

Immer mehr Unternehmen definieren und steuern ihre Geschäftsprozesse in einem Workflow-Management-System wie Camunda. Dabei entstehen unzählige Ereignisdaten, die nach einiger Zeit aufgrund von fehlendem Speicherplatz meist einfach gelöscht werden. Damit wird jedoch viel Datenpotenzial für Analyse- und Optimierungszwecke verschenkt und Entscheidungen und Prozesse können unter Umständen im Nachhinein nicht mehr nachvollzogen werden. Der Camunda Kafka Polling Client wirkt diesem Problem entgegen. Er extrahiert die Daten kontinuierlich und legt sie in Apache Kafka ab, sodass sie langfristig für Analysezwecke zugänglich bleiben. Diese Software-Komponente ist jetzt als OpenSource-Werkzeug verfügbar.
Das Problem: Prozessdaten aus Camunda extrahieren
Jeder, der schon mal mit Workflow-Engines gearbeitet hat, weiß, dass im Betrieb Protokolldaten in einem sehr hohen Detailgrad anfallen. Dementsprechend wird auch sehr viel Speicherplatz benötigt, um die Prozessinformationen zu archivieren. Die Folge: operative Zugriffe werden träge. Relationale Camunda-Datenbanken wie beispielsweise H2, Oracle oder MySQL gelangen schnell an ihre Kapazitätsgrenze, insbesondere wenn im Ereignisprotokoll zusätzliche Daten – beispielsweise im JSON-Format – enthalten sind. Folglich stehen Unternehmen vor einer großen Herausforderung: Entweder sie löschen die Daten und gehen das Risiko ein, abgeschlossene Prozesse nicht mehr nachvollziehen zu können, oder sie müssen die Daten extrahieren und in einer hoch skalierbaren Datenbank speichern. Entscheidet man sich gegen das Löschen und für das Speichern der Protokolldaten, entsteht gleichzeitig ein unglaubliches Optimierungspotenzial für die Geschäftsprozesse des Unternehmens. Mithilfe der Daten könnten beispielsweise Flaschenhälse in den Prozessabläufen erkannt oder Prozessentscheidungen per Machine Learning automatisiert getroffen werden. Jedoch stellt sich natürlich die Frage, wie extrahiert man die Prozessdaten aus einer Workflow-Engine wie Camunda?Die Lösung: Der viadee Camunda Kafka Polling Client
Unsere Antwort darauf lautet: Mit dem Camunda Kafka Polling Client. Diese von der viadee in Java implementierte Lösung ermöglicht es, Daten aus Camunda just in time und kontinuierlich zu extrahieren und sie permanent in Apache Kafka zu speichern. Damit muss man sich über einen Informationsverlust durch regelmäßiges Housekeeping der Daten keine Sorgen mehr machen. Kafka bietet nicht nur die Möglichkeit, die ankommenden Datenströme zu verarbeiten, sondern kann zudem die enormen Datenmengen in einer hoch skalierbaren Datenbank dauerhaft ablegen. Die in Kafka gespeicherten Daten können abschließend entweder in einem Process Warehouse analysiert werden oder sie werden unter Einsatz von künstlicher Intelligenz zur Prozessoptimierung genutzt. Auch eine Anbindung an ein freies Frontend wie Elastic bzw. Kibana kommt in Frage.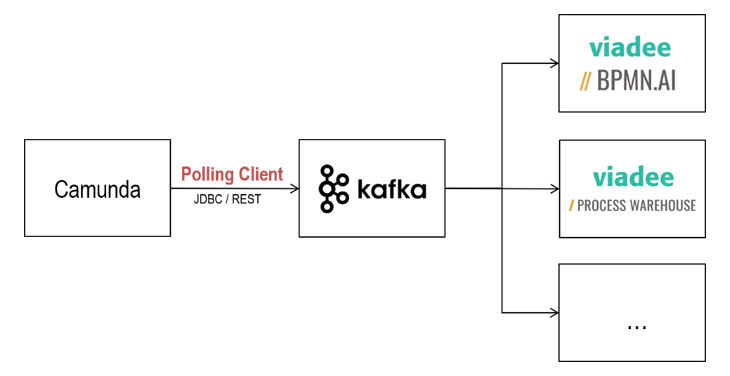
Prozesse analysieren und verbessern
Ein möglicher Verwendungszweck für die extrahierten Daten ist die Überführung in ein Process Warehouse. Das viadee Process Warehouse (vPW) ist eine Lösung zur Definition, Visualisierung und Analyse von Prozesskennzahlen direkt am Prozessmodell. Damit kann zum Beispiel der Automatisierungsgrad eines Prozesses bestimmt werden oder die Dauer der einzelnen Prozessschritte anhand des Modells kann grafisch veranschaulicht werden.Optimierungspotenziale nutzen mit Künstlicher Intelligenz
Die Daten, die in Apache Kafka mithilfe des Polling Clients gespeichert wurden, können darüber hinaus auch zur Verbesserung der Geschäftsprozesse dienen. BPMN.ai ist der Ansatz der viadee, um künstliche Intelligenz für solche Optimierungen einzusetzen. Nach einer Vorverarbeitung der Daten mithilfe von Apache Spark, liegen die Daten standardisiert und integriert vor. Diese Daten können dann direkt weiterverwendet oder aus beliebigen Datenquellen (wie z.B. einem DWH) angereichert werden, um Machine Learning-Modelle anzulernen und dadurch etwa Prozessentscheidungen in Zukunft automatisiert zu treffen. Die Event-basierte Architektur des viadee Process Warehouse erlaubt dies auch für Einzelfälle.Selbstverständlich finden die in Kafka gesammelten Daten nicht nur durch das viadee Process Warehouse oder bpmn.ai ihre Anwendung, sondern können für jegliche andere Zwecke genutzt werden.
Der viadee Kafka Polling Client steht auf GitHub als OpenSource-Projekt zur Verfügung. Außerdem stellen wir ein vorkonfiguriertes Docker-Image auf Docker-Hub bereit.
Wer sich für die Entwicklung und Anwendung des viadee Camunda Kafka Polling Client interessiert, kann sich gerne per Kommentar hier oder auf Github melden. Wir freuen uns über Interesse und Feedback.
zurück zur Blogübersicht
Diese Beiträge könnten Sie ebenfalls interessieren
Keinen Beitrag verpassen – viadee Blog abonnieren



