

Die EU-Regulatorik für KI rückt näher. Es gilt, KI- und Data Science-Projekte erklärbar und nachvollziehbar zu gestalten. Das gilt nicht nur für deren Ergebnisse, sondern auch für signifikante (zentrale) Entscheidungen während der Entwicklung. Eine Lösung könnten Data Science Decision Records sein. Wir erklären, was wir damit meinen.
Nachvollziehbare Data Science projekte?
Während Explainable AI und Kausal-Inferenzverfahren die Nachvollziehbarkeit von KI-Modellen selbst und deren Verhalten fördern können, bleibt der Entstehungsprozess dieser Modelle explorativ und schwer zu überschauen. Auf einer technischen Ebene bieten MLOps-Lösungen wie Kubeflow eine Nachvollziehbarkeit im Sinne von "Reproduzierbarkeit". Werkzeuge dieser Art bleiben aber auf einer fachlichen und architekturellen Ebene völlig unbeteiligt und lassen Fragen bewusst offen:
- Warum verwenden wir ScikitLearn oder Tensorflow?
- Warum ist dieser Hyperparameter so justiert?
- Warum löschen wir dieses Feature aus unserem Datenset?
- Wieso verwenden wir dieses personenbezogene Datum?
Im Vergleich mit typischen Software-Engineering-Projekten werden in KI- und Data Science-Projekten häufiger grundlegende Entscheidungen getroffen und wieder verworfen. Es wird mehr experimentiert und die Entscheidungen hängen auch öfter von Experimenten (und Dateninhalten) ab. Entscheidungen kommen nur schrittweise auf und müssen schrittweise bearbeitet werden.
Die Transparenz-Ziele und die kritischen Momente sind dabei ähnlich wie in der Software-Architektur: Wir möchten Monate später oder als neue Mitarbeiterin in ein Machine Learning-Projekt kommen und dann in vertretbarer Zeit herausfinden, warum eine für das Gesamtergebnis relevante Entscheidung so getroffen wurde, wie sie ist oder ob eine neue Idee doch keine neue Idee mehr ist. Im Ernstfall heißt das auch ex post nachvollziehen zu können, welche Risiken und negativen Effekte das Team wie eingeschätzt und in Kauf genommen hat.
Werden die zentralen Entscheidungen nicht dokumentiert, sind die Ergebnisse der Entscheidung meist in Code oder anderen Artefakten erkennbar, nicht jedoch die Umstände und die Begründung der Entscheidung. Ohne dieses Wissen kann eine Entscheidung nur blind akzeptiert oder blind verworfen werden. Hierdurch werden hinfällige Entscheidungen nicht hinterfragt oder noch aktuelle, teils komplexe, Umstände nicht beachtet.
Ähnlichen Anforderungen werden viele Software-Engineers und Architects durch den Ansatz Architecture-Decision-Records (ADR) gerecht.
Hier stellen sich zwei Fragen:
- Was ist das?
- Lässt sich die ADR-Idee auf Data Science-Projekte anwenden und wenn ja, wie?
Was sind Architecture Decision Records (ADR)?
ADR sind eine Art von Dokumentation für die Entscheidungen, die im Verlauf von Softwareprojekten deren Architektur ausmachen.
Die Grundprinzipien sind wie folgt:
- ADR-Dokumente sind kurze, informelle Dokumente zu relevanten Entscheidungen (nicht zu allen)
- Sie sind im Entwicklungsteam und mit deren Werkzeugen erstellt (oft als Markdown-Files im Git)
- Sie haben einen definierten Status
- Sie zeigen eine Fragestellung sowie bewertete Alternativen auf und enthalten eine begründete Entscheidung (sobald es eine gibt) und weisen explizit auf in kauf genommene Nachteile hin.
- Entscheidungen die bedeutend genug für eine ADR sind, benötigen auch Konsens im Team
Wichtig ist dabei im operativen Ablauf: Die ADR sind natürlicher Teil des Ablaufs: Entscheidungen werden in ihnen und mit ihnen nachvollziehbar getroffen und nicht ex post dort dokumentiert. Auf diese Weise tragen sie auch zu besseren Architektur-Entscheidungen bei und nicht nur zur Nachvollziehbarkeit.
Wie müssten Data Science Decision Records (DSDR) aussehen?
ADRs könnten unverändert auch für Data Science-Projekte verwendet werden, um Entscheidungen über die IT-Architektur strukturiert herbeizuführen und zu dokumentieren. Es lohnt sich aber einen Schritt darüber hinaus zu gehen:
Prinzip 1: Fokus auf die Data Science -Spezifika
Gerade die Modellarchitektur, die Datenquellen und Datenvorverarbeitung, die Parametrisierung von Algorithmen zu dokumentieren sind Aufwandstreiber und es gibt riesige Gestaltungsspielräume, in denen Teams sich orientieren müssen. Der experimentelle Charakter von vielen KI-Projekten gibt diesem Orientierungsbedarf ganz natürlich eine Baumstruktur: Eine zusätzliche Vorverarbeitung erlaubt ein neu definiertes Feature etc. - die gesamte Kette hält nur unter Vorbehalt zusammen, denn vielleicht brauchen wir die neue Vorverarbeitung doch nicht?
Wir können diese Argumentation als eine Serie von Data Science Decisions Records (DSDR) darstellen, die sich als Markdown-Files in Git Branches entwickeln und verzweigen.

Es entsteht ein digitales Data Science Laborbuch, mit das Reifen des Projektes von einem Proof-of-Concept bis zum Produkt nachvollziehbar wird.
Ein Data Science Projekt wird etwas mehr Decision Records enthalten als ein typisches Software-Projekt, um dem großen Gestaltungsspielraum und dem oft experimentellen Charakter von Data Science-Projekten gerecht zu werden.
Prinzip 2: Ein gemeinsames Verständnis der Bedeutsamkeit einer Data Science-Entscheidung
Damit auf diese Weise nicht beliebig viele ungeordnete Decisions Records auf unterschiedlichen Detail-Niveaus entstehen, braucht es ein gemeinsames Maß für das Level von Bedeutsamkeit, die eine Entscheidung haben sollten, um einen DSDR zu rechtfertigen. Das ist für ML-Projekte oft einfacher als im klassischen Software-Engineering, denn es geht sehr oft um eine quantifizierbare Zielgröße wie bspw. eine Accuracy, Precision und Recall oder andere Metriken wie AUC, F1-Scores etc. Das macht viele Design-Entscheidungen und Gestaltungsoptionen auch gut vergleichbar. Daher sollten diese Metriken immer wenn möglich, in DSDR auftauchen, um die Effekte von Design-Optionen zu beschreiben.
Aus den üblichen Anforderungen an Machine-Learning-Lösungen und Entwicklungsprozesse lassen sich Checklisten ableiten, um die Erstellung von DSDR zu leiten. Hier eine Definition of Relevance dazu aus einem unserer Projekte:
Eine Entscheidung sollte als DSDR getroffen und dokumentiert werden, ...
- ... wenn sie die Zielgröße(n) spürbar verändert oder das Potenzial dazu hat.
- ... wenn sie Aspekte von Fairness oder Bias in den Daten verändert.
- ... wenn sie die Art und Weise der Verarbeitung von personenbezogenen Daten sich verändert oder die Risiken der Verarbeitung von personenbezogenen Daten.
- ... wenn sie technische Schulden mit sich bringt ("Machine Learning is the high-interest credit card of technical debt").
- ... wenn von definierten Standards der Organisation abgewichen wird.
- ... wenn sie den vorher definierten Use Case erweitert oder einschränkt.
Prinzip 3: Wiederverwenden von Entscheidungen leicht machen
Ein Szenenwechsel: Wir beginnen das zweite Machine Learning-Projekt, nachdem das erste erfolgreich in Betrieb ist. Können wir die DSDR eines Projektes für ein zweites Projekt anwenden?
Das ist ein verlockender Gedanke, denn ML-Projekte neigen zu technischer Vielfalt, die es einzufangen gilt, um die Wartbarkeit mit einem stabil großen Team leisten zu können und den Anforderungen der IT-Security gerecht zu werden. Andererseits wird ein zweites Projekt andere Datenstrukturen verwenden und andere Zielgrößen anstreben, was vielen Begründungen von Entscheidungen aus dem ersten Projekt ohne Basis dastehen lässt. Machine Learning-Projekte brauchen auch ein Maß an Freiheit, um überhaupt erfolgreich sein zu können.
Wir empfehlen daher ein zweites Projekt mit einem Fork bestehender DSDR zu beginnen. Geht es um viele Projekte, lohnt es sich eine Checkliste mit Design-Entscheidungen abzuleiten, die ein jedes neues ML-Projekt sicher wird treffen müssen.
- Die Entscheidung über den angestrebten Use-Case und die Ziel-Metriken
- Die Entscheidung über einen geeigneten Benchmark für die ML-Lösung
- Die Entscheidung über die verwendeten Datenquellen
- Die Entscheidung über die verwendete Infrastruktur, Tooling und Bibliotheken
- Die Entscheidung über verwendete ML-Methoden
- Die Entscheidung über den Umgang mit Anomalien und Ausreißer-Datenpunkten
- Die Entscheidung über den Umgang mit fehlenden Daten (Missing Data)
- Die Entscheidung über die Einordnung des Systems in eine Risiko-Kategorie
- Die Entscheidung über eine QS-Freigabe und Deployment-Lösung
- Die Entscheidung über die Gestaltung einer Monitoring-Lösung
- ...
Auf diese Weise können wir die technische Homogenität von ML-Projekten fördern und machen notwendige Abweichungen leicht erkennbar.
Prinzip 4: Zusatznutzen aus DSDR-Vernetzung gewinnen
Entscheidungen können sich aufeinander beziehen. Auch das ist mit Markdown-Files durch Verlinkung zu den bestehenden Dokumenten sehr einfach abbildbar und auf Plattformen wie Github oder Gitlab entsteht daraus eine leicht navigierbare Struktur - auch für Menschen, die nicht aktiv im Projektgeschehen involviert sind.
Diese einfache Technik können wir zusätzlich nutzen, um einen Gesamtüberblick zu erzeugen: Eine übergreifende Markdown-Datei enthält vielleicht einige Kategorien, die Phasen des CRISP-ML(Q)-Zyklus oder die Kategorien des Google ML Test Scores und verlinkt dort auf die Entscheidungen, die zu diesen Bereichen passen.
Ein deutlicher Zusatznutzen entsteht dann, wenn Entscheidungen ohnehin datenabhängig getroffen werden und wir bspw. ein für die Daten geeignetes Verfahren wählen möchten. Vermutlich wird dies eine Datenanalyse notwendig machen und vermutlich wird diese in einem Python/R/Julia/Quarto-Notebook getroffen, das ohnehin Markdown-Syntax verwendet und im gleichen Versionskontrollsystem beheimatet ist: Warum sollte nicht das verwendete Notebook als DSDR verwendet werden? Das hat den nachhaltigen Effekt, dass zu einem späteren Zeitpunkt nicht nur exakt erkennbar ist, wie die Entscheidung entstand. Wir können darüber hinaus die Entscheidung auf neuen Datensituationen leicht hinterfragen.
Der Ansatz entwickelt sein volles Potenzial im Zusammenspiel mit Cloud-basierten ML-Ops-Plattformen wie bspw. Kubeflow. Hier sind nicht nur Notebooks ausführbar (im Anschluss an die Idee Notebook als DSDR) sondern auch die Ausführungsumgebungen und die Ergebnisse von Experimenten, Hyper-Parameter-Tunings können erhalten werden und besitzen eine eindeutige URL. Auf Wunsch kann auch das verwendete Datenset erhalten bleiben, auf dem eine Analyse lief. Es wird also (solange der Speicherplatz reicht) ein Decision Drill Down möglich:
- "Wir haben uns für diese Methode entschieden, weil sie unsere Zielvariable deutlich verbessert im Vergleich zu den Alternativen."
- "Die Analyse dafür erfolgt so: ... [Link aus dem DSDR auf ein Jupyter-Notebook im gleichen Projekt]"
- "Das Ergebnis der Analyse ist wie folgt: ... [Link aus dem DSDR auf das Analyse-Ergebnis im Kubeflow]
- "Die Rohdaten der Analyse waren wie folgt: ... [Link aus dem Kubeflow-Ergebnis auf die im Kubeflow protokollierten Rohdaten]
Auf diese Weise wird eine Entscheidung standfester gegenüber Vorwürfen vom Typ: "Wurde in der Analyse nicht Etwas übersehen?" - Alle Fragen dieser Art wären ex post vollständig prüfbar.
Der Markdown-Ansatz und die Decision-Drill-Down-Idee funktionieren dabei sehr interoperativ und nicht nur mit Kubeflow: Er wird mit allen Systemen funktionieren, die ML-Artefakte mit stabilen URLs für ein Data Science-Team zugreifbar machen.
Was können DSDR erreichen?
Durch Data Science Decision Records fördern wir die technische Homogenität von Data Science-Produkten. Gleichzeitig helfen wir Teams, frühzeitig an die üblichen Entscheidungen bewusst zu denken und ermöglichen ihnen, von vorbereiteten Entscheidungen zu profitieren, soweit es fachlich sinnvoll ist. Der Ansatz wird der Lebensrealität von Data Science Teams gerecht, dass sich technische und fachliche Aspekte schwer trennen lassen und macht diese nachvollziehbar und zu einer Stärke.
Damit ähneln DSDR etwas dem Model Cards-Ansatz, verzichten aber auf die dort erforderliche starke Verdichtung und den Zielgruppenwechsel aus dem Data Science-Team hinaus. DSDR sind eine Ressource des Teams für das Team selbst.
Sie erwirken aber, dass das Data Science-Team zu den regulatorisch relevanten Aspekten langfristig auskunftsfähig wird, auch wenn die Zahl der ML-Projekte steigt. Da sie nicht aggregiert oder anlassbezogen sind wie bspw. eine Datenschutzfolgenabschätzung, sondern lebende Dokumente auf dem operativem Granularitätsniveau - der Ground Truth - können höher aggregierte Dokumente effizient aus einer DSDR-Basis abgeleitet werden. Das ist besonders relevant, wenn sich die regulatorischen Anforderungen verändern oder wenn ein Team Produkte für den internationalen Markt erzeugt, in dem verschiedene "AI Acts" gleichzeitig relevant sein können.
Unsere eigenen Erfahrungen im Projekt sind positiv - im ersten Projekt mit DSDR kamen in 3 Monaten 16 Records zusammen, mit abnehmender Tendenz.
Was brauche ich, um DSDR zu nutzen?
Wichtigste Voraussetzung ist das Commitment der beteiligten Personen durch das Verständnis der genannten Zusammenhänge. Ganz operativ braucht es dann nur wenig:
- Ein Markdown-Template (Beispiel MADR, mit so vielen Elementen wie das Team als notwendig empfindet)
- Einen Prozess, durch den DSDR fließen können
- Eine "Definition of Relevance"
- Einen versionierten Ablageort
Wobei sich über die Zeit hinweg diese Prozesse und Definitionen leicht ändern können.
Über ein geeignetes Template können wir gern sprechen. Viele Ideen aus der ADR-Idee sind unverändert verwendbar. Ergebnis der Recherche nach einem geeigneten Prozess ist der folgende Vorschlag:
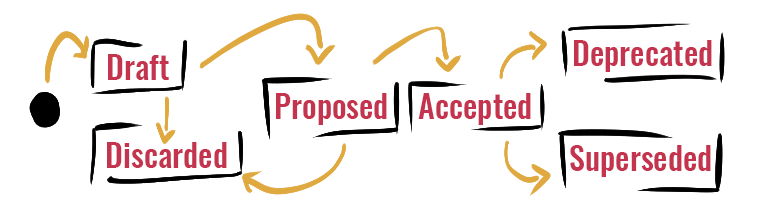
Besonders wichtig für DSDR ist uns die Unterscheidung zwischen Draft und Proposal-Status. Da der Draft-Status keinerlei weitere Annahmen macht, kann er auch als Notiz für zu treffende Entscheidungen gelten oder als geschützter Raum einer einzelnen Person, die eine Entscheidung bearbeitet. Der Proposed-Status signalisiert Gesprächsbedarf: Das Team kann - mit geeigneten Mechanismen - zu einer Entscheidung kommen (Accepted) und diese dokumentieren.
Alternativ wäre es auch denkbar, die Entscheidung zu verwerfen (Discarded), d.h. sie nicht zu treffen. Dies sollte selten sein, weil bspw. die Notwendigkeit einer Entscheidung nicht mehr gegeben ist.
Idealerweise bleiben Entscheidungen lange im Accepted-Status. Möglicherweise werden sie irgendwann hinfällig (wir haben bspw. Schutzmaßnahmen zu Daten beschlossen, die wir zukünftig nicht mehr verarbeiten) oder sie werden durch Folge-Entscheidungen ersetzt (es stellt sich bspw. heraus, dass Personenbezüge zu Daten im Einzelfall herstellbar sind und wir müssen Datenschutzmaßnahmen neu bewerten). Die beiden Status Superseded und Deprecated unterscheiden sich folglich nur darin, ob es eine Folge-Entscheidung gibt oder nicht. Das möchten wir explizit machen.
Interessiert? Sprechen wir gern darüber!
Dieser Blogpost ist entstanden auf Basis der Master-Thesis von Marvin Gronhorst an der FH-Münster, betreut von Prof. Michael Bücker. Aus der Thesis ist ebenfalls ein Vortrag auf der European Conference on Data Analysis (Neapel 2022), hervorgegangen.
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



