

In der Welt der Datenaufbereitung und -analyse gibt es ständig neue Trends und Technologien. Eine davon ist das „data build tool“ (dbt). In diesem Blog-Artikel zeigen wir, warum dbt spannend ist und welche Rolle es in der modernen Datenarchitektur einnimmt.
Das „data build tool“ (dbt) ist im Kern ein in Python geschriebenes Open Source Werkzeug zum Erstellen und Verwalten von SQL-Transformationen. dbt ist kein grafisches ETL (Extract – Transform – Load) Werkzeug, sondern folgt dem Trend zu ELT (Extract – Load – Transform).
Im Gegensatz zu ETL werden bei ELT die Daten nicht auf dem Weg ins Data Warehouse (DWH) transformiert, sondern zunächst in das DWH geladen und dort aufbereitet. Besonders bei Cloud-DWH-Lösungen wie Snowflake, Synapse Analytics, Bigquery und Redshift ist ELT zu empfehlen, um die Leistung dieser hoch skalierbaren Plattformen zu nutzen. dbt übernimmt dabei das "Transform" in ELT.
Für die Extraktion der Daten aus den Quellen und das Laden ins Data Warehouse werden andere Technologien benötigt. Zum Glück gibt es auch für diesen Zweck eine große Auswahl.
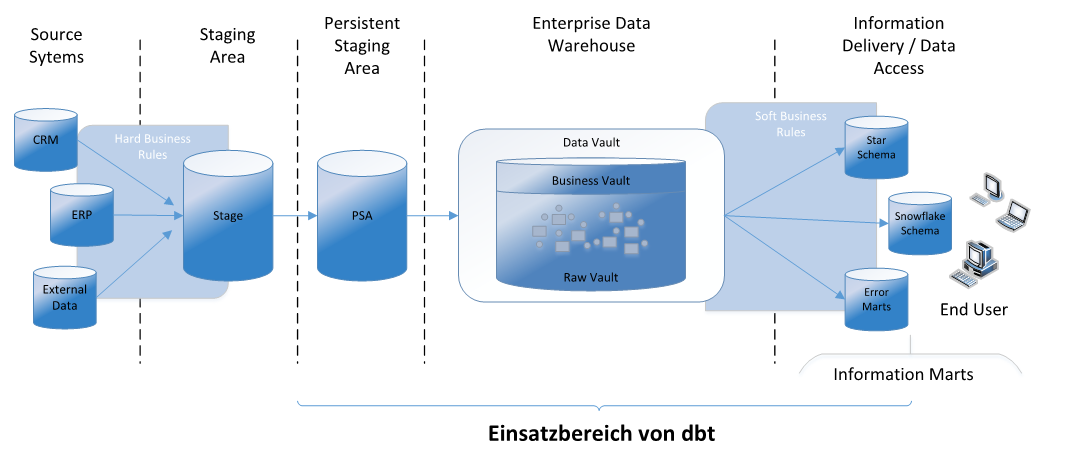
Das folgende Architekturbild zeigt den Einsatzbereich von dbt, welches in der DWH-Architektur die Transformation der Rohdaten in Zielmodelle übernimmt.
Über wie viele Schichten die Transformation erfolgt und ob die Datenstrukturen als Data Vault, Star Schema, oder auf andere Art modelliert werden, wird dabei nicht durch dbt vorgegeben, sondern ist den Entwickler:innen selbst überlassen.
Wie funktioniert dbt?
Das data build tool übernimmt die Kompilierung und Ausführung von Modellen, welche mittels SQL und der Makrosprache Jinja geschrieben werden. Jedes Modell besteht aus genau einem SQL-Statement. Jinja-Code wird bei der Kompilierung in SQL übersetzt.
Darüber hinaus enthält dbt einen Paketmanager, um vorgefertigte Pakete für unterschiedliche Aufgaben in die eigenen Projekte zu integrieren.
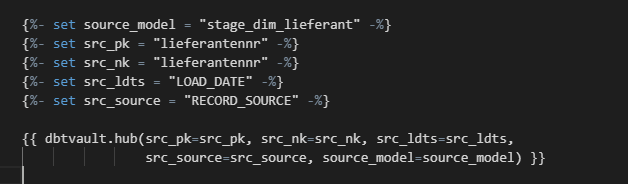
Die folgenden Ausschnitte zeigen ein einfaches Staging-Modell „stage_dim_lieferant.sql“ und ein einfaches Analyse-Modell „total_revenue.sql“:
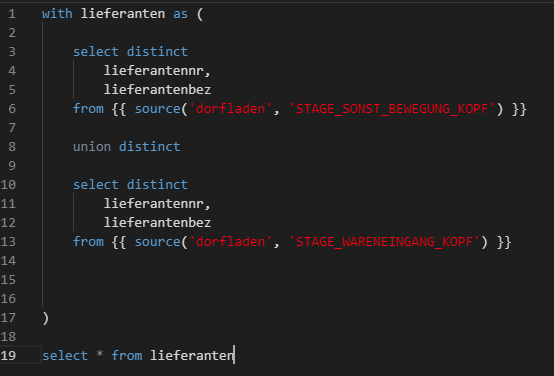

Durch die source() und ref() Funktionen versteht dbt die Beziehungen zwischen den Modellen und baut einen Abhängigkeitsgraphen auf. So kann sichergestellt werden, dass die Modelle in der korrekten Reihenfolge gebaut werden und die Data Lineage dokumentiert ist.
Der Lineage Graph kann wie folgt aussehen:
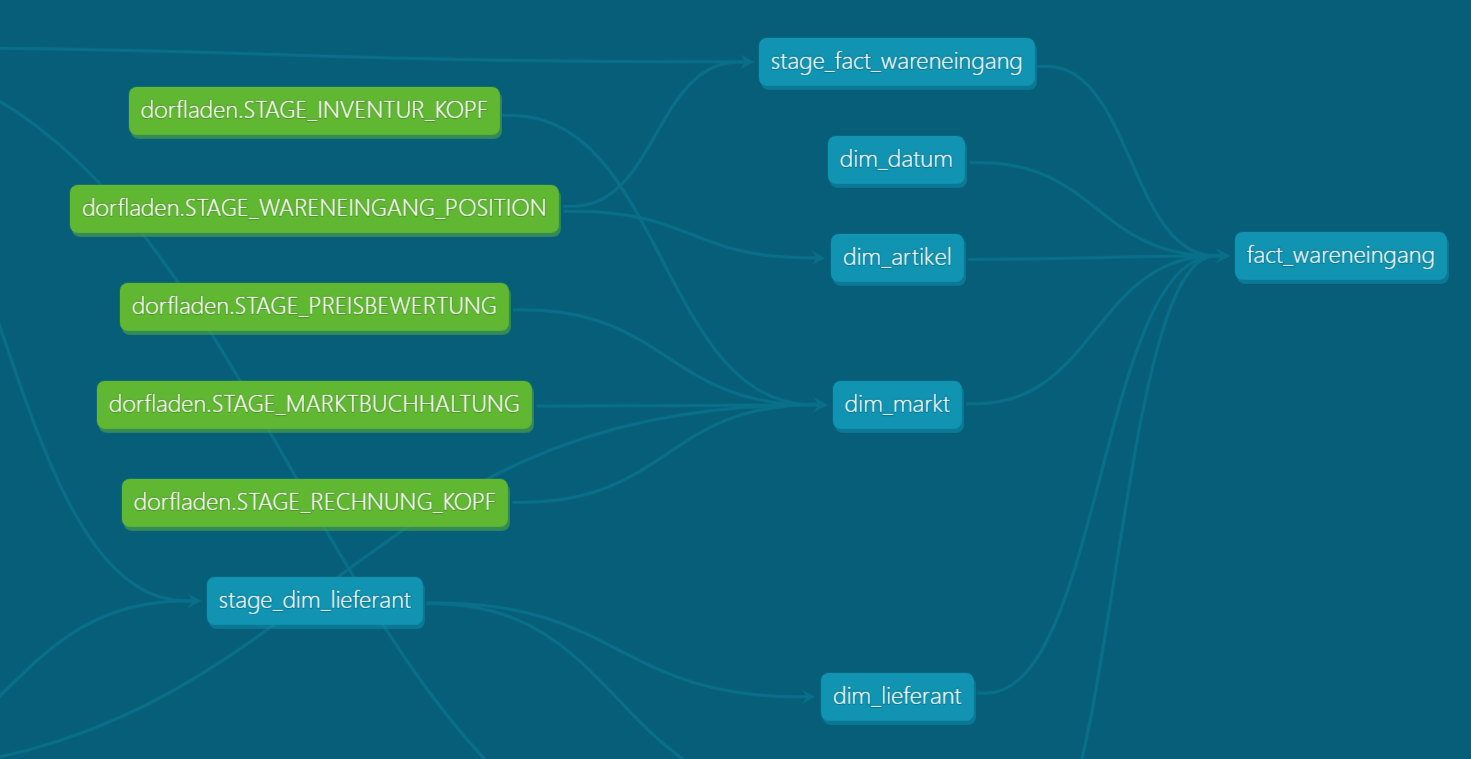
Durch die aufeinander aufbauenden Modelle ergibt sich eine Verschachtelung von Views, oder – wenn gewünscht – auch materialisierten Tabellen. Wie die Modelle materialisiert werden, kann auf verschiedenen Konfigurationsebenen festgelegt werden. Das ermöglicht ein schnelles Prototyping mit Views und eine Umschaltung zu materialisierten Tabellen, falls dies aus Performancegründen nötig ist.
Durch die Möglichkeit, Konfigurationen auf unterschiedlichen Ebenen (direkt im Modell, in der Schema.yml Definition, in der Projektdefinition, …) vorzunehmen, ist es wichtig, sich im Team auf Standards zu einigen, wann eine Option an welcher Stelle genutzt wird, damit kein Chaos entsteht und unerwartete Seiteneffekte vermieden werden.
Integration und Testen
Da Code und Konfiguration in dbt in Textdateien abgelegt werden, sind die Transformationen leicht zu versionieren und zu integrieren, z. B. mit Github zur Versionierung, Fivetran für Datentransfer oder Airflow zur Orchestrierung. Es fügt sich damit sehr gut in das aktuelle Cloud-Ökosystem ein.
Zwar kann dbt auch außerhalb der Cloud verwendet werden, aber nicht alle Module unterstützen alle Datenbanken und ihre jeweiligen SQL-Dialekte, so dass mit mehr eigenem Anpassungsbedarf zu rechnen ist. Am besten werden aktuell Snowflake, BigQuery und Redshift unterstützt.
dbt kann entweder lokal bzw. auf eigenen Servern per Command Line Interface (CLI) oder in einer kostenpflichtigen Cloud-Entwicklungsumgebung „dbt Cloud“ verwendet werden.
Neben der Erstellung von Modellen unterstützt dbt auch das Testen dieser Modelle. Dies funktioniert einerseits über die Prüfung von Constraints wie unique und not null, oder festgelegte akzeptierte Wertemengen.
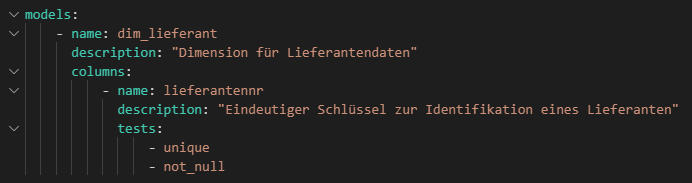
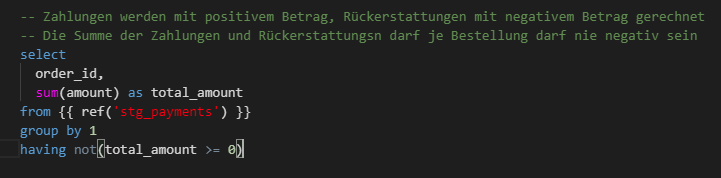
Andererseits können auch komplexere Abfragen definiert werden, z. B. um zu überprüfen, dass die Summe aller Zahlungen je Bestellung nicht negativ ist.
Ein weiterer Vorteil von dbt besteht in Funktionen, um die Ausführung auf verschiedenen Umgebungen wie Entwicklung, Test und Produktion zu steuern.
Community
Um dbt hat sich neben den Erfindern Fishtown Analytics eine aktive Community gebildet, welche zum einen Austausch ermöglicht und zum anderen auf dbthub-Erweiterungen bereitstellt. So gibt es z. B. ein Modul zur Erstellung von Data-Vault-Artefakten wie Hubs, Links und Satelliten.
Aktuell unterstützt dieses nur Snowflake als Zieldatenbank, jedoch sind die Makros Open Source und können selbst auf andere Umgebungen angepasst werden.
Die aktuell auf dbthub verfügbaren Pakete beziehen sich vor allem auf unterstützende Grundfunktionen wie Datumslogik sowie die Verarbeitung von Daten aus Cloud-Diensten wie Snowplow, Stripe, etc. Aufgrund der aktiven Community ist damit zu rechnen, dass die bisherigen Pakete weiterentwickelt und neue Pakete für unterschiedlichste Aufgaben veröffentlicht werden.
Für die Anpassung der Pakete und der darin verwendeten Makros sind wie für die Entwicklung eigener Modelle nur Kenntnisse in SQL und Jinja notwendig. Jinja ist im Zusammenspiel mit Python verbreitet und ähnelt anderen Templating-Sprachen wie Pebble oder Handlebars.
Fazit
dbt erfindet die Welt nicht neu. ELT auf Basis von SQL, sowohl als reines ANSI-SQL, als auch mit den Erweiterungen PL/SQL, T-SQL oder mit proc sql in SAS nutzen wir seit langer Zeit in diversen Projekten. Wenn gut funktionierende Prozesse für Entwicklung, Test und Deployment vorliegen, dann gibt es keinen Grund, diese mit dbt neu zu schreiben.
Wenn es hingegen darum geht, ein neues DWH auf der grünen Wiese aufzubauen – vor allem wenn sich diese in den Wolken befindet – dann bietet dbt ein sehr hilfreiches Grundgerüst, bei dem viele wichtige Funktionen für Continuous Integration und Deployment bereits definiert sind.
dbt bringt die Standards aus der Softwareentwicklung in die Welt der Datentransformation. So können sich die Entwickler:innen auf die Kernaufgaben der Datenmodellierung und Geschäftslogik konzentrieren.
Besonders, aber nicht nur für kleinere Projekte bietet dbt eine leichtgewichtige und offene Alternative zu Data-Warehouse-Automatisierungslösungen (DWA) wie Wherescape. Ähnlich wie DWA-Lösungen bietet dbt den Rahmen für eine schnelle und strukturierte DWH-Entwicklung. Dabei schreibt man tendenziell mehr Code selbst, hat so aber auch höhere Freiheitsgrade.
Dieser Artikel ist der Start einer Serie zum data build tool. Nach dieser Einführung werden wir in den folgenden Artikeln verschiedene Aspekte von dbt sowie die Integration mit anderen Business Intelligence-Tools tiefer betrachten.
Abonnieren Sie unseren Blog, um über weitere Artikel informiert zu werden!
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



