracle Datenbanken.
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



